awk 简介
awk是一个文本处理工具,通常用于处理数据并生成结果报告,
awk的命名是它的创始人 Alfred Aho、Peter Weinberger和Brian Kernighan 姓氏的首个字母组成的。
awk的工作模式

语法格式
第一种形式: 基于文件
awk 'BEGIN{}pattern{commands}END{}' file_name
第二种形式: 基于标准命令格式
standard output | awk 'BEGIN{}pattern{commands}END{}'
语法格式说明

awk的内置变量
内置变量对照表


内置变量:
$0 打印行所有信息
$1~$n 打印行的第1到n个字段信息
NF Number Field 处理行的字段个数
NR Number Row 处理行的行号
FNR File Number Row 多文件处理时,每个文件单独记录行号
FS Field Separator 字段分隔符,不指定时默认以空格或tab键分割
RS Row Separator 行分隔符,不指定时以回车换行分割
OFS Output Filed Separator 输出字段分隔符
ORS Output Row Separator 输出行分隔符
FILENAME 处理文件的文件名
ARGC 命令行参数个数
ARGV 命令行参数数组
输出整行数据
awk '{print $0}' passwd

FS指定分隔符为 : 输出所有行第一个字段
awk 'BEGIN{FS=":"}{print $1}' passwd
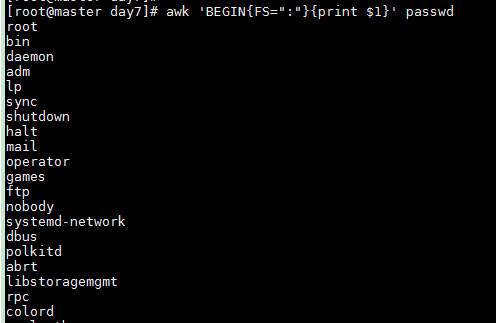
默认以空格或者tab为分隔符
list
Hadoop Spark Flume Java Python Scala Allen Mike Meggie
以空格为分隔符, 输出第一个字段
awk 'BEGIN{FS=" "}{print $1}' list

NF 输出每一行的字段个数
awk '{print NF}' list
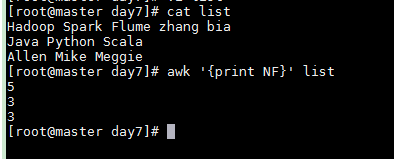
NR 输出行号,处理多个文件(list,passwd,/etc/fstab) 时行号累加
awk '{print NR}' list passwd /etc/fstab
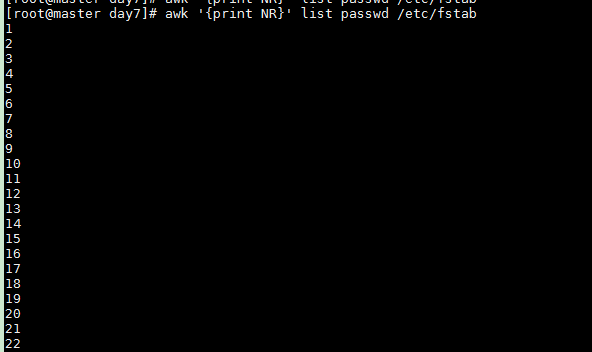
FNR在处理两个文件以上时会单独计数
awk '{print FNR}' list /etc/fstab

list
Hadoop|Spark:Flume Java|Python:Scala:Golang Allen|Mike:Meggie
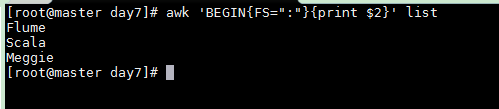
以 | 符号分隔列, 输出第二个字段

以 : 符号分隔列
awk 'BEGIN{FS=":"}{print $2}' list
list
Hadoop|Spark|Flume--Java|Python|Scala|Golang--Allen|Mike|Meggie
RS 指定行分隔符: --
awk 'BEGIN{RS="--"}{print $0}' list

awk 'BEGIN{RS="--";FS="|"}{print $3}' list
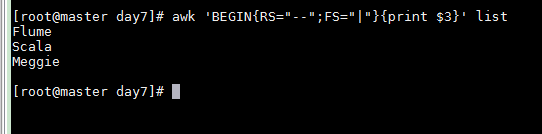
ORS输出分隔符,以&连接各输出行
awk 'BEGIN{RS="--";FS="|";ORS="&"}{print $3}' list

字段默认分隔符是空格
awk 'BEGIN{RS="--";FS="|";ORS="&"}{print $1,$3}' list

OFS 指定字段分隔符为 :
awk 'BEGIN{RS="--";FS="|";ORS="&";OFS=":"}{print $1,$3}' list

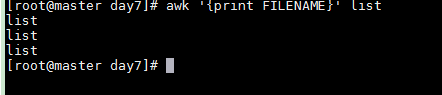
FILENAME 文件名
awk '{print FILENAME}' list

list
Hadoop|Spark|Flume--Java|Python|Scala|Golang--Allen|Mike|Meggie Test File Line
输出3次文件名list,是因为没有输入匹配模式 awk默认是行处理,文本有3行,处理三次会有3次输出
awk '{print FILENAME}' list
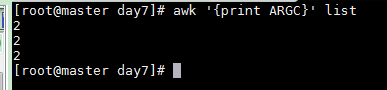
ARGC命令行参数个数 awk 和 list 共链各个参数
awk '{print ARGC}' list
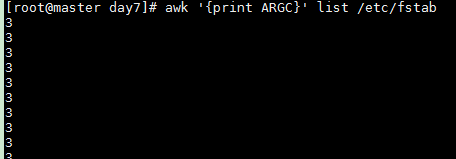
awk '{print ARGC}' list /etc/fstab 这样的话就是 3 个参数
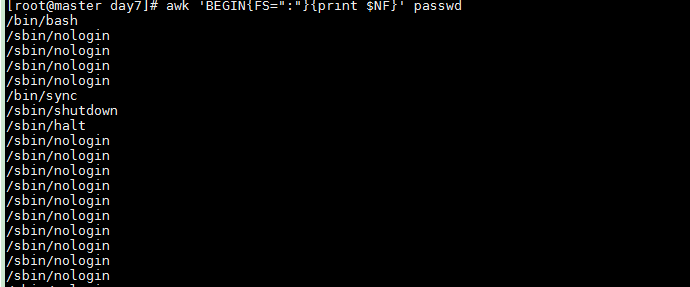
NF表示字段个数,NF=7 $NF表示字段的个数一般来显示最后一个字段
awk 'BEGIN{FS=":"}{print $NF}' passwd
awk 格式化输出 printf
printf的格式说明符


格式化案例演示
printf默认没有分隔符
awk 'BEGIN{FS=":"}{printf $1}' passwd

加入换行,格式化输出
awk 'BEGIN{FS=":"}{printf "%s
",$1}' passwd
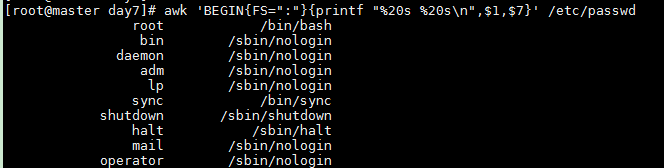
使用占位符美化输出,默认是右对齐
awk 'BEGIN{FS=":"}{printf "%20s %20s
",$1,$7}' /etc/passwd
- 减号是左对齐,+ 加号是右对齐
awk 'BEGIN{FS=":"}{printf "%-20s %-20s
",$1,$7}' /etc/passwd

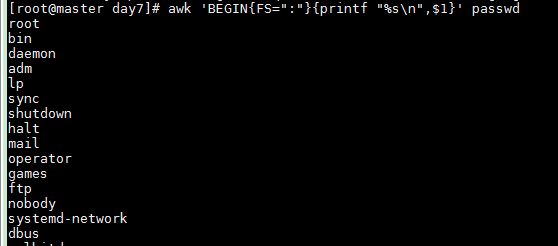
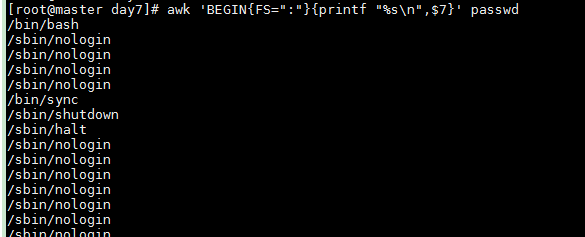
以字符串格式打印/etc/passwd中的第7个字段,以":"作为分隔符
awk 'BEGIN{FS=":"}{printf "%s
",$7}' passwd
以10进制格式打印/etc/passwd中的第3个字段,以":"作为分隔符
awk 'BEGIN{FS=":"}{printf "%d
",$3}' passwd
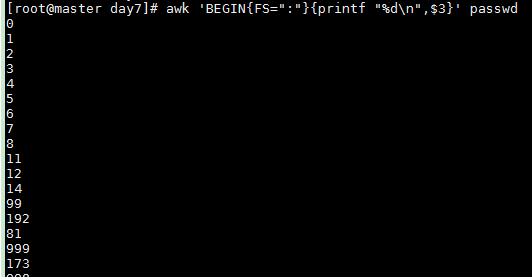
以浮点数格式打印/etc/passwd中的第3个字段,以":"作为分隔符
awk 'BEGIN{FS=":"}{printf "%0.2f
",$3}' passwd
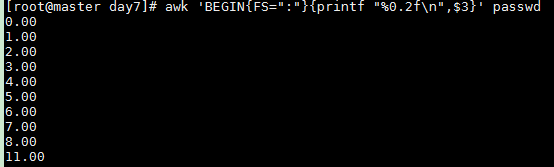
以16进制数格式打印/etc/passwd中的第3个字段,以":"作为分隔符
awk 'BEGIN{FS=":"}{printf "%x
",$3}' passwd
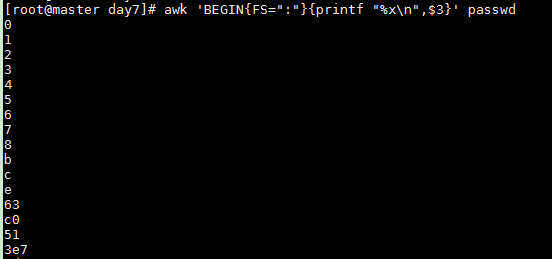
以8进制数格式打印/etc/passwd中的第3个字段,以":"作为分隔符
awk 'BEGIN{FS=":"}{printf "%o
",$3}' passwd
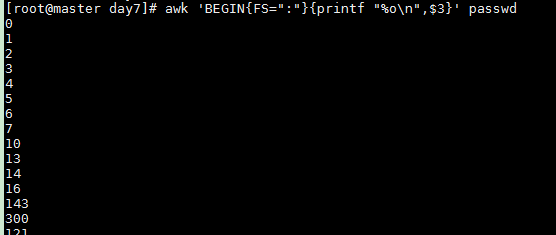
以科学计数法格式打印/etc/passwd中的第3个字段,以":"作为分隔符
awk 'BEGIN{FS=":"}{printf "%e
",$3}' passwd

awk模式匹配的两种方法
awk 模式匹配格式对照表


正则匹配 RegExp
匹配/etc/passwd文件行中含有root字符串的所有行
awk 'BEGIN{FS=":"}/root/{print $0}' passwd

匹配/etc/passwd文件行中以nginx开头的所有行
awk '/^nginx/{print $0}' passwd

运算符匹配
- < 小于
- > 大于
- <= 小于等于
- >= 大于等于
- == 等于
- != 不等于
- ~ 匹配正则表达式
- !~ 不匹配正则表达式
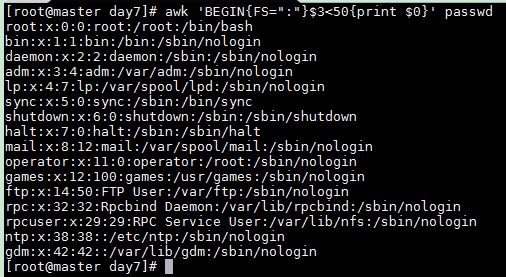
以 : 为分隔符,匹配/etc/passwd文件中第3个字段小于50的所有行信息
awk 'BEGIN{FS=":"}$3<50{print $0}' passwd
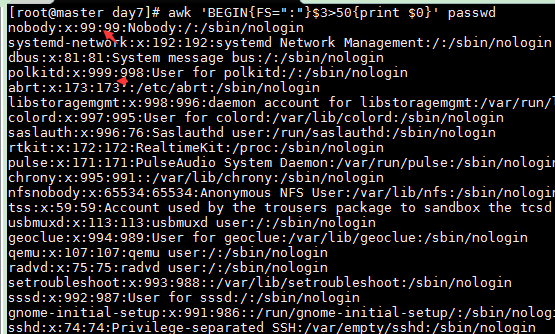
以:为分隔符,匹配/etc/passwd文件中第3个字段大于50的所有行信息
awk 'BEGIN{FS=":"}$3>50{print $0}' passwd
以:为分隔符,匹配/etc/passwd文件中第7个字段为/bin/bash的所有行信息
awk 'BEGIN{FS=":"}$7=="/bin/bash"{print $0}' passwd

以:为分隔符,匹配/etc/passwd文件中第7个字段不为/bin/bash的所有行信息
awk 'BEGIN{FS=":"}$7!="/bin/bash"{print $0}' passwd

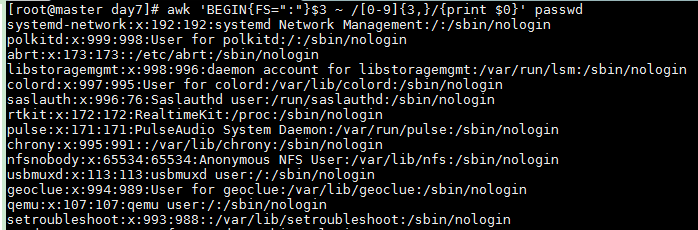
以:为分隔符,匹配/etc/passwd文件中第3个字段包含3个数字以上的所有行信息
awk 'BEGIN{FS=":"}$3 ~ /[0-9]{3,}/{print $0}' passwd
布尔运算符匹配
- || 或
- && 与
- ! 非
以 : 为分隔符,匹配/etc/passwd文件中包含ftp或mail的所有行信息
awk 'BEGIN{FS=":"}$1=="ftp" || $1=="mail"{print $0}' passwd

以:为分隔符,匹配/etc/passwd文件中第3个字段小于50并且第4个字段大于50的所有行信息
awk 'BEGIN{FS=":"}$3<50 && $4>50{print $0}' passwd

匹配包含 nginx 的行
awk 'BEGIN{FS=":"}/^nginx/{print $0}' passwd

关系运算符,uid 等于1的行
awk 'BEGIN{FS=":"}$3==1{print $0}' passwd
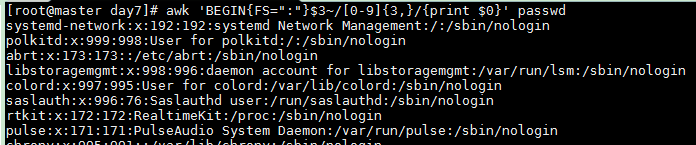
匹配uid(数字)为3位及以上的行
awk 'BEGIN{FS=":"}$3~/[0-9]{3,}/{print $0}' passwd
匹配不包含/sbin/nologin 的行
awk 'BEGIN{FS=":"}$0!~//sbin/nologin/{print $0}' passwd

找出 uid 小于50,且bash为 /bin/bash 的行
awk 'BEGIN{FS=":"}$3<50 && $7~//bin/bash/ {print $0}' passwd
