一、表分区partition
指根据一定的规则,数据库把一个表分解成更多个小的、更容易管理的部分。逻辑上只有一个表或者一个索引,但实际上这个表可能由数个10个物理分区对象组成,每个分区都是一个独立的对象,可以独自处理,可以作为表的一部分进行处理。
注意:
同一个分区表的所有分区必须使用同一个存储引擎,但是对于不同的分区表可以使用不同的存储引擎。
不能只对表数据分区而不对索引分区,反之亦然。
# 查看是否支持分区
Show variables like ‘%partition%’
Show plugins 命令 查看是否安装分区插件等信息
当一张表的数据非常多的时候,比如单个.myd文件都达到10G, 这时,必然读取起来效率降低.
可不可以把表的数据分开在几张表上?
1: 从业务角度可以解决. (分表)
比如, 通过id%10 , user0 , user1....user9, 这10张表
根据不同的余数,来插入或查询某张表.
2: 通过mysql的分区功能
mysql将会根据指定的规则,把数据放在不同的表文件上.
相当于在文件上看,被拆成了数小块.
但是,给客户的界面,还是1张表.
常用的规则:
根据某列的范围来分区, 也可以某列的散点值来分区.
示例: 按列的范围来分区
以用户表为例, uid
uid [1,10) ---> user partition u1
uid[10, 20) ---> user partition u2
uid [20, MAX] --> user partion u3
二、分区类型
Range、list、 hash 、key分区
无论哪种分区类型,要么分区表上没有主键/唯一键,要么分区表的主键/唯一键都必须包含分区键,也就是说不能使用主键/唯一键字段之外的其他字段分区。
在5.1版本,range、list、hash分区都要求分区键必须是int类型,或者通过表达式返回int类型,唯一例外的是key分区,可以使用其他类型的列(bolb或text列类型除外)作为分区键。
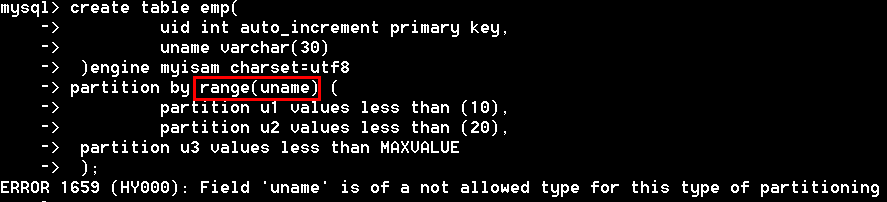
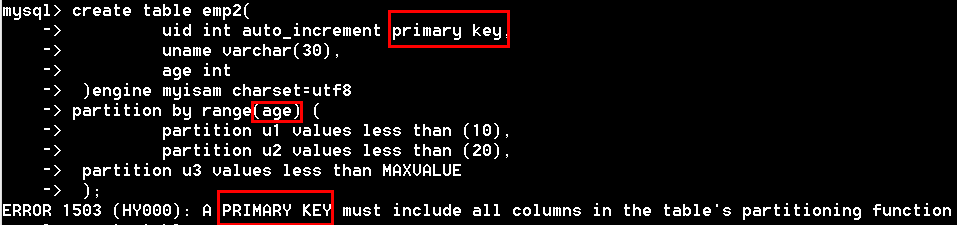
5.5以上版本中,已经支持非整数的range分区和list分区,新支持的columns分区,细分为 range columns 分区和 list columns 分区,都支持整数、日期时间、字符串三大数据类型。
按range分区
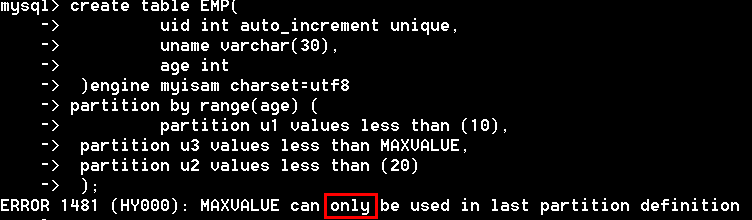
利用取值范围将数据分区,基于一个给定连续区间范围,把数据分配到不同的分区,区间要连续并且不能互相重叠,使用values less than操作符进行分区定义,values less than maxvalue子句提供给所有大于明确指定的最高值的值,maxvalue表示最大的可能的整数值。
range分区键如果是null值会被当做一个最小值来处理。
每个分区都是按顺序进行定义,从最低到最高。
partition by range columns(uname) # 提供range columns分区支持非整数分区
create table emp(
uid int auto_increment primary key,
uname varchar(30)
)engine myisam charset=utf8
partition by range(uid) (
partition u1 values less than (10),
partition u2 values less than (20),
partition u3 values less than MAXVALUE
);

适用情况:
- 删除过期数据, alter table emp drop partition u1 来删除u1分区中的数据,大数据下比delete来的快。
- 经常运行包含分区键的查询,可以很快的确定只有某一个或某些分区需要扫描
Explain partitions select statement
按散点list值分区
类似range分区,区别在list分区是基于枚举出的值列表分区,即特定的值属于哪个分区,而range是基于给定的连续区间范围分区;
partiton by list (expr)子句实行,expr是某列值或一个基于某列值返回一个整数值的表达式,然后通过values in (value_list) 的方式来定义分区,其中value_list是一个逗号分隔的整数列表。
partiton by list columns (expr) #支持非整数分区
create table emp_list (
uid int,
pid int,
uname varchar(30)
)engine myisam
partition by list(pid) (
partition bj values in (1),
partition ah values in (2),
partition xb values in (4,5,6)
);
注意:
在使用分区的时候,注意,分区的那个列,值不要为NULL (如果不小心为NULL,mysql为理解为0,尽量执行之)
插入的列值必须包含在分区值列表中,否则报错
注 :分区甚至可以按照表达式的返回值,计算所属区.
但用表达式,不如直接用值来得快. 根据情况而定.
比如,用 partition by range (year(regtime)) 可以按注册年份来分区.
按hash分区
基于给定的分区个数,把数据分配到不同的分区。确保数据在预先确定个数的分区中尽可能平均分配。使用partition by hash (expr) partitions num子句对分区类型、分区键和分区个数进行定义。Expr是某列值或一个基于某列值返回一个整数值的表达式,num是一个非负的整数,表示分割成分区的数量,默认为1.
create table emp_hash(
uid int auto_increment primary key,
uname varchar(30),
age int
)engine myisam charset=utf8
partition by hash(uid) partitions 6;
支持两种hash分区,常规hash分区和线性hash分区;
常规hash:使用的是取模算法
例如:有4个分区,插入一个uid=234的记录到表中,MOD( 234, 6)=2,则记录会被保存在第二个分区;
但有个弊端,如果新增一个分区后,会重新计算重新分区,带来性能上的高消耗
线性hash:线性的2的幂的运算法则
语法: PATITION BY LINEAR HASH (exp) PARTITIONS num;
声明: num = 4 column_list = 234
1、先找到下一个大于等于 num 的 2 的幂,设为V
V = Power ( 2, Ceilling ( Log ( 2, num ) ) ) = 4
2、其次,设置 N=F( column_list ) & ( V -1 ) = 234 & (4 -1) = 2
3、当 N >= num 时设置 V= Ceiling(V/2),设置 N = N &(V-1)
综上:对于 uid =234,N =2 < 4 ,保存在第二个分区
在分区维护(增加、删除、合并、拆分分区)时,处理的更加迅速;但对比常规hash,各数据之间的分布不太均衡。
按key分区
类似于hash分区,在处理大数据记录时,能够有效地分散热点。支持除BLOB or Text类型外其他类型的列作为分区键,Partition by key(exp)子句来创建一个key分区表,expr是零个或者多个字段名名的列表。与hash分区不同,创建key分区表的时候,可以不指定分区键,默认会首先选择使用主键作为分区键,没有主键的情况,会选择非空唯一键为分区键。也支持LINEAR 关键字。
三、子分区
分区表中对每个分区的再次分割,又称为复合分区。
用于保存非常大量的数据记录。
四、分区管理
1.Range & List分区:
Alter table drop partition 分区名; #删除一个分区。
Alter table add partition (子句); #增加一个分区
比如:Alter table add partition (partition p7 values less than(xxx));
Alter table reorganize partition p0[,p1,p2…] into ( 子句 ) #重新定义分区
2.Hash & KEY分区
Alter table coalesce partition num; # 不能删,只能合并hash分区或key分区,也不能通过这个命令增加
Alter table add partition partitions num; #增加num个分区