DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,类似于均值转移聚类算法,但它有几个显著的优点。
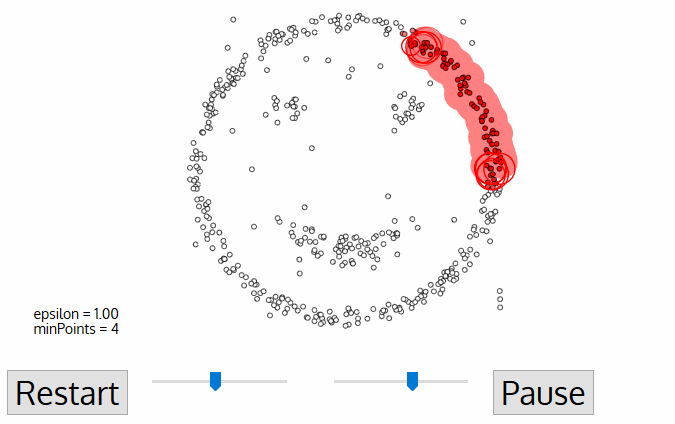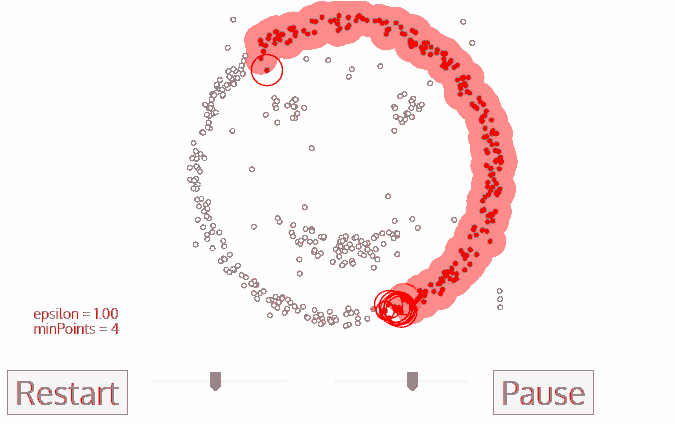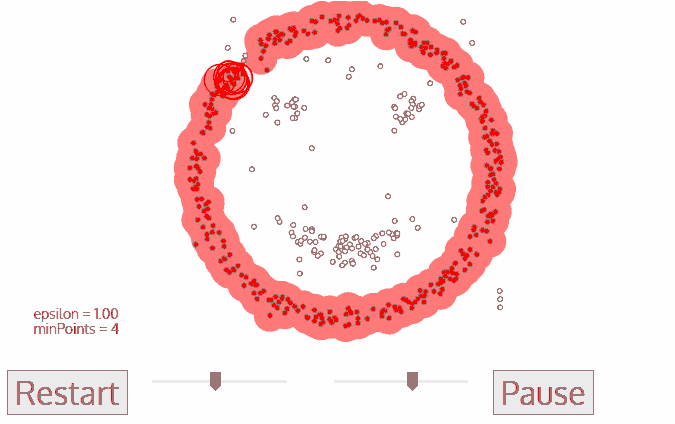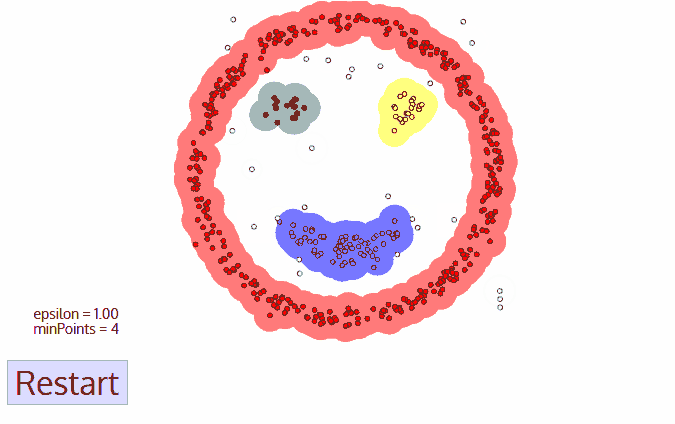
- DBSCAN以一个从未访问过的任意起始数据点开始。这个点的领域是用距离ε(所有在ε的点都是邻点)来提取的。
- 如果在这个邻域中有足够数量的点(根据minPoints),那么聚类过程就开始了,并且当前的数据点成为新聚类中的第一个点。否则,该点将被标记为噪声(稍后这个噪声点可能会成为聚类的一部分)。在这两种情况下,这一点都被标记为(visited)。
- 对于新聚类中的第一个点,其ε距离附近的店也会成为同意了聚类的一部分。这一过程在ε临近的所有点都属于同一个聚类,然后重复所有刚刚添加到聚类组的新点。
- 步骤2和步骤3的过程将重复,直到所有点都被确定,就是说在聚类附近的所有点都已被访问和标记。
- 一旦我们完成了当前的聚类,就会检索并处理一个新的未访问点,这将导致进一步的聚类或噪声的发现。这个过程不断地重读,直到所有的点被标记为访问。因为在所有的点都被访问过之后,每一个点都被标记为属于一个聚类或者是噪声。
DBSCAN的主要缺点是,当聚类具有不同的密度时,它的性能不像其他聚类算法那样好。这是因为当密度变化时,距离阈值ε和识别临近点的minPoints的设置会随着聚类的不同而变化。这种缺点也会出现在非常高纬的数据中心,因为距离阈值ε变得难以估计。