BACKGROUND
Processor power consumption has become a major issue in recent years. The current trend of processor design to multi-core architecture as eased the pressure on power consumption. However, power consumption still grows linearly with the number of cores being designed.
Recent developments in technology have provided new opportunities to further optimize power consumptions. However, these technologies still have several downsides. Specifically, within the new technologies, OS does not understand how effectively the workload is running in the hardware and the associated power cost in the hardware. Secondly, OS interaction is very slow to react. Thirdly, the current OS do not control performance power state per core. Finally, turbo mode only takes thermal and sensor feedback, it does take into account the cores higher performance requirement.
DETAILED DESCRIPTION
Some of the embodiments discussed herein may be utilized to perform event handling operations. In an embodiment, an "event" refers to a condition that may or may not require some action to be taken by logic. Furthermore, events may be classified into different types based on the action that is to be taken.
In one embodiment, and "architectural event" refers to an event or condition that may be monitored (e.g., by programming information corresponding to the architectural event into a state). In an embodiment, software may configure a channel to monitor certain architectural event which may not otherwise be observable by software and/or hardware. In an embodiment, an architectural event may generally refer to an event or condition that occurs within processing resources or other logic present on the same integrated circuit chip as a processor.
In an embodiment, architecture events are one factor for making power management decisions. Architecture events are widely used for software performance optimization. By factoring in architecture events for making power management decisions, the embodiment may effectively detect core execution condition that neither OS nor turbo mode can currently detect.
One embodiment provides additional value to a power control unit (PCU) to make appropriate power decisions using existing designs. The PCU handles thermal events, schedules/manages per core's frequency increase/decrease. In the embodiment, logic is added in the PCU. The PCU then takes feedback from counters to assist in making decisions to scale up a particular core.
Architecture events inside a processor are usually detected by a series of physical counters implemented in different areas of the processor. These counters maybe referred to as EMON counters. EMON counters are performance monitoring counters that reside in each function unit that counts the number of specific events that has occurred during a period of time.
There may be public EMON counters and private EMON counters. Public EMON counters are those accessible by vendors and users, while private EMON counters are used internally for debugging. Both public and private EMON counters may be used for software and hardware tuning. EMON counters are very useful tools to understand the application behavior and how effective the current application is doing inside the processor.
Instruction retried is one type of EMON counter. By knowing instruction retired per cycle, the system knows how fast the current application is executing inside the processor. More instruction retired per cycle, the better performance the application is getting.
Another type EMON counter is a MLC/LLC cache miss. Programs experience lots of MLC/LLC cache miss usually means they require higher BW to system interconnect. It also means the program will not be effectively executing instruction since most of time the problem will be stalled waiting for data return.
Branch Misprediction is also a type of EMON counter. This is a good indicator to show that the core is not doing lots of "useful" work since it is working on the wrong branch of instruction stream.
TLB miss is also a type of EMON counter. Similar to MLC/LLC miss, a TLB miss usually means stalling the core until data has returned.
There are many more counters defined in any processor. For example, Intel's P4 processor contains more than 200 counters. Some of the counters are for performance tuning while others are for debug/validation purposes. The four counters mentioned above, instruction retired, MLC/LLC cache miss, branch misprediction and TLB miss are crucial to the power management discussed here within.
However, it should be noted that the present disclosure is not limited to the above identified counters. Rather, the present disclosure may take as many architectural events as needed. The present system utilizes a push bus mechanism that can connect all counters serially on the same bus since these counters do not require high bandwidth or high refresh rate.
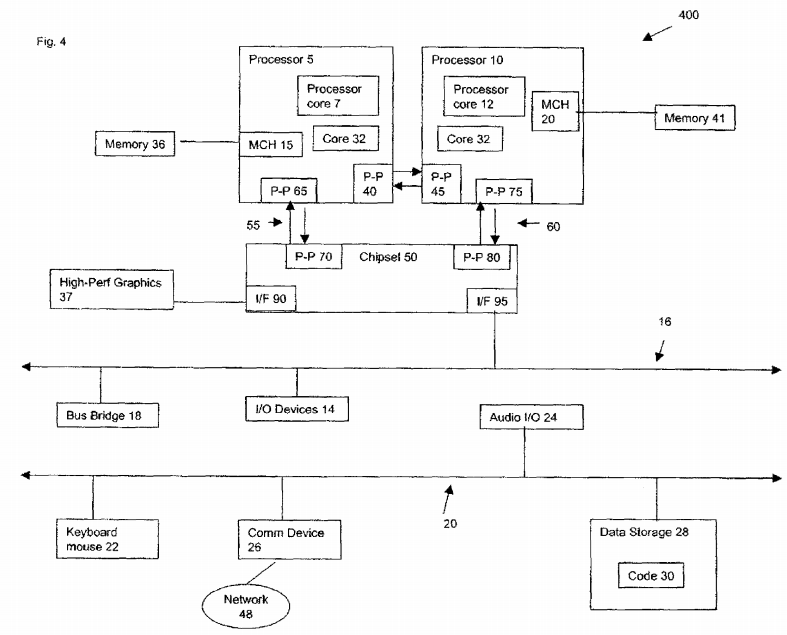
FIG. 1 illustrates a diagram of a thermal sensor and architecture events connection 100 to a PCU in accordance with one embodiment of the invention. FIG. 1 illustrates a processor with eight cores 105 and four shared last level caches (LLC) 107. It should be noted that the eight cores and four shared LLCs are shown for illustrative purposes only. Any number of cores or LLCs may be used for this embodiment. A functional unit 110 is shared among the cores 105. The PCU 115 is one of the units to be shared by the cores 105.
The dark squares in the cores 105 represent thermal sensors 120. The cores 105 have thermal sensors 105 to prevent over heating of the cores 105. A serial push bus 125 connects all the sensors 120 on the bus. The push bus 125 may have various branches. A first branch 127 of the push bus 125 may take up to 96 time slots, where each time slot is reserved for one of the thermal sensors 120. There is at least one branch 127 of the push bus 125 in each core 105. Each branch 127 of the push bus 105 may monitor one core 105 with all the thermal sensors 120. All the data collected from the thermal sensors 120 by the push bus125 is then sent to the PCU 115.
A similar approach is made to monitor architectural events by linking different counters via the same serial push bus mechanism and each counter having a designated time slot. The light squares are EMON counters 130. The dotted line 135 is another branch of the serial push bus. The second branch 135 of the push bus125 may take up to 96 time slots, where each time slot is reserved for one of the EMON counters. There is at least one branch 135 of the push bus 125 in each core 105. Each branch 135 of the push bus 125 may monitor one core 105 with all the EMON counters 130. All the data collected from the EMON counters130 by the push bus 125 is then sent to the PCU 115.
The PCU 115 may have very low sampling rate to retrieve information from the push bus 125 which is one reason why all the sensors may share a narrow bus. The serial push bus 125 may not be more than 10 bits wide and runs a low sampling rate. Due to this, there is no high bandwidth requirement to monitor these events. Sampling the counters every 1000 cycles may be sufficient. The sampling frequency should be tuned with the thermal sensors so that PCU 115 decisions may be made coherent between architectural events 130 and thermal sensors 120.
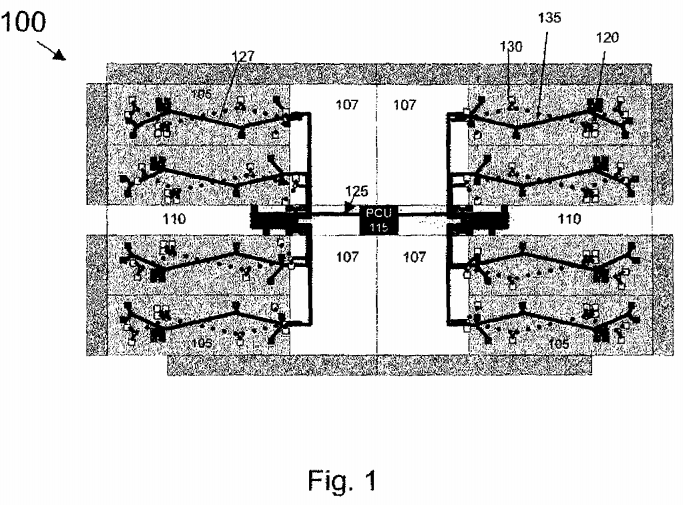
FIG. 2 illustrates a flow chart of a method 200 for architecture event power controller in accordance with one embodiment of the invention. The method 200 begins when the system is in idle mode 205. When each timer interval is reached, architectural event power optimization logic (AEPOL) examines the counts and decides whether a power up or power down sequence should be initiated 210.
For a power up sequence, AEPOL queries PCU 115 to determine if turbo mode is available 215. If turbo mode is not available, meaning no reserve power is available, AEPOL goes back to idle more 205 until the next timer interval arrives. If turbo mode is available, AEPOL initiates a power up sequence 220. Once the power up sequence is completed AEPOL goes into idle mode 205 until the next timer interval.
For a power down sequence, AEPOL notifies PCU 115 to initiate power down sequence 225. Once power down sequence is completed, AEPOL goes to idle mode 205 until the next timer interval.
The AEPOL referred to in FIG. 2 is implemented per core. The logic may constantly monitor architectural events to ensure cores are running in it optimal power/performance state.
In one embodiment, architecture event counts of interest are counted and sent to the PCU 115. PCU 115 then analyzes the counts it receives from each counter and determines whether it should power up or power down a particular core 105. In one embodiment, if a system interconnect (shared cache, bus control logic, on-die memory control, etc.) also supports power scaling, the same mechanism may be used to scale system interconnect logic.
In an embodiment, all EMON counters 130 monitored should be referenced together to better understand AEPOL behavior. For example, low instruction retired per cycle (IPC) count does not mean core is not running effectively unless we know it also suffers high cache miss or high branch misprediction.
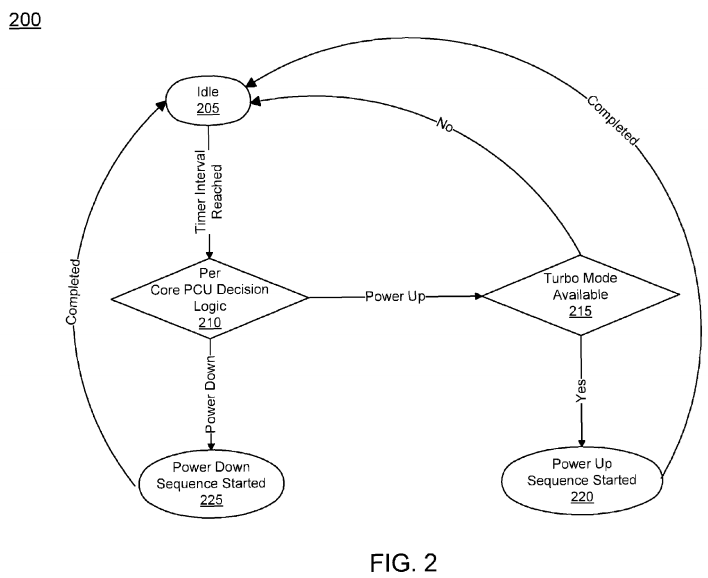
As shown in Table 1 below, the architecture events of interests are grouped together to make decisions. A threshold count for each architecture event counter is also defined. The threshold value is defined based on performance studies for a particular architecture, as performance may differ depending on the architecture of the system. In Table 1, if all related architecture counters are low, this suggests that the system does not suffer from any system bound actions. Therefore, scaling up the frequency on the core does help increasing the performance of the application. On the other hand, if the core is suffering rather high counts of MLC/LLC misses, there will be no benefit to increase core frequency since the performance is bounded by access latency to an off-chip component. In this situation, the system should scale down the core frequency and divert the saved power to other cores that may be doing useful work.
Therefore, AEPOL allows for an intelligent decision making on when to turn on turbo where performance will benefit and can be observed and it lowers the power dissipation with fine tuning performance power state on cores that are stalling on instruction
There can be many more scenarios or other useful architectural event counters that can do finer grain control of the core power usage and the AEPOL logic is applicable to all these situations.
With AEPOL optimization, the system is given a smarter way to utilize the available power to the processor. In future processor design where power aware architecture must exist across the board, AEPOL not only provides a way to conserve energy when it is not needed, it also provides opportunity to optimize performance further within the same power budget. This mechanism opens a whole new range of opportunity for finer grain hardware tuning.
FIG. 3 illustrates a block diagram of a computing system 300 in accordance with an embodiment of the invention. The computing system 300 may include one or more central processing units(s) (CPUs) 31 or processors that communicate via an interconnection network (or bus) 49. The processors 31 may be any type of a processor such as a general purpose processor, a network processor (that processes data communicated over a computer network 48, or other types of a processor (including a reduced instruction set computer (RISC) processor or a complex instruction set computer (CISC). Moreover, the processors 31 may have a single or multiple core design. The processors 31 with a multiple core design may integrate different types of processor cores on the same integrated circuit (IC) die. Also, the processors 31 may utilize the embodiments discussed with references to FIGS. 1 and 2. For example, one or more of the processors 31 may include one or more processor cores 32. Also, the operations discussed with reference to FIGS. 1 and 2 may be performed by one or more components of the system 300.
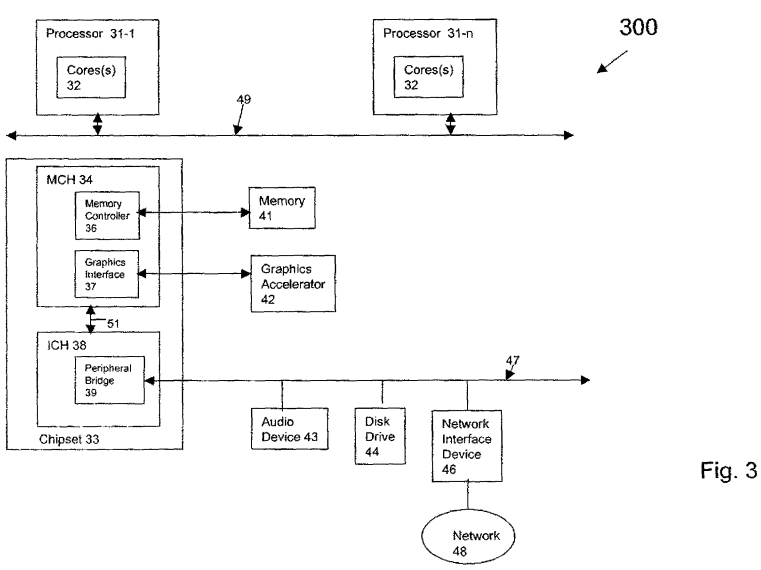
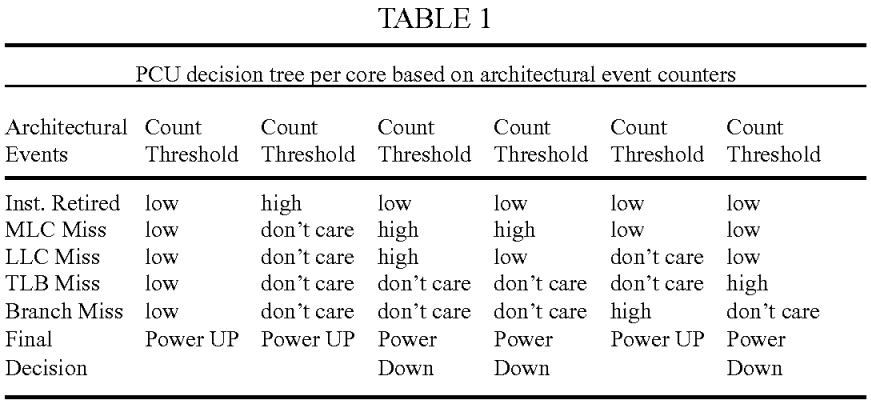
FIG. 4 illustrates a computing system 400 that is arranged in a point-to-point (PtP) configuration, according to an embodiment of the invention. In particular, FIG. 4 shows a system where processors, memory, and input/output devices are interconnected by a number of point to point interfaces. The operations discussed with reference to FIGS. 1-3 may be performed by one or more components of the system 400.