国内的数据结构教材一般是按照Knuth定义,即“阶”定义为一个节点的子节点数目的最大值。

对于一棵m阶B-tree,每个结点至多可以拥有m个子结点。各结点的关键字和可以拥有的子结点数都有限制
规定m阶B-tree中,
根结点至少有2个子结点,除非根结点为叶子节点,相应的,根结点中关键字的个数为1~m-1,比节点数目少一个;
非根结点至少有[m/2]([],向上取整)个子结点,相应的,关键字个数为[m/2]-1~m-1。
order是阶数的意思

所有的叶子结点都位于同一层
在B-树中,每个结点中关键字从小到大排列
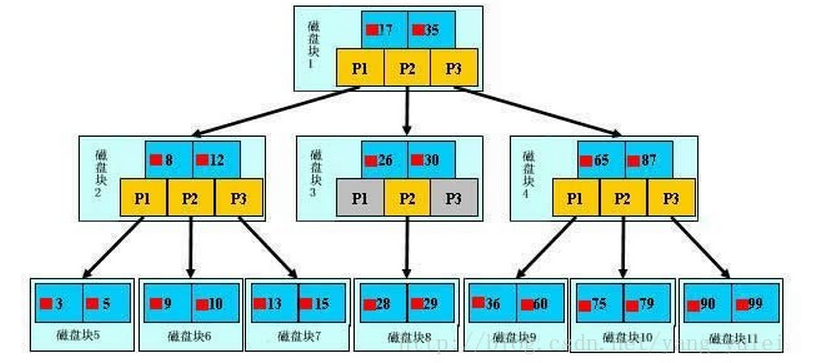
下面,咱们来模拟下查找文件29的过程:
1. 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
2. 此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据(3个子节点)。根据算法我们发现:17<29<35,因此我们找到指针p2。
3. 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
4. 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30(与关键字比较),因此我们找到指针p2。
5. 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
6. 此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。分析上面的过程,发现需要3 3次磁盘IO操作和次磁盘IO操作和3次内存查找 次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
——————————————————————
理解慢