1、HDFS(数据存储)
①、NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数,文件权限),以及每个文件的块列表和块所在的DataNode等。
②、DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。
③、Secondary NameNode:用来监控HDFS状态的辅助后台查询,每隔一段时间获取HDFS元素的快照。
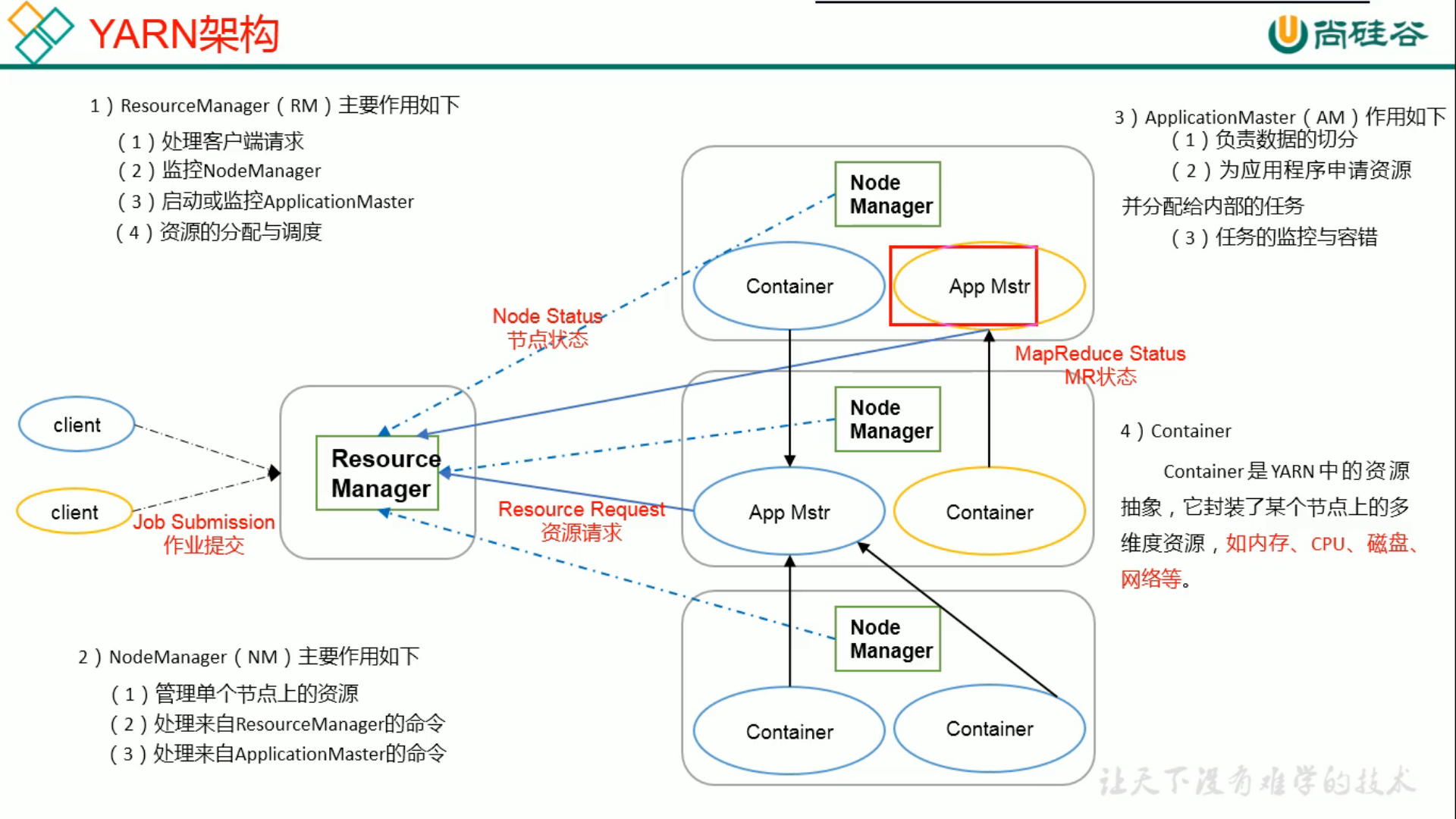
2、YARN(资源调度)
3、MapReduce(计算)
MapReduce将计算过程分为两个阶段:Map和Reduce,如图所示。
①、Map阶段并行处理输入数据。
②、Reduce阶段对Map结果进行汇总。

4、Common(辅助工具)
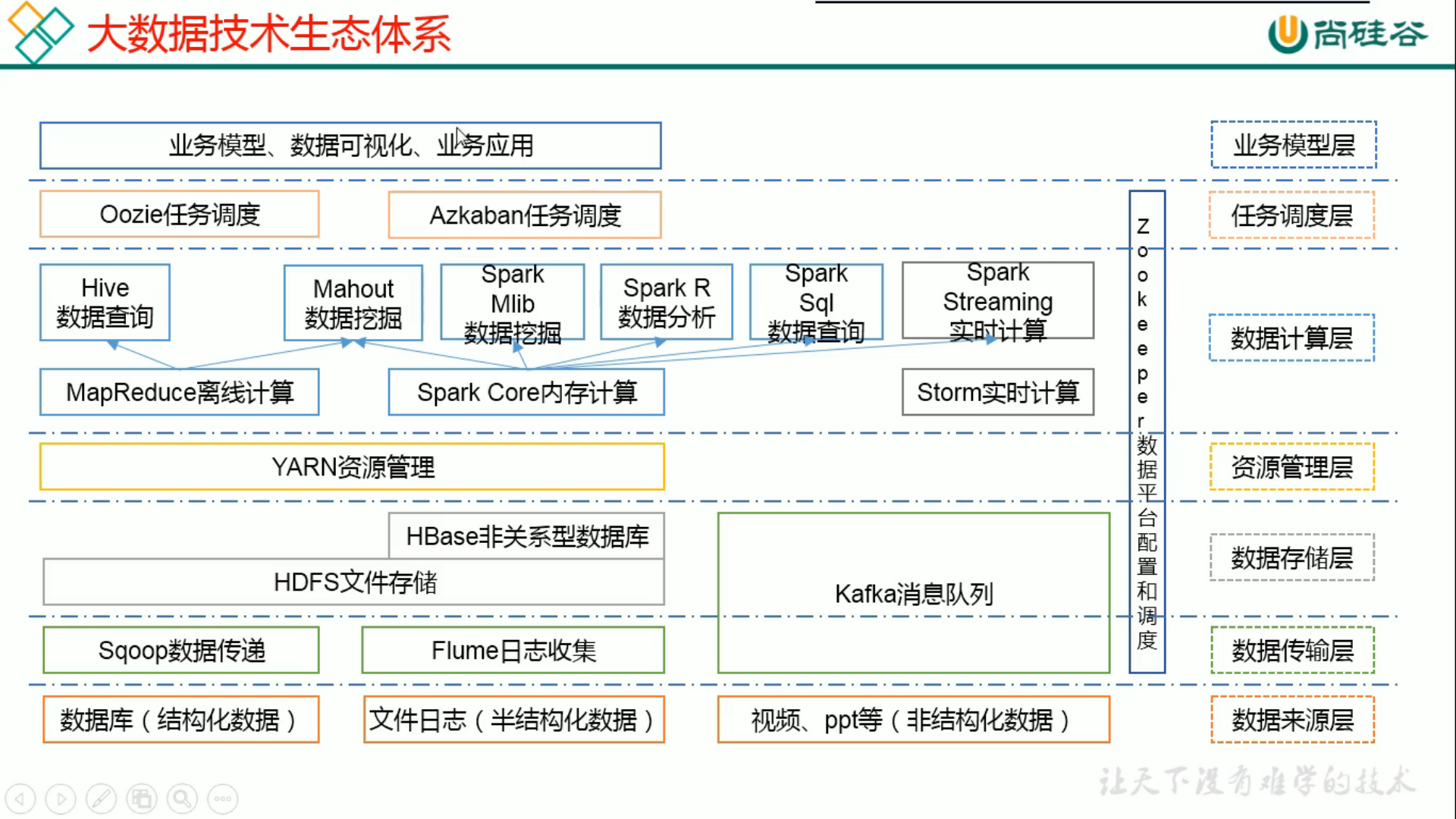
大数据技术生态体系