监控业务范围
- app崩溃监控(Bugly)
- 应用性能监控(APM)
- 业务监控(TalkingData、友盟)
- 质量监控(缺位)
质量监控平台ELK
- 数据构造
- 线上错误状态分布
- 故障影响范围
- 异常接口列表和影响用户采样
- 测试进展分析
- 漏测分析
- 关联图建模分析
- 插桩技术:
- 基于编译插桩,需要植入sdk, NewRelic
- 基于dex插桩:Appetizer
- Hook: Xposed、Frida
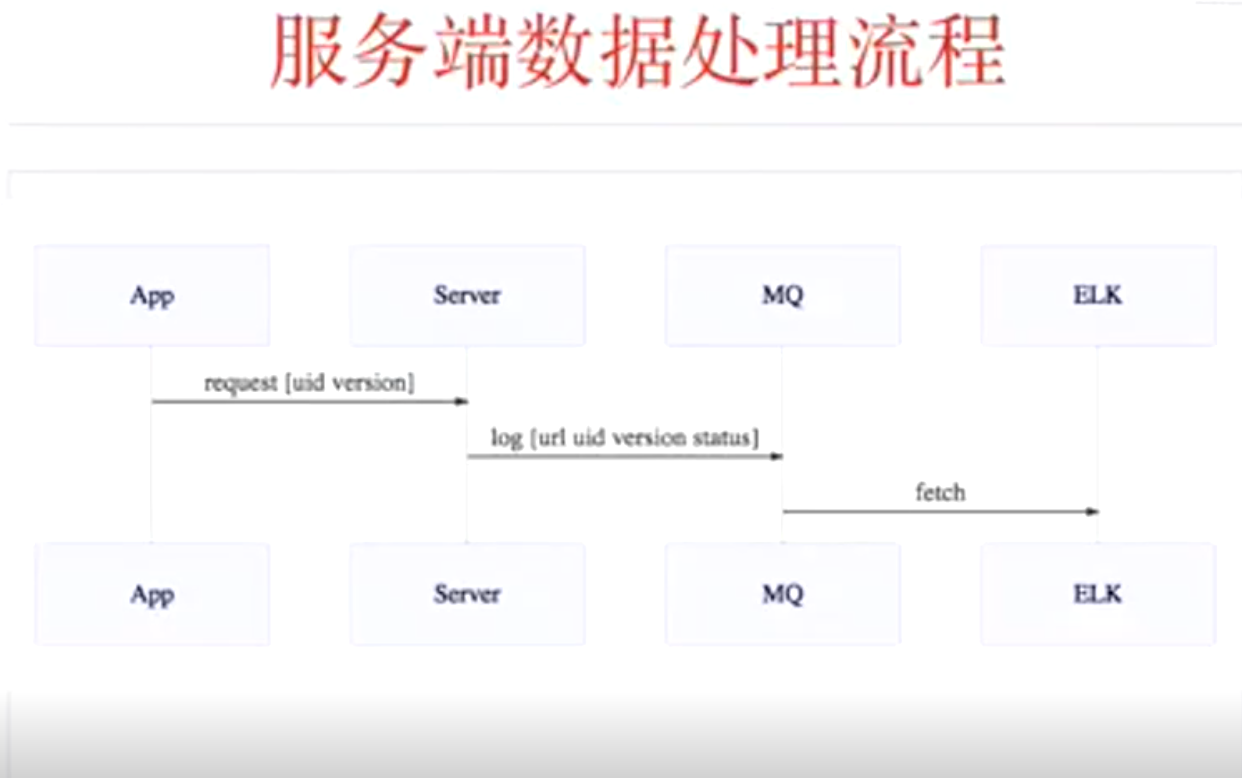
elk层级图
 https://www.elastic.co/guide/cn/elasticsearch/guide/current/intro.html
## 1.安装方法:
* ELK镜像 [https://store.docker.com/community/images/sebp/elk](https://store.docker.com/community/images/sebp/elk)
* 文档:[https://elk-docker.readthedocs.io/](https://elk-docker.readthedocs.io/)
* 方法1: docker pull sebp/elk
* 方法2: docker pull registry.docker-cn.com/sebp/elk
https://www.elastic.co/guide/cn/elasticsearch/guide/current/intro.html
## 1.安装方法:
* ELK镜像 [https://store.docker.com/community/images/sebp/elk](https://store.docker.com/community/images/sebp/elk)
* 文档:[https://elk-docker.readthedocs.io/](https://elk-docker.readthedocs.io/)
* 方法1: docker pull sebp/elk
* 方法2: docker pull registry.docker-cn.com/sebp/elk
2.开始运行elk
2.1准备条件
https://elk-docker.readthedocs.io/

注意:
A minimum of 4GB RAM assigned to Docker dokcer需要4G内存,
Elasticsearch alone needs at least 2GB of RAM to run. Elasticsearch至少需要2G
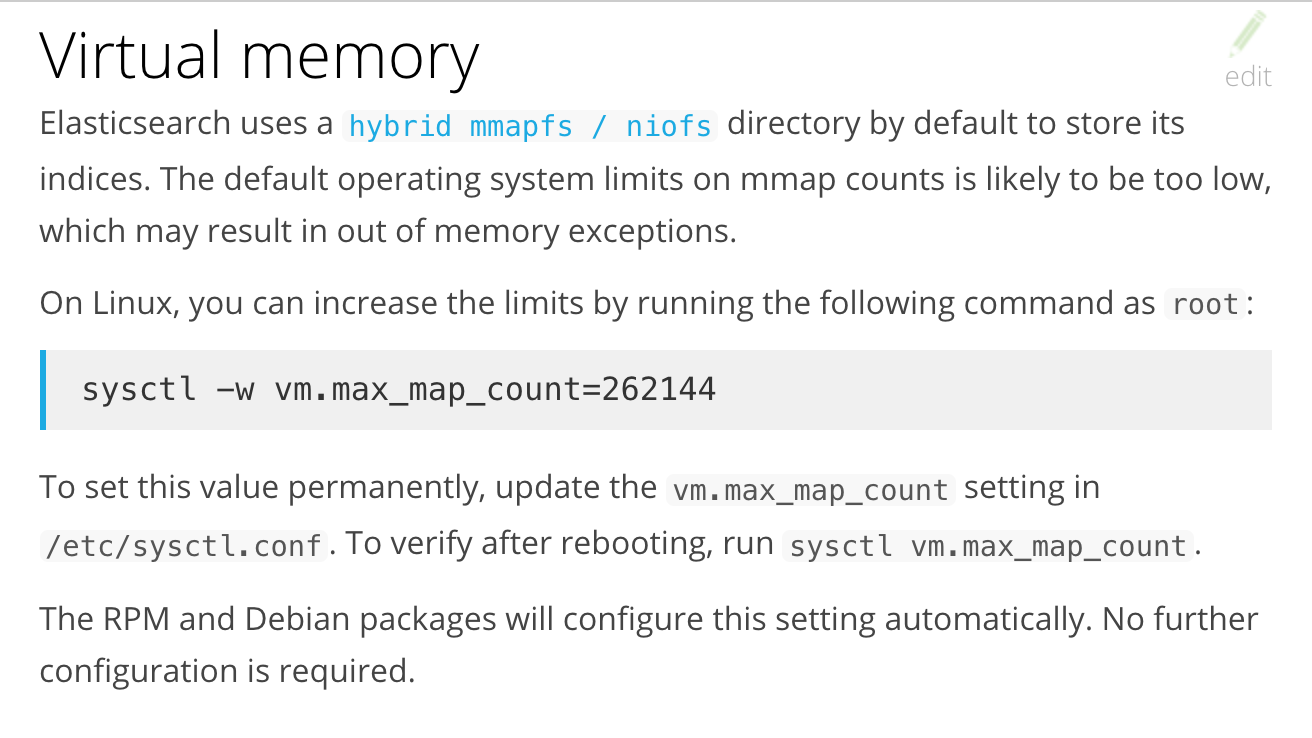
Mac只需要修改docker配置项即可
Linux需要更改虚拟内存配置项vm.max_map_count。
- 1.临时更改:sysctl -w vm.max_map_count=262144
- 2.永久更改:修改配置文件/etc/sysctl.conf
2.2 启动
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -d --name elk sebp/elk
3通过交互页面直接输入
此时会将input的内容,当作日志输出
方法1:进入elk终端,进入日志输入命令行
docker exec -it e4d3aa4921b6 /bin/bash
/opt/logstash/bin/logstash --path.data /tmp/logstash/data -e 'input { stdin { } } output { elasticsearch { hosts => ["localhost"] } }'
此时输入任意文字
<img src="https://img2018.cnblogs.com/blog/1418970/201810/1418970-20181028123636737-2098688558.png" width="600" />
<font color=458000>在Kibana中进入DIscover,然后Create index pattern,写入他所发现的索引,设置时间字段就可以创建了</font>
<img src="https://img2018.cnblogs.com/blog/1418970/201810/1418970-20181030200757330-910062420.png" width="300"/>
<img src="https://img2018.cnblogs.com/blog/1418970/201810/1418970-20181030200831307-2104612055.png" width="300" />
输入文字后,会有新的log打印。查看任意一条log,详细信息如下。
<img src="https://img2018.cnblogs.com/blog/1418970/201811/1418970-20181101071729414-2055597684.png" width="600" />
检索
<img src="https://img2018.cnblogs.com/blog/1418970/201810/1418970-20181028123804494-2054031295.png" width="600" />
### 方法2:不进入终端,直接进入日志输入命令行
docker run -it --name logstash --rm logstash --path.data /tmp/logstash/data -e 'input { stdin { type=> "doc"} } output { elasticsearch { hosts => ["172.16.40.200"] } }'
<font color=458B00>注意:此处一定要填写IP,不能填写localhost或者127.0.0.1,否则错误如下</font>
<img src="https://img2018.cnblogs.com/blog/1418970/201810/1418970-20181028132653562-1416624336.png" width="600" />
## 4.批量传入本地数据
https://www.elastic.co/guide/en/logstash/current/dir-layout.html
https://www.elastic.co/guide/en/logstash/current/running-logstash-command-line.html
从命令行启动
-e, 使用文本代替配置文件,如3中交互输入
-f,配置文件 bin/logstash -f mypipeline.conf
[配置文件格式](https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html)
input:输入数据来自什么地方
filter:对输入数据做什么处理
output:输出的数据存储到什么地方去
### 4.1新建配置文件conf/csv.conf,注意IP地址:ifconfig en0
```#conf
input {
file {
path => "/data/*.csv"
start_position => beginning #从头开始读
}
}
filter {
csv{
columns =>[ "log_time", "user", "api", "status", "version"] #给文件中的每一列指定标题
}
date {
match => ["log_time", "yyyy-MM-dd HH:mm:ss"]
timezone => "Asia/Shanghai"
}
}
output {
elasticsearch {
hosts => ["172.16.40.200:9200"]
index => "logstash-chenshanju-%{+YYYY.MM.dd}"
}
}
4.2创建数据:data/demo.csv
2018-10-28 11:29:00,chenshanju,topics.json,200,7.4
2018-10-28 11:29:01,chenshanju,topics.json,200,7.4
2018-10-28 11:29:02,chenshanju,topics/3.json,200,7.4
2018-10-28 11:30:01,chenshanju,topics/4.json,200,7.4
2018-10-28 11:30:20,chenshanju,topics/1.json,200,7.4
2018-10-28 11:40:20,chenshanju,topics/5.json,200,7.4
4.3 执行
docker run -it --name logstash --rm -v $PWD/conf:/conf -v /Users/chenshanju/Desktop/docker/data/:/data logstash -f /conf/csv.conf
4.4注意
data和conf在同意目录下,命令也在该目录下执行
4.4持续日志
另开终端,执行以下脚本
#注意:此脚本不要忘记传入user
while true
do
version=$([ $((RANDOM%5)) -ge 1 ] && echo debug || echo test)
version=${version}_3.$((RANDOM%3))
userList=(chenshanju chenyi csj java python)
user=${userList[$((RANDOM%5))]}
api=api/$((RANDOM%5)).json
status=$((RANDOM%5))00
ip=192.168.0.1$((RANDOM%5))$((RANDOM%5))
echo $(date +"%Y-%m-%d %H:%M:%S"),${user},${ip},${api},${status},${version} | tee -a $(
date +%Y%m%d%H%M).csv
sleep 0.$((RANDOM%5))
done
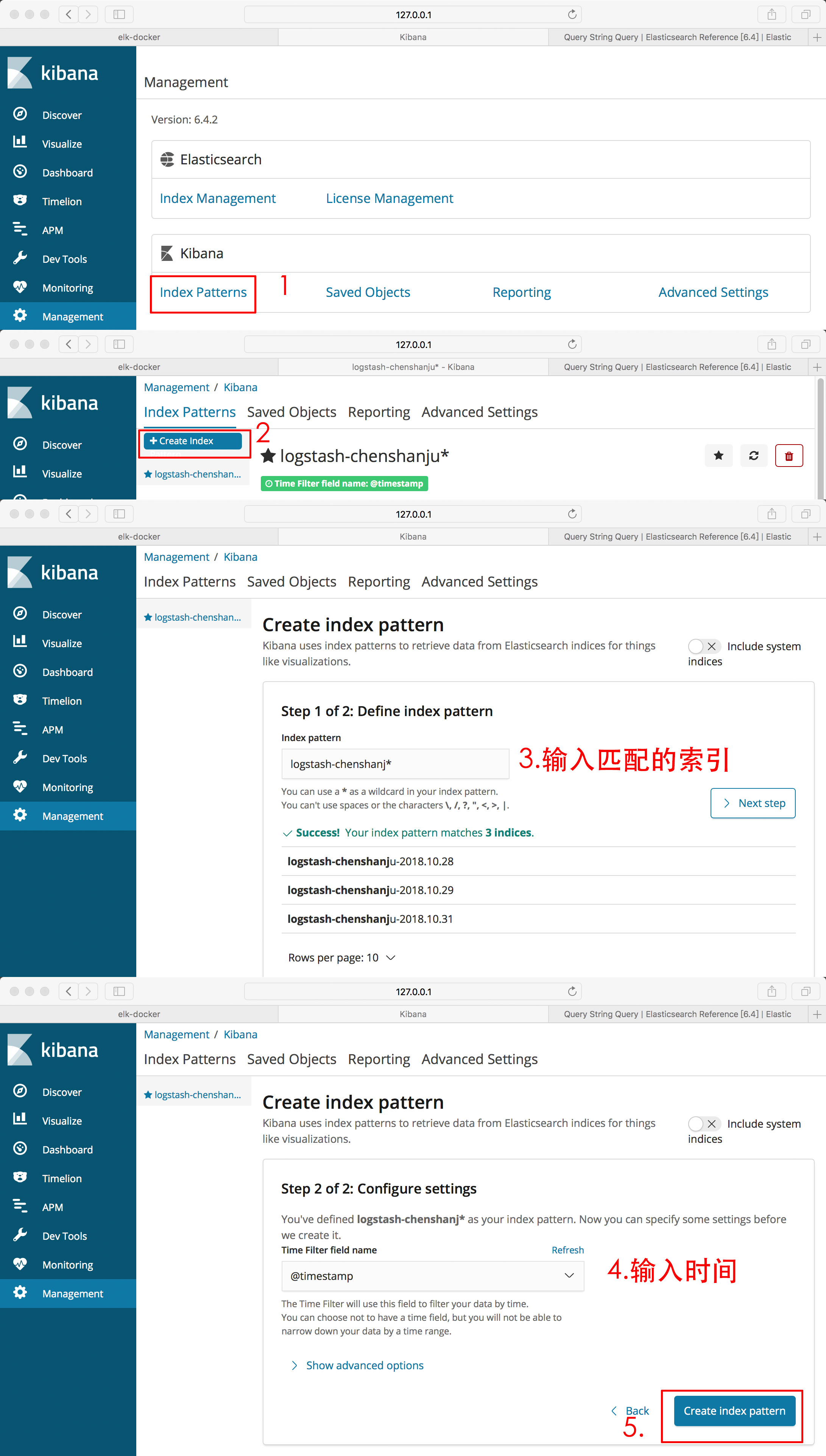
5.生成索引
在Managerment中可以管理索引,例如查看、增加、删除
- 5.1.Management-Elasticsearch-index Mangerment管理索引
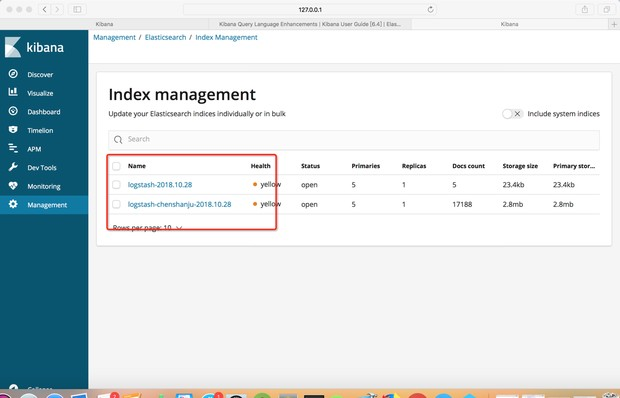
- 5.2.Management-Create Index Pattern
FAQ:
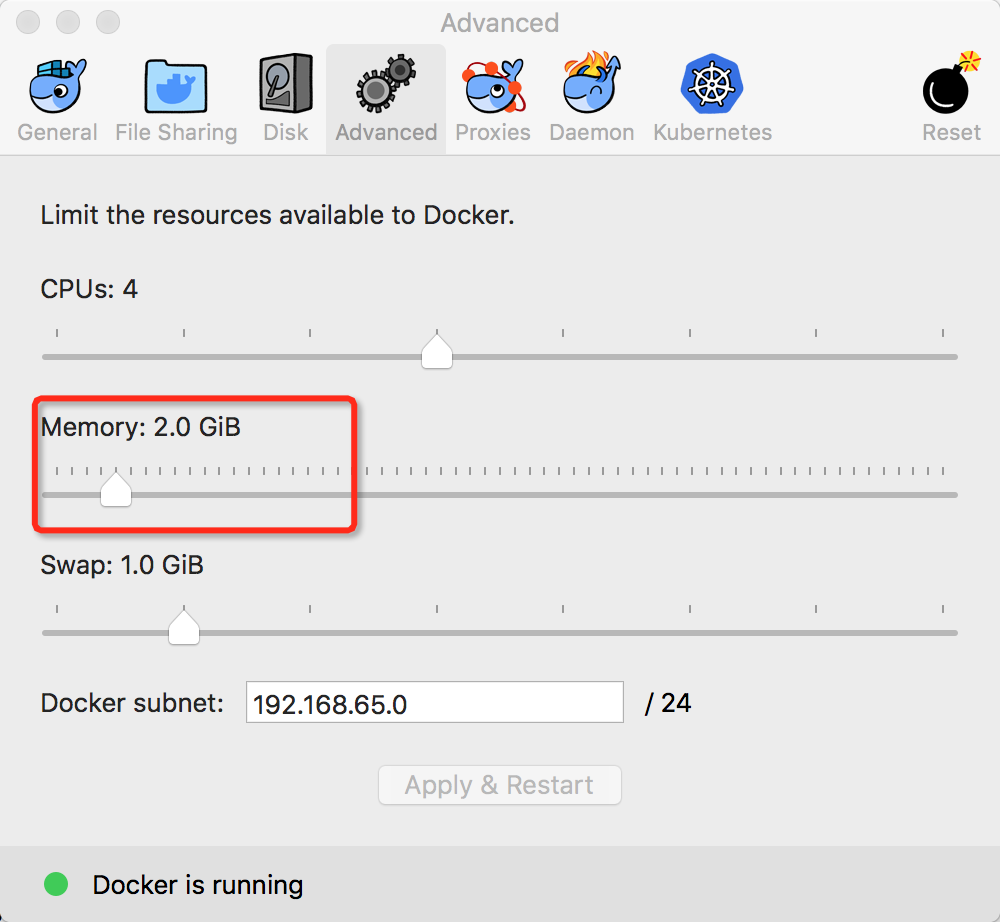
1.elk启动成功,但传入data时失败。因为elk需要4G内存,但我给docker只提供了2G。将内存调整为4G即可

 ### 2.有数据的情况下,kibana-discover没有内容
只要调整下时间即可
### 2.有数据的情况下,kibana-discover没有内容
只要调整下时间即可