==========================================================================================================
写在前面:
从20201123接触ASR到现在,刚好1个月左右的时间,今天可以把ASR部分的内容写个完整的自动化测试总结贴,方便后续查阅。
1、最开始的需求是:提供3个供应商,需要对三个ASR供应商的结果进行测试,并从中选择1家性价比和识别结果比较好的引入到工作环节。
由于时间紧,任务重,可能只有1天时间就要给出结果,所以没有办法去使用自动化的形式去进行比较,所以就出来了V1.0纯手工测试和比较效果。
2、20201203又增加了两家ASR供应商,由于2个任务时间间隔有点大,而且也是一次性任务,所以第一次效果测试结束后,只是用python写了
简单的存储Excel操作,后续效果比对操作是在人工操作测试的,本次的任务也是“快急”,手头也有很多事情需要做,第2次也是人工完成,而且给出了
主观的评价分值。
3、从2次的测试结果看,都是半自动+半人工的形式,想着希望能有一种方式,能够自动的去完成ASR人工识别和测试结果,把人工给解放出来。
于是乎看了一些ASR语音转文字的评价标准和评价工具等,本来想写通过公式写一个评价算法,由于各种因素(可能比想象的要负责一些,增删改错位等)
所以最后综合考虑用HTK的HResults来实现。
所以基于此,从20201217开始,在上周搭建的python自动化测试接口框架的基础上,将读取人工结果-分析供应商ASR结果-结果转化为mlf文件-配置HResult对比-
测试结果汇总-存储Excel等信息进行完整的业务流操作进行全自动测试。
==========================================================================================================
调查和学习ASR语音转文字过程中,帮助比较多的一些信息已经汇总:
【AI模型测试】语音识别ASR的结果校对(帮助比较大)
【AI模型测试】语音转文字ASR的测试评价:HTK在windows下的配置说明
【AI模型测试】ASR语音转文字过程中遇到的问题和解决方案等
第0步:构思
1、搭建自动化测试框架
2、语音转文字的手动测试流程分析,提取自动化测试点,调查测试评价方法等
3、遇到的问题和解决方案,学习和成长
第1步:搭建自动化测试框架
既然想做接口自动化测试,那么首先手头没有自动化测试框架,所以需要搭建一个python的自动化测试框架,搜集学习网上的一些资料 ,加上自己javaUI自动化测试框架的经验借鉴。
python+logging(日志模块)+Webdriver(Pageobject页面后续用)+requests(请求模块)+HTMLReport(测试报告)+email(发送测试邮件)+ddt(Excel数据读取和写入等)+output(输出结果等)
等搭建python自动化测试框架。
通过分层分模块,来约束下各个模块下写的内容,这样方便扩展和维护等。
python的接口自动化测试框架和内容:(具体框架内容,回头有空写个自动化测试框架搭建的帖子汇总,该框架目前已经在团队里推广使用起来)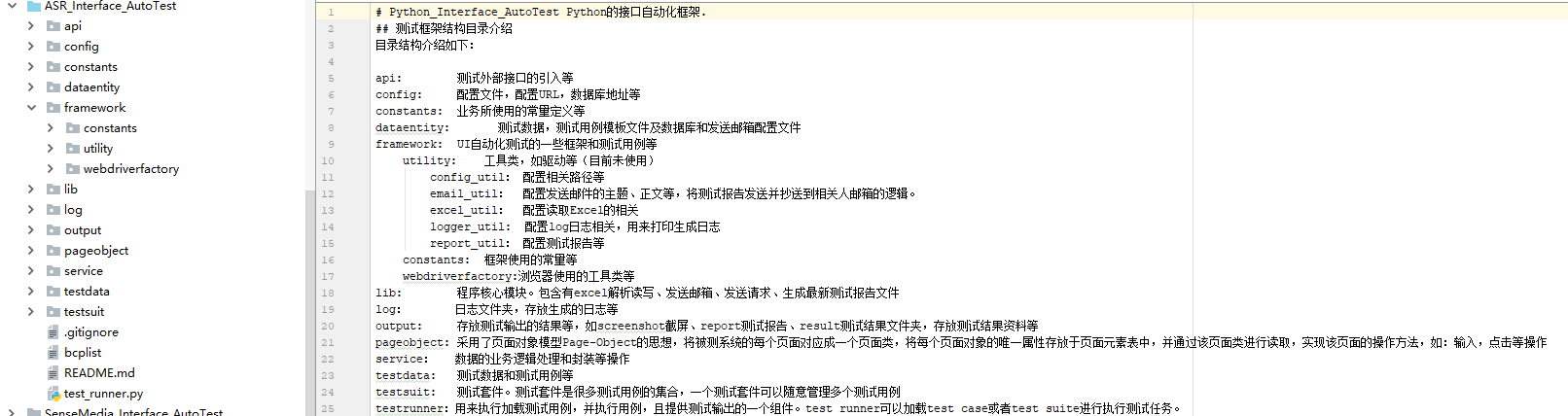
最开始先搭建的Python的UI自动化测试框架,然后在UI自动化测试框架基础上,进行增删改,形成接口自动化测试框架。


然后在接口自动化框架基础上,加上相关的ASR业务属性,以下为ASR的所有的版本迭代记录:

第2步:语音转文字自动化测试流程设计
测试流程:
1、视频MP4素材-》FFmpeg转换为wav文件-》将文件存储到testdata文件夹
2、封装微软、标贝、捷通、声智、云知声等供应商的ASR接口,存放到api文件夹
3、调用(2)封装的ASR供应商接口,对(1)语音wav文件进行识别,并将结果存储到Excel和txt文件
4、读取人工标准答案Excel文件,生成txt文件,对人工和ASR供应商生成的txt文件进行MLF处理,将文件转换为HResults需要的mlf格式
5、使用HResults对人工mlf-asr供应商mlf进行自动化比对,并将结果存储到txt和Excel文件中
6、汇总和分析结果,针对结果数据进行评价等后续操作
HResults处理的核心逻辑:
WER = (S + D + I ) / N = (S + D + I ) / (S + D + H )

- S 为替换的字数,常用缩写WS
- D 为删除的字数,常用缩写WD
- I 为插入的字数,常用缩写WI
- H 为正确的字数,维基百科是C,但我统一改用H
- N 为(S替换+ D删除+ H正确)的字数
**遇到的问题
1、MP4文件转换为wav文件时,转换完的文件无法正常提取出文本
=》原因:转换完的格式和各供应商ASR接口需要的接口参数和码率等不一致,所以无法识别出真正的文本,就会返回随机错误的文字
解决方案:将pcm格式改为和接口需要的参数一样,然后重新转码就可以正确提取出来
# 视频转语音转码 cmd_f = 'ffmpeg -i "{src_path}" -vn -acodec pcm_s16le -ac 1 -ar 16000 "{save_path}"' os.system(cmd_f.format(src_path=src_path, save_path=save_path))
2、文件分类引用遇到的问题,总是找不到相关的路径和引用地址
=》不了解python和pycharm的机制,刚开始使用sys.path.append方式 进行切换,发现这样很不方便使用,后来发现将工程设置为source主目录后,该问题迎刃而解。
解决方案:【Python自学】python 引用import文件夹下的py文件的方法(转)
3、读取config文件过程中遇到的问题
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xa6 in position 9737: ill…
-》原因和解决方案:编码格式的问题引起的,后来将读取时加上编码格式,问题解决
config.read(setting.CONFIG_FILE, encoding="utf-8")
4、UI自动化启动Chrome浏览器遇到的问题
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 80
=》原因和解决方案:由于本地谷歌浏览器和chromedriver的版本不一致导致的。
https://www.jianshu.com/p/1a8e27fcf01a
https://blog.csdn.net/weixin_44318830/article/details/103339273
5、文件里Tab和空格混用导致的问题
TabError: inconsistent use of tabs and spaces in indentation
=》解决方案:在IDE设置里将空格和tab键设置下,保持一致就不会出现编译方面的错误
https://blog.csdn.net/qq_41096996/article/details/85947560
https://blog.csdn.net/w926498/article/details/80999707
https://blog.csdn.net/u014657075/article/details/102812173
6、文件中报红色提示
import的引用总是提示:unresolved reference
=》原因和解决方案:【python自学】python自动化测试框架搭建过程中遇到的问题-PyCharm 导包提示 unresolved reference
7、使用os.system执行过程中,结果出现乱码
这个问题纠结了一整天,就像陷入了死胡同一样,后来晚上5点多起床上厕所,bingo想出了解决方案。
本身HResults可能对中文兼容并不好,既然不能直接改变他,就可以绕过他,于是用os.chdir进入要测试的目录,这样完美的屏蔽了该问题。

=》解决方案:https://www.jb51.net/article/164763.htm