文章很长,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈 奉上以下珍贵的学习资源:
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:seata AT模式实战(图解+秒懂+史上最全) |
| 13:seata 源码解读(图解+秒懂+史上最全) | 14:seata TCC模式实战(图解+秒懂+史上最全) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团... 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
背景:
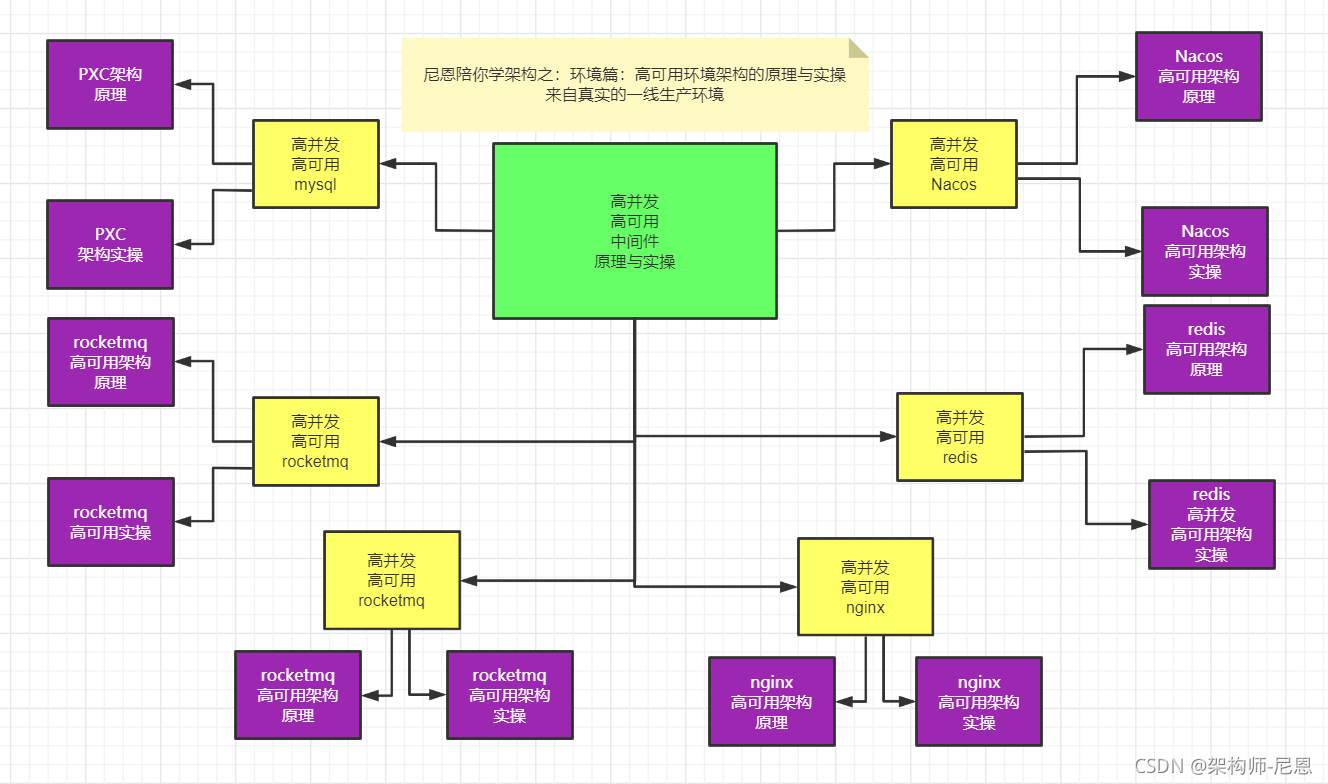
下一个视频版本,从架构师视角,尼恩为大家打造高可用、高并发中间件的原理与实操。
目标:通过视频和博客的方式,为各位潜力架构师,彻底介绍清楚架构师必须掌握的高可用、高并发环境,包括但不限于:
-
高可用、高并发nginx架构的原理与实操
-
高可用、高并发mysql架构的原理与实操
-
高可用、高并发nacos架构的原理与实操
-
高可用、高并发rocketmq架构的原理与实操
-
高可用、高并发es架构的原理与实操
-
高可用、高并发minio架构的原理与实操
why 高可用、高并发中间件的原理与实操:
实际的开发过程中,很多小伙伴聚焦crud开发,环境出了问题,都不能启动。
作为架构师,或者未来想走向高端开发,或者做架构,必须掌握高可用、高并发中间件的原理,掌握其实操。
Mysql集群的背景
单机单点的数据库,一旦这台机子宕机(机器出现故障、机房停电、...),那整个网站将无法正常访问。
单节点的数据库无法满足性能上的要求,就像校园网查成绩的时候,如果1万人同时查,你可能拿到就是一个白屏,无论你是收费的还是免费的数据库,单节点都满足不了这种并发需求
单节点的数据库没有冗余设计,无法满足高可用,一旦这个机器出现问题,没有其他节点的数据库顶替,那网站将无法正常访问
这时候集群就出现了,一台机器出现问题了,另外的机器还在正常运行,网站依旧可以访问。
集群案例:滴滴出行、淘宝、京东、斗鱼直播、支付宝、微信、QQ
单节点数据库的弊端
无论是 数据库访问的流量 还是 数据体量, 达到了单库单表的瓶颈之后,(具体具体请参见尼恩的秒杀架构视频),都需要分库。
下面就是一个案例,具体的案例太多啦。 so, mysql集群的原理和实操,大家一定需要掌握。
高可用高并发MYSQL案例
1.天猫双十一
2017年天猫双十一的交易额达到1682亿元,3分钟破百亿,9小时破千亿
交易峰值(下订单的峰值):32.5万/秒
支付峰值:25.6万/秒
数据库峰值:4200万/秒
支持这么漂亮的数字完美运行,除了数据库集群技术还有云服务器、负载均衡、RDS云数据库等技术
2.微信红包
2017年除夕当天,全国人民总共收发142亿个红包,峰值42万/秒
央视春晚微信摇一摇互动总量达110万亿次,峰值8.1亿/秒
学习目标和方式
1)向大型互联网应用看起,学习架构设计和业务处理
2)掌握PXC集群MySQL方案的原理
3)掌握PXC集群的强一致性
4)掌握PXC集群的高可用方案
5)解决实际的问题
来自小伙伴的具体的生产环境问题:
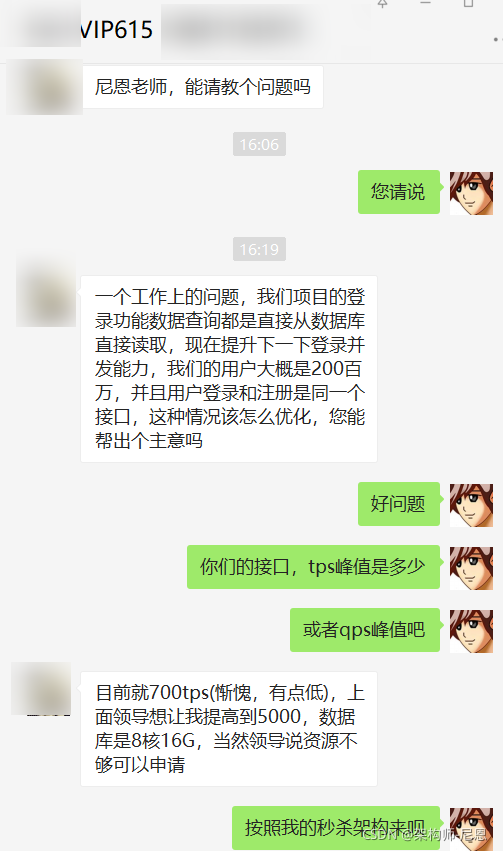
尼恩老师,能请教个问题吗?
一个工作上的问题,我们项目的登录功能数据查询都是直接从数据库直接读取,现在提升下一下登录并发能力,我们的用户大概是200百万,并且用户登录和注册是同一个接口,这种情况该怎么优化,您能帮出个主意吗

PXC简介
PXC(Percona XtraDB Cluster)是一个开源的MySQL高可用解决方案。
Percona XtraDB Cluster(简称PXC集群)提供了MySQL高可用的一种实现方法。
1)集群是有节点组成的,推荐配置至少3个节点,但是也可以运行在2个节点上。
2)每个节点都是普通的mysql/percona服务器,可以将现有的数据库服务器组成集群,反之,也可以将集群拆分成单独的服务器。
3)每个节点都包含完整的数据副本。


MySQL分支的选择:Percona还是MariaDB
在MySQL被Oracle收购以后,越来越多的人对于MySQL的前景表示了担忧,对于开源的MySQL,或多或少对于Oracle自家的数据库产品产生冲击,这个开源免费的MySQL 对于Oracle更多的是包袱而不是资产。
比如淘宝就从Oracle转成了MySQL,一些大型互联网公司也在推行去IOE(I:IBM,O:Oracle,E:EMC),甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险。

Percona
在介绍 Percona 之前,首要要介绍的是XtraDB存储引擎,在MYSQL中接触比较多的是MyISAM和InnoDB这两个存储引擎。MySQL 4和5使用默认的MyISAM存储引擎安装每个表。从5.5开始,MySQL已将默认存储引擎从MyISAM更改为InnoDB。
MyISAM没有提供事务支持,而InnoDB提供了事务支持。
与MyISAM相比,InnoDB提供了许多细微的性能改进,并且在处理潜在的数据丢失时提供了更高的可靠性和安全性。
Percona XtraDB 是 InnoDB 存储引擎的增强版,被设计用来更好的使用更新计算机硬件系统的性能,同时还包含有一些在高性能环境下的新特性。
Percona XtraDB 存储引擎是完全的向下兼容,在 MariaDB 中,XtraDB 存储引擎被标识为”ENGINE=InnoDB”,这个与 InnoDB 是一样的,所以你可以直接用XtraDB 替换掉 InnoDB 而不会产生任何问题。
Percona XtraDB 包含有所有 InnoDB’s 健壮性,可依赖的 ACID 兼容设计和高级 MVCC 架构。
XtraDB 在 InnoDB 的坚实基础上构建,使 XtraDB 具有更多的特性,更好调用,更多的参数指标和更多的扩展。从实践的角度来看,XtraDB 被设计用来在多核心的条件下更有效的使用内存和更加方便,更加可用。
新的特性被用来降低 InnoDB 的局限性。性能层面,XtraDB与内置的MySQL 5.1 InnoDB 引擎相比,它每分钟可处理2.7倍的事务。
Percona Server由领先的MySQL咨询公司Percona发布。
Percona Server是一款独立的数据库产品,其可以完全与MySQL兼容,可以在不更改代码的情况了下将存储引擎更换成XtraDB 。
Percona团队的最终声明是“Percona Server是由Oracle发布的最接近官方MySQL Enterprise发行版的版本”,因此与其他更改了大量基本核心MySQL代码的分支有所区别。Percona Server的一个缺点是他们自己管理代码,不接受外部开发人员的贡献,以这种方式确保他们对产品中所包含功能的控制。
MariaDB
MariaDB由MySQL的创始人麦克尔·维德纽斯主导开发,他早前曾以10亿美元的价格,将自己创建的公司MySQL AB卖给了SUN,此后,随着SUN被甲骨文收购,MySQL的所有权也落入Oracle的手中。
MariaDB名称来自麦克尔·维德纽斯的女儿玛丽亚(英语:Maria)的名字。
MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,10.0.9版起使用XtraDB(名称代号为Aria)来代替MySQL的InnoDB。
版本方面,MariaDB直到5.5版本,均依照MySQL的版本。
因此,使用MariaDB5.5的人会从MySQL 5.5中了解到MariaDB的所有功能。从2012年11月12日起发布的10.0.0版开始,不再依照MySQL的版号。
10.0.x版以5.5版为基础,加上移植自MySQL 5.6版的功能和自行开发的新功能。
相对于最新的MySQL5.6,MariaDB在性能、功能、管理、NoSQL扩展方面包含了更丰富的特性。比如微秒的支持、线程池、子查询优化、组提交、进度报告等。
Percona OR MariaDB
选择是一件痛苦的事情,对于上面的两个数据库,就是大公司也存在分歧,就像淘宝目前使用的是Percona 5.5.18,而Google、Wikipedia则站在了MariaDB这边。具体哪一个会走的更远,我们就拭目以待吧。
基于Galera的高可用方案
不幸的是,传统架构的使用,一直被人们所诟病,因为MySQL的主从模式,天生的不能完全保证数据一致,很多大公司会花很大人力物力去解决这个问题,而效果却一般,可以说,只能是通过牺牲性能,来获得数据一致性,但也只是在降低数据不一致性的可能性而已。
问题:MySQL的主从模式,天生的不能完全保证数据一致,why?
具体答案,请参见配套视频。
所以现在就急需一种新型架构,从根本上解决这样的问题,天生的摆脱掉主从复制模式这样的“美中不足”之处了。
幸运的是,MySQL的福音来了,Galera Cluster就是我们需要的——从此变得完美的架构。
基于Galera的高可用方案主要有MariaDB Galera Cluster和Percona XtraDB Cluster,目前PXC架构在生产线上用的更多而且更成熟一些。
Galera Cluster
- 由 Codership 开发 官网
- 包含在MariaDB,在Percona、MySQL 都可以使用
Galera Cluster 是一个基于 InnoDB 多主的同步复制,可以读写任何节点,即使失去任何一个节点也不影响业务中断,而且无需复杂的 failover 操作。
Percona XtraDB Cluster
- 由 Percona 开发,在 Galera 基础打 Patch [官网](https://www.percona.com/software/mysql- database/percona-xtradb-cluster)
- 自 2012 年 4 月可用
- 附加的特性
- PFS 扩展支持
- SST/XtraBackup 方式的改变
- PXC Strict mode
- ProxySQL 集成
- 提升性能
MariaDB Galera Cluster
1.简述:
MariaDB Galera Cluster 是一套在mysql innodb存储引擎上面实现multi-master及数据实时同步的系统架构,业务层面无需做读写分离工作,数据库读写压力都能按照既定的规则分发到各个节点上去。在数据方面完全兼容 MariaDB 和 MySQL。
在 Galera 基础打 Patch
2.特性:
(1).同步复制 Synchronous replication
(2).Active-active multi-master 拓扑逻辑
(3).可对集群中任一节点进行数据读写
(4).自动成员控制,故障节点自动从集群中移除
(5).自动节点加入
(6).真正并行的复制,基于行级
(7).直接客户端连接,原生的 MySQL 接口
(8).每个节点都包含完整的数据副本
(9).多台数据库中数据同步由 wsrep 接口实现
3.局限性
(1).目前的复制仅仅支持InnoDB存储引擎,任何写入其他引擎的表,包括mysql.*表将不会复制,但是DDL语句会被复制的,因此创建用户将会被复制,但是insert into mysql.user…将不会被复制的.
(2).DELETE操作不支持没有主键的表,没有主键的表在不同的节点顺序将不同,如果执行SELECT…LIMIT… 将出现不同的结果集.
(3).在多主环境下LOCK/UNLOCK TABLES不支持,以及锁函数GET_LOCK(), RELEASE_LOCK()…
(4).查询日志不能保存在表中。如果开启查询日志,只能保存到文件中。
(5).允许最大的事务大小由wsrep_max_ws_rows和wsrep_max_ws_size定义。任何大型操作将被拒绝。如大型的LOAD DATA操作。
(6).由于集群是乐观的并发控制,事务commit可能在该阶段中止。如果有两个事务向在集群中不同的节点向同一行写入并提交,失败的节点将中止。对于集群级别的中止,集群返回死锁错误代码(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)).
(7).XA事务不支持,由于在提交上可能回滚。
(8).整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
(9).集群节点建议最少3个。
(10).如果DDL语句有问题将破坏集群。
Galera Cluster方案的优势
本身Galera Cluster也是一种多主架构。
相比传统的主从复制架构,Galera Cluster解决的最核心问题是,在三个实例(节点)之间,它们的关系是对等的,multi-master架构的,在多节点同时写入的时候,能够保证整个集群数据的一致性,完整性与正确性。
在传统MySQL的使用过程中,也不难实现一种multi-master架构,但是一般需要上层应用来配合,比如先要约定每个表必须要有自增列,并且如果是2个节点的情况下,一个节点只能写偶数的值,而另一个节点只能写奇数的值,同时2个节点之间互相做复制,因为2个节点写入的东西不同,所以复制不会冲突,在这种约定之下,可以基本实现多master的架构,也可以保证数据的完整性与一致性。但这种方式使用起来还是有限制,同时还会出现复制延迟,并且不具有扩展性,不是真正意义上的集群。
PXC相比那些传统的基于主从模式的集群架构MHA和双主,Galera Cluster 最突出的特点就是解决了诟病已久的复制延迟问题,基本上可以达到实时同步。
而且节点与节点之间,它们互相的关系是对等的。
PXC是在存储引擎层实现的同步复制,而非异步复制,所以其数据的一致性是相当高的。
MySQL Group Replication
- 由 Oracle 官方开发
- 2016 年 12 月 MySQL 5.7.17 发布 GA
- MySQL InnoDB Cluster 整体解决方案
MySQL Group Replication 是一个 MySQL Server Plugin,提供分布式状态机复制与 Server 强大协调,当在一个 Group Replication 时,Server 将自动协调,每个节点都可以自动处理更新,自动检测,有一个 membership service 维护一个 view,记录组内 记录可见成员在某个时间点一致性和高可用性的,当任何一个成加入或离开,view 就会相应的更新
MMM
MMM是在MySQL Replication的基础上,对其进行优化。
MMM(Master Replication Manager for MySQL)是双主多从结构,这是Google的开源项目,使用Perl语言来对MySQL Replication做扩展,提供一套支持双主故障切换和双主日常管理的脚本程序,主要用来监控mysql主主复制并做失败转移。

注意:这里的双主节点,虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热。
就各个集群方案来说,其优势为:
- 自动的主主Failover切换,一般3s以内切换备机。
- 多个从节点读的负载均衡。
其劣势为:
- 无法完全保证数据的一致性。如主1挂了,MMM monitor已经切换到主2上来了,而若此时双主复制中,主2数据落后于主1(即还未完全复制完毕),那么此时的主2已经成为主节点,对外提供写服务,从而导致数据不一。
- 由于是使用虚拟IP浮动技术,类似Keepalived,故RIP(真实IP)要和VIP(虚拟IP)在同一网段。如果是在不同网段也可以,需要用到虚拟路由技术。但是绝对要在同一个IDC机房,不可跨IDC机房组建集群。
MHA
MHA是在MySQL Replication的基础上,对其进行优化。
MHA(Master High Availability)是多主多从结构,这是日本DeNA公司的youshimaton开发,主要提供更多的主节点,但是缺少VIP(虚拟IP),需要配合keepalived等一起使用。
要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。

就各个集群方案来说,其优势为:
- 可以进行故障的自动检测和转移
- 具备自动数据补偿能力,在主库异常崩溃时能够最大程度的保证数据的一致性。
其劣势为:
- MHA架构实现读写分离,最佳实践是在应用开发设计时提前规划读写分离事宜,在使用时设置两个连接池,即读连接池与写连接池,也可以选择折中方案即引入SQL Proxy。但无论如何都需要改动代码;
- 关于读负载均衡可以使用F5、LVS、HAPROXY或者SQL Proxy等工具,只要能实现负载均衡、故障检查及备升级为主后的读写剥离功能即可,建议使用LVS
Galera Cluster
Galera Cluster是由Codership开发的MySQL多主结构集群,这些主节点互为其它节点的从节点。
于MySQL原生的主从异步复制,Galera采用的是多主同步复制,并针对同步复制过程中,会大概率出现的事务冲突和死锁进行优化,就是复制不基于官方binlog而是Galera复制插件,重写了wsrep api。
异步复制中,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化。这种情况下,在主库事务提交后的短时间内,主从库数据并不一致。
同步复制时,主库的单个更新事务需要在所有从库上同步 更新。换句话说,当主库提交事务时,集群中所有节点的数据保持一致。
对于读操作,从每个节点读取到的数据都是相同的。对于写操作,当数据写入某一节点后,集群会将其同步到其它节点。

就各个集群方案来说,其优势为:
- 多主多活下,可对任一节点进行读写操作,就算某个节点挂了,也不影响其它的节点的读写,都不需要做故障切换操作,也不会中断整个集群对外提供的服务。
- 拓展性优秀,新增节点会自动拉取在线节点的数据(当有新节点加入时,集群会选择出一个Donor Node为新节点提供数据),最终集群所有节点数据一致,而不需要手动备份恢复。
其劣势为:
- 能做到数据的强一致性,毫无疑问,也是以牺牲性能为代价。
PXC原理
PXC集群主要由两部分组成
PXC集群主要由两部分组成:
Percona Server with XtraDB和Write Set Replication patches(使用了Galera library,一个通用的用于事务型应用的同步、多主复制插件)。
传统的主从复制
RP即Replication,主从复制。
即只能从主到从进行同步,采用主写副读,只有主节点有事务。

1.Master将用户对数据库更新的操作以二进制格式保存到 Binary Log日志文件中
2.Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
3.Master接收到来自Slave的IO进程的请求后,通过负责复制的I0进程根据请求信息读取制定日志指定位置之后的日志信息,返回给 Slave 的IO进程。
返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
4.Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”;
5.Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
RP方式下如果主节点没有同步到从节点,会出现数据不一致性
Replication这种方案不会牺牲性能,但是有个问题就是非强一致性,例如你在DB1中写入数据可能会因为网络抖动在DB2中查询不到数据,这时候客户端接收到的状态是已经操作成功。
另外有一点是这种集群方案只能在一个节点中做写入操作,因为他的底层同步原理是单向同步的。
PXC的副本复制
PXC最大的优势:强一致性、无同步延迟
图解:PXC的事务执行流程

这里我们用PXC中3个DB节点来介绍其原理,分别是DB1 DB3 和DB3, 数据的同步使用PXC。
先从clent说起 clent在执行insert del update 的时候,正常db1会给我们返回执行的结果,如果我们不提交事务的话是不能持久化到数据库中的,我们想要真实的持久化就必须要提交事务。
这里在提交事务的时候不仅仅要在当前节点里面持久化数据还要在其他节点持久化数据,毕竟我们是在pxc环境中操作的。
首先在提交事务的时候,db1会把数据传递给pxc,pxc会复制当前节点的数据,然后分发给DB2和DB3,分发后要做的就是持久化这些数据。
事务的执行操作在pxc中会生产一个GTID编号,然后由db2 和db3去分别执行这个事务,每个db执行完成后会把结果返回给db1,然后db1收到其他db的执行结果后在本地也执行一下GTID的这个事务,db1执行完成后没问题的话最终会把执行的结果返回给客户端。
通过这个时序图我们可以知道在pxc中的数据强一致,肯定是所有的数据库中的数据都是一致的。
PXC中重要概念
首先要规范集群中节点的数量,整个集群节点数控制在最少3个、最多8个的范围内。
最少3个是为了防止脑裂现象,因为只有在两个节点的情况下才会出现脑裂。脑裂的表现就是输出任何命令,返回结果都是unkown command。
当一个新节点要加入PXC集群的时候,需要从集群中各节点里选举出一个doner节点作为全量数据的贡献者。PXC有两种节点的数据传输方式,一种叫SST全量传输,另一种叫IST增量传输。
SST:全量同步
IST:增量同步State Snapshot Transfer(SST) 全量传输
Incremental state Transfer(IST)增量传输
SST传输有XtraBackup、mysqldump、rsync三种方式,而增量传输只有XtraBackup。
一般数据量不大的时候可以使用SST作为全量传输,但也只使用XtraBackup方式。
节点在集群中,会因新节点的加入或故障,同步失效等而发生状态的切换,下面列举出这些状态的含义:
- open:节点启动成功,尝试连接到集群;
- primary:节点已在集群中,在新节点加入集群时,选取donor进行数据同步时会产生式的状态;
- joiner:节点处于等待接收同步数据文件的状态;
- joined:节点已完成了数据同步,尝试保持和集群中其它节点进度一致;
- synced:节点正常提供服务的状态,表示已经同步完成并和集群进度保持一致;
- doner:节点处于为新加入节点提供全量数据时的状态;
PXC中重要端口
306:数据库对外服务的端口号
4444:请求SST(全量同步),在新节点加入时起做用
4567:组成员之间沟通的端口
4568:传输IST(增量同步),节点下线,重启加入时起做用
详解:PXC的执行流程
PXC的操作流程大体是这样的:
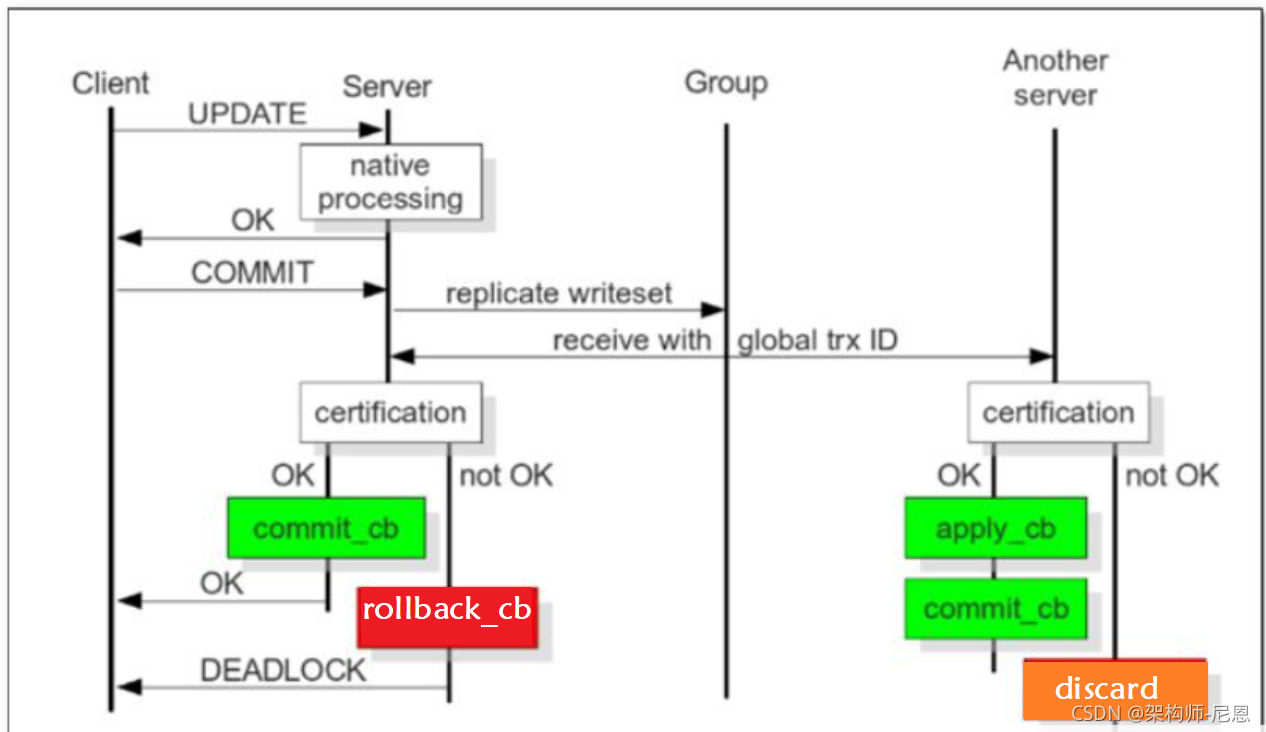
说明:图中的 cb==commit block 提交数据块
从上图能够看出:
当client端执行dml操做时,将操做发给server,server的native进程处理请求。由该server将需要产生的replication writeset广播出去,然后获取全局事务ID,一并传送到其它的节点上去。
这里,有点类似于seata 的原理,具体参见我的分布式事务以及seata 实操视频。
client端执行commit,server将复制写数据集发给group(cluster),cluster 中每一个动做对应一个GTID,其它server接收到并经过验证(合并数据)后,发现没有冲突数据,执行appyl_cb动做和commit_cb动做,若没经过,则会退出处理,就discard此次事务;
而当前节点(客户端请求的写入节点)通过验证之后,执行commit_cb操作,并返回OK给客户端。如果验证没有通过,则rollback_cb。
在生产线上的PXC集群中,至少要有三台节点。
如果其中一个节点没有验证通过,出现了数据冲突,那么此时采取的方式就是将出现数据不一致的节点踢出集群,而且它会自动执行shutdown命令来自动关机。
每一个节点都可以读写. WriteSet写的集合,用箱子推给Group里所有的成员, data page 相当于物理复制,而不是发日志,就是一个写的结果了
用户发起Commit,在收到Ok之前, 集群每次发起一个动作,都会有一个唯一的编号 , PXC独有的Global Trx Id
动作发起者: commit_cb, 其它节点多了一个动作: apply_cb
如果主节点写入过大, apply_cb 时间会不会跟不上, wsrep_slave_threads参数用于解决apply_cb跟不上问题 配置成和CPU的个数相等或是1.5倍,当前节点commit_cb 后就可以返回了。
有关端口
上面的这些事务动作,是通过那个端号交互的?4567
4568 端口 IST(增量同步) 只是在节点下线,重启加入那一个时间有用。
4444 只会在新节点加入进来时起作用,SST(增量同步)
PXC的启动关闭流程
State Snapshot Transfer(SST),每个节点都有一份独立的数据,当我们用mysql bootstrap-pxc启动第一个节点,在第一个节点上把帐号初始化,其它节点启动后加入进来。
集群中有哪些节点是由以下的参数决定:
wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx
第一个节点把自己备份一下(snapshot)传给加入的新节点,第三个节点的死活是由前两个节点投票决定。
状态机变化阶段:
1.OPEN: 节点启动成功,尝试连接到集群,如果失败则根据配置退出或创建新的集群
2.PRIMARY: 节点处于集群PC中,尝试从集群中选取donor进行数据同步
3.JOINER: 节点处于等待接收/接收数据文件状态,数据传输完成后在本地加载数据
4.JOINED: 节点完成数据同步工作,尝试保持和集群进度一致
5.SYNCED:节点正常提供服务:数据的读写,集群数据的同步,新加入节点的sst请求
6.DONOR(贡献数据者):节点处于为新节点准备或传输集群全量数据状态,对客户端不可用。
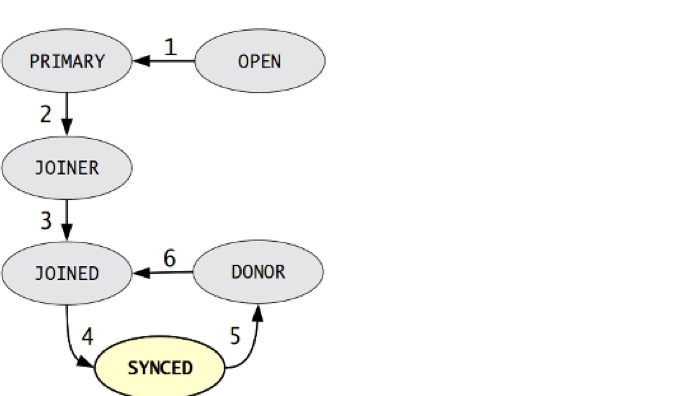
状态机变化因素:
1.新节点加入集群
2.节点故障恢复
3.节点同步失效
第一个节点启动
当我们启动第一个节点, bootstrap-pxc
当前集群没有其它成员,你就是老大了。
新启动的节点的状态-> open ->primary
在第一个节点上可以把帐号初始化, 基本初始化,都搞定了。
初始化的时间,随便那个节点都可以。
其他节点加入
其它节点再起来就是要加入进来的。
wsrep_cluster_address = gcomm://xxxx,,xxxx,xxx
新启动的节点的状态-> open ->primary -> joiner
你是新成员,你没有ID,第一个节点 把自已备份一下(snapshot) 传给加入的新节点: SST
传输SST有几种方法:
mysqldump
xtrabackup
rsync
停机重启后增量同步
当node3停机重启后,通过IST来同步增量数据,来完成保证与node1和node2的数据一致,
IST的实现是由wsrep_provider_options="gcache.size=1G"参数决定,一般设置为1G大,参数大小是由什么决定的,根据停机时间,若停机一小时,需要确认1小时内产生多大的binlog来算出参数大小。
避免全部SST
假设我们三个节点都关闭了,会发生什么呢
全部传SST,因为gcache数据没了
全部关闭需要采用滚动关闭方式:
1. 关闭node1,修复完后,启动加回来;
2. 关闭node2,修复完后,启动加回来;
3. ………………….,直到最后一个节点
4. 原则要保持Group里最少一个成员活着
数据库关闭之后,最会保存一个last Txid,所以启动时,先要启动最后一个关闭的节点。
总之:启动顺序和关闭顺序刚好相反。
wsrep_recover=on参数在启动时加入,用于从log中分析gtid。
怎样避免关闭和启动时数据丢失?
-
所有的节点中最少有一个在线,进行滚动重启;
-
利用主从的概念,把一个从节点转化成PXC里的节点。
PXC的分布式系统CAP类型
分布式系统的CAP理论:
C:一致性,所有的节点数据一致
A:可用性,一个或者多个节点失效,不影响服务请求
P:分区容忍性,节点间的连接失效,仍然可以处理请求
其实,任何一个分布式系统,需要满足这三个中的两个。
PXC属于CP类型
强一致性的话可以用来保存一些有价值的数据例如订单,支付等。
pxc 采用的是同步复制,事务在所有集群中要么全提交要么不提交,保证了数据的一致性。它写入数据速度慢
使用场景:
pxc方案存储高价值数据,如:账户、订单、交易数据等..
RP属于AP
非强一致性方案可以用来保存用户的操作或者用户行为浏览等数据。
replication 采用的是异步复制,无法保证数据的一致性。它写入数据速度快。
使用场景:
replication方案存储低价值数据,如:通知、日志等..
PXC高可用集群方案
这样一个最基本的PXC集群,它保证了每个节点的的数据都是一致的,
不会出现数据写入了数据库1而没有写入数据库2的情况,这种的集群在遇到单表数据量超过2000万的时候,mysql性能会受损,所以一个集群还不够.

数据切片
我们需要把数据分到另一个集群,这个称为“切片”,就是把大量的数据拆分到不同的集群中,每个集群的数据都是不一样的
看下面的截图:

这样一来,PXC集群1存前面1000万条数据,PXC集群2存后面1000万条数据
,当一个sql语句请求的时候,通过MyCat这个阿里巴巴的开源中间件,可以把sql分到不同的集群里面去。这种的分片按照数量就是2个分片。
这个切分算法也比较多,比如按照日期、月份、年份、某一列的固定值,或者最简单的按照主键值切分,主键对2求模,余0的存分片1,余1的存分片2,这样MyCat就会把2000万条数据均匀地分配到2个集群上。
PXC虽然保证了数据的强一致性,但是这是以牺牲性能为代价的,所以适合保存重要的数据,比如订单。
shardingJdbc
使用shardingJdbc,也是一样的,推荐使用sharding jdbc,具体请看我的 10Wqps架构视频

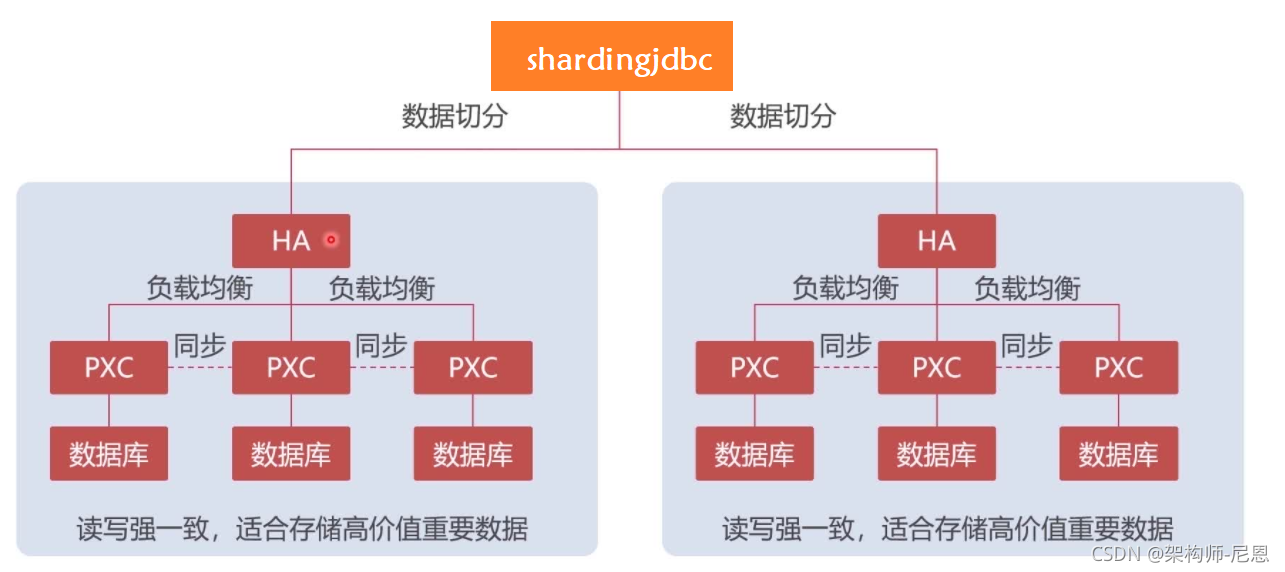
Replication集群方案

这种集群,在第一个节点插入以后,就马上返回给客户端执行成功了,然后再做每个节点之间的同步,如果某一个同步操作失败了,那用户请求的时候拿到的数据就不同步了,但是它的优势是速度快,不会牺牲任何地性能,适合保存不那么重要的数据,比如日志。
PXC与Replication集群结合

使用shardingJdbc,也是一样的,推荐使用sharding jdbc,具体请看我的 10Wqps架构视频

PXC优缺点
优点:
1)同步复制,事务要么在所有节点提交或不提交。
2)多主复制,可以在任意节点进行写操作。 由于是多节点写入,所以DB故障切换很容易。完成了真正的多节点读写的集群方案;
3)在从服务器上并行应用事件,真正意义上的并行复制。 改善了主从复制延迟问题,基本上达到了实时同步;
4)节点自动配置,数据一致性,不再是异步复制。 新加入的节点可以自动部署,无需提交手动备份,维护方便;
PXC最大的优势:强一致性、实现了MySQL集群的高可用性和数据的强一致性;无同步延迟。
缺点:
加入新节点时开销大。
添加新节点时,必须从现有节点之一复制完整数据集。如果是100GB,则复制100GB。
任何更新的事务都需要全局验证通过,才会在其他节点上执行,集群性能受限于性能最差的节点,也就说常说的木桶定律。
锁冲突的问题
因为需要保证数据的一致性,PXC采用的实时基于存储引擎层来实现同步复制,所以在多节点并发写入时,锁冲突问题比较严重。
写扩大的问题
存在写扩大的问题。所以节点上都会发生写操作,对于写负载过大的场景,不推荐使用PXC。
生成的ID不连续
在PXC中,生成的ID有可能是不连续的,如果期望连续就需要将ID生成策略提高一级,比如放在数据切分中间件中,如mycat等。
或者在程序中执行ID的赋予问题。
脑裂问题
PXC集群数量建议为奇数,防止脑裂。
任何命令执行出现unkown command ,表示出现脑裂,集群两节点间4567端口连不通,无法提供对外服务。
并发写
三个节点的自增起始值为1、2、3,步长都为3,解决了insert问题,但update同时对一行操作就会有问题,出现:Error: 1213SQLSTATE: 40001,所以更新和写入在一个节点上操作。
pxc结构里面必须有主键
如果没有主建,有可能会造成集中每个节点的Data page里的数据不一样
不支持表级锁
不支持lock /unlock tables
不支持XA事务
这点可以使用seaa
性能符合水桶原理
性能由集群中性能最差的节点决定
参考文献:
https://www.cnblogs.com/peng-zone/p/11676678.html#pxc原理图
https://www.jianshu.com/p/47054c12afa7