递归是很多算法都使用的一种编程方法。
如计算5的阶乘:
5!=5*4!=5*4*3!=5*4*3*2!=5*4*3*2*1
如果用factorial(n)表示阶乘,那么factorial(5)=factorial(4)*5=factorial(3)*4*5=factorial(2)*3*4*5=factorial(1)*2*3*4*5。
如此不断的调用执行factorial(n)就是递归。
1.1 递归
祖母留下一个手提箱,手提箱的钥匙在一个盒子中,而这个盒子里又有盒子。
问题:使用什么算法,找到钥匙?
方法一:
- 1.创建一个要查找的盒子堆
- 2.从盒子堆中取出一个盒子,在里面找
- 3.如果找到的是盒子,就将其加入盒子堆中,以便以后再查找,原盒子抛弃;返回第2步
- 4.如果找到钥匙,大功告成,不再查找
def look_for_key(main_box):
pile=main_box."建立一个盒子堆"
while pile is not empty:
box = pile.grab_a_box()
for item in box:
if item.是盒子:
pile.append(item)
elif item.是钥匙:
print("钥匙找到了")
方法二:
- 1.检查盒子的每样东西
- 2.如果是盒子,就回到第一步
- 3.如果是盒子,就大功告成
def look_for_key(box):
for item in box:
if item.是盒子:
look_for_key(item)
elif item.是钥匙:
print("钥匙找到了")
这两种方法的作用相同,但方法二更清晰。递归只是让解决方案更清晰,并没有性能上的优势。实际上,在有些情况下,使用循环的性能更好。
某大佬曾经说过:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能更容易理解。”
1.2 基线条件和递归条件
由于递归函数调用自己,因此编写这样的函数时很容易出错,可能导致死循环。
#倒计时
def countDown(i):
print(i)
countDown(i-1)
因此编写递归函数是,必须告诉他何时停止递归。因此每个递归函数都有两部分:基线条件和递归条件。递归条件指的是函数调用自己,而基线条件则指的是函数不在调用自己,从而避免形成死循环。
def countDown(i):
print(i)
if(i<=1): #基线条件
return
else: #递归条件
countDown(i-1)
1.3 栈
栈是一种简单的数据结构,先进先出。
1.3.1 调用栈
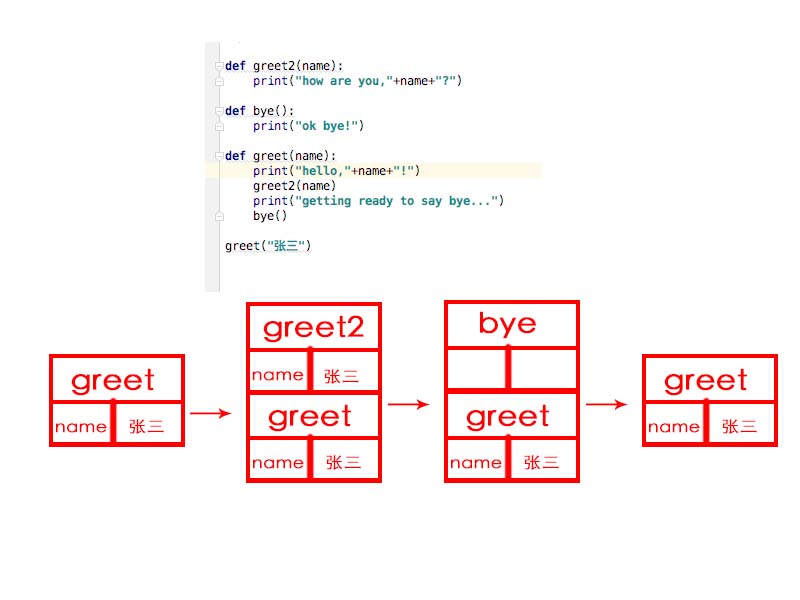
1.调用greet时,计算机首先为该函数的调用分配一块内存到栈中,变量name被设置为张三,需要存储到内存栈中。
2.执行到调用greet2函数时,计算机同样为这个函数调用分配一块内存到栈中。当greet2执行完毕,greet2内存块从栈中被弹出。
3.回到greet函数,然后执行到bye函数,在栈顶添加了bye的内存块到栈中,当bye执行完毕后,bye内存块从栈中被弹出。
4.回到greet函数,继续执行greet函数。执行结束,greet内存块从栈中弹出。
这个栈用于存储多个函数的变量,被称为调用栈。当调用另一个函数时,当前函数暂停并出于未完成状态。
1.3.2 递归调用栈
递归函数也适用调用栈

注意:每个fact调用都有自己的x变量。在一个函数调用中不能访问另一个的x变量。
如1.1使用递归方法寻找钥匙时,没有盒子堆,那算法怎么知道还有哪些盒子需要查找呢?
如同x一样,盒子堆存储在栈中。这个栈包含未完成的函数调用,每个函数调用都包含还未检查完的盒子。使用栈很方便,无需自己跟踪盒子堆——栈替你做了。
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,有2中选择:
- 1.放弃递归,使用循环
- 2.使用尾递归