1.这篇论文的主要假设是什么?(在什么情况下是有效的),这假设在现实中有多容易成立
LR图像是HR图像经过模糊(低通滤波器),下采样,加噪处理后的图像。
2.在这些假设下,这篇论文有什么好处
3.这些好处主要表现在哪些公式的哪些项目的简化上。
4.这一派的主要缺点有哪些
1.神经网络的计算速度却决于输入图像的尺寸。由于卷积层是在HR空间中,计算复杂度大
2.插值法仅仅是将尺寸放大,并没有带来解决不适定的重建问题的额外信息。(ESPCN,3)
3.非线性映射层计算复杂度高
4.依赖于小图像区域的上下文(VDSR,1)
5.一个网络只能对应一个scale(VDSR,1)
1.intro
图像超分辨率问题是在CV领域一个经典的问题。目前(2014)最先进的方法大多是基于实例的,主要包括利用图片的内部相似性,或者学习低分辨率高分辨率样本对的映射函数。后者往往需要大量的数据,但是目前有效性不足以令人满意并且无法精简模型。其中典型的是基于稀疏编码的方法,包括以下几步:先从图像中密集地抽取patch并进行预处理,然后使用low-resolution dict对patch进行编码,得到稀疏的coefficients,被换成high-resolution dict用于重建高分辨率patch,对这些patch进行合成或平均以得到高分辨率图像。这些方法将注意力都集中在对dict的学习和优化或者其他建模方法,其余步骤很少得到优化和考虑。
本篇文章我们提出,上述步骤作用相当于一个卷积神经网络。我们考虑直接在高低分辨率图像中建立一个端到端映射的CNN,用隐藏层取代对dict的学习。在这个过程中,patch的抽取和聚合也能够得到应有的优化。这就是SRCNN,其有以下优点:1.模型简单,精度高。2.速度快。3.随着数据集的增大,重建质量还可以增强。但是在以往方法中,数据集增大会带来很多挑战。
本文主要工作:
1.针对超分辨问题提出一个基于端到端映射的卷积神经网络,图像预处理后处理更少。
2.基于深度学习的SR方法和传统的基于稀疏编码方法的比较。
3.论证了深度学习在SR问题中可以被应用,且可以获得较好的质量和速度。
2.related work
2.1 图像超分辨
一类图像超分辨方法时学习高低分辨率patch间的映射,这些工作的主要区别在于学习一些将高低分辨率patch关联起来的dict和manifold space方面,和如何在此空间内进行方案表示方面。
Freeman的工作:dict里的元素直接代表高低分辨率的patch对,在低分辨率空间中找到input patch的最近邻居(NN),对应到相应的高分辨率patch。
Chang的工作:使用manifold embedding technique代替NN策略
Yang的工作:NN对应进展到更为先进的稀疏编码方式。这种稀疏编码方式及其改进是目前最先进的SR方法。
2.2 CNN
CNN最近因其在图像分类领域的成功而变得火热。
2.3 图像复原领域的深度学习
已经有一些使用深度学习技术在图像复原领域应用的例子:多层感知机用于自然图像去噪和post-deblurring去噪,CNN用于自然图像去噪和消除噪声图案。图像超分领域还并未得到应用。
3.SRCNN
3.1 构思
将原始图像通过插值,扩展到插值图像Y,我们的目标就是将Y经过F(Y)变换,尽可能地接近高分辨图像X。方便起见,我们将Y成为低分图像,尽管其尺寸与X相等。
1.patch(图像块)抽取与表示。将Y中的每一图像块抽取出来并表示为高维向量,这些高维向量包括一系列特征图,特征图的个数等于高维向量的维度。
2.非线性映射。将上一步得到的每一高维向量进行非线性映射,得到另一个高维向量。得到的高维向量代表高分辨图像的patch,这些高维向量也包括一系列特征图。
3.重建。聚合上步得到的高分辨图像patch,得到最终的高分图像
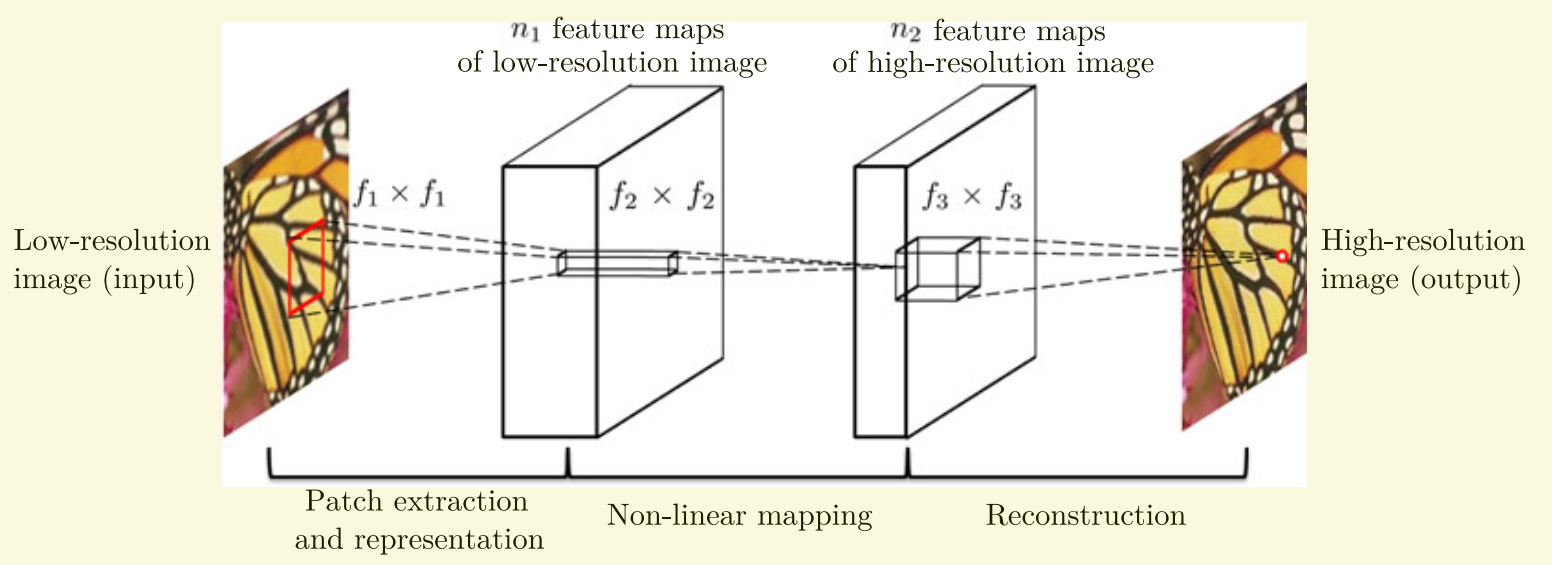
patch(图像块)抽取与表示
深度学习之前的常用策略是密集抽取patch并用一组基来表示(如PCA,DCT,Haer)。这个过程等价于使用一组filter(每一个filter相当于一个基)对图像进行卷积。这在此网络中表示为进行卷积操作$$F_{1}left ( Y ight )=maxleft ( 0,W_{1}*Y+B_{1} ight )$$
其中$W_{1}$的尺寸是$c imes f_{1} imes f_{1} imes n_{1}$,$B_{1}$是$n_{1}$维向量。在这之后应用一个RELU单元(RELU相当于非线性映射,而patch的提取和表示是纯线性操作)
非线性映射
上一步得到的得到的每一个$n_{1}$维向量对应于原始图像中的一个patch,将得到的$n_{1}$维向量映射到$n_{2}$维向量,这在此网络中表示为进行卷积操作$$F_{2}left ( Y ight )=maxleft ( 0,W_{2}*F_{1}left ( Y ight )+B_{2} ight )$$
其中$W_{2}$的尺寸是$n_{1} imes 1 imes1 imes n_{2}$,$B_{2}$是$n_{2}$维向量
注:可以增加额外的卷积层来增加网络的非线性,但也需要考虑因此带来的问题。
重建
在传统方法中,往往将高分patch进行average以产生最终图像。这一平均操作可以替换为:使一系列特征图通过我们预定义好的滤波器。
这在此网络中表示为进行卷积操作$$Fleft ( Y ight )=W_{3}*F_{2}left ( Y ight )+B_{3} $$
其中$W_{3}$的尺寸是$n_{2} imes f_{3} imesf_{3} imes c$,$B_{3}$是$c$维向量
如果代表HR patch的$n_{2}$维向量是在图像域,则直接把第三次的filter看成一个averaging filter;如果是在其他域,则可以理解为第三层先将系数转换到了图像域继而进行average。
3.2 和稀疏编码方法的关系
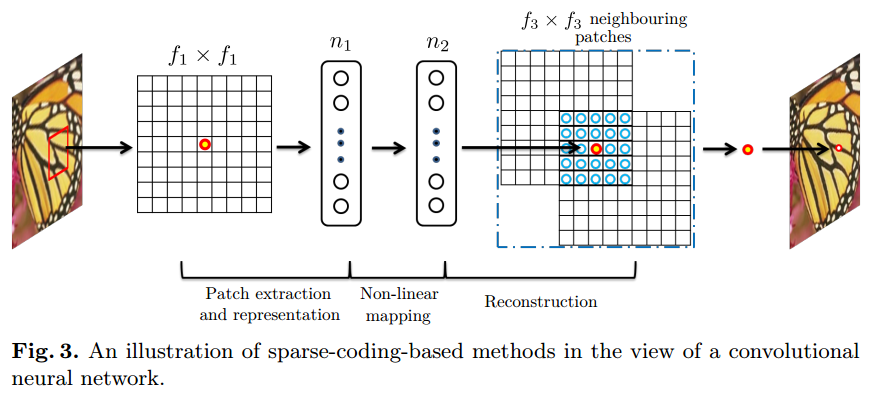
在稀疏编码中,考虑从原始图像中抽取$f_{1} imes f_{1}$的LR图像块,这一图像块减掉其均值后被投影到LR字典中。若LR字典大小为$n_{1}$,则这正相当于$n_{1}$个$f_{1} imes f_{1}$线性filter。(减均值操作包括在线性操作中)
the sparse coding solver对$n_{1}$个系数进行非线性映射操作,输出是$n_{2}$个系数,这$n_{2}$个系数代表HR patch。但是这一步骤并不是feed-forward,而是iterative。然而在CNN中的操作却是feed-forward,而且便于计算,此操作可以看做是像素层面的全连接网络。
(针对这里的pixel-wise fully-connected layer, 个人理解:应该说的是前后两组feature maps中对应patch的特征进行全连接,而不是对patch进行全连接。在这里的“像素”应该指的是代表patch的高维向量的每一个维度)
之后,$n_{2}$个系数通过HR字典投影到HR图像块,之后进行average操作。这等效于在$n_{2}$特征图上进行线性卷积。如果用来重建的patch尺寸为$f_{3} imes f_{3}$, 则卷积操作的filter也是$f_{3} imes f_{3}$
以上这些说明了,我们可以用CNN代替传统的稀疏编码,而且CNN能够对所有步骤进行优化。
我们设置的超参数是f1 = 9, f3 = 5, n1 = 64, and n2 = 32
若设置最后一层filter<第一层,则我们更多地依赖于HR patch的中心部分; 为了达到稀疏的目的,也可以设置n2 < n1。
相比于传统方法更精确的原因之一是,此模型中HR像素的感受野大。(每一像素利用了$left ( 9+5-1 ight )^{2}=169$个原始像素的信息)
3.3 训练
3.3.1 LOSS函数
MSE损失$$Lleft ( Theta ight )=frac{1}{n}sum_{i=1}^{n}left | Fleft ( Y_{i};Theta ight )-X_{i} ight |^{2}$$
使用MSE偏好于PSNR,(PSNR是定量评估重建质量的重要指标,与感知质量也相关)。
也可在训练过程中使用更合适的LOSS函数,这点在传统SC方法是不可想象的。
3.3.2 momentun梯度下降
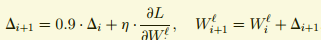
训练的输入是原始图像经过加噪、下采样,上采样。
4. 实验
数据集:训练集:91images
Set5用于2,3,4倍上采样, Set14用于4倍上采样
超参数:f1 = 9, f3 = 5, n1 = 64, and n2 = 32
ground truth尺寸:32*32pixel
将HR图片根据14stride切割成32×32子图,这样一来,91张图片共产生约24800张训练图片。
我们的图片是在YCrCb空间下,且只考虑亮度通道。因此c=1,两个色度空间不会被训练。当然,也可以设置c=3,我们设置c=1只是为了和其他方法竞争公平。
训练阶段,为了避免边缘效应,我们的卷积操作无Padding,这会导致输出尺寸是20*20,我们取ground truth中心的20*20进行LOSS函数的计算。而测试阶段有Padding,可以输入任意尺寸图片,输入尺寸不变,为了解决边界效应,在每个卷积层中,每个像素的输出(在ReLU之前)都通过有效输入像素的数量进行标准化。
filter参数被随机初始化,标准差0.001。前两层LR=10−4,最后一次LR=10-5。根据经验,最后一层LR小对于收敛很重要。
5. 分析
5.1 分析filter
训练出的不同filter对应不同功能
5.2 使用不同数据集会产生不同效果
5.3 filter数量
可以改变层数和filter的数量,来产生不同效果,然而效果的提升意味着牺牲速度的代价
5.4 filter尺寸。同5.3
5.总结
添加更多的layer或者filter可以得到不同效果
也可以探索一种网络来应对不同的上采样倍数。