1.什么是推荐算法?
分析大量数据,最后计算出各种关联性从而进行预测,比如Amazon的商品推荐,今日头条的信息流媒体推荐,甚至是你看个视频右侧的相似推荐等等。这些都需要涉及到推荐算法,随着近几年数据的存储、计算、获取成本不断降低,企业或者是平台所拥有的的数据量也在飞速增加,这么大的数据量需要更好的使用才能发挥出他的价值,这种价值也会成为产品能力甚至是竞争壁垒。而大数据的使用过程中,一个重要的方向就是预测,预测里面一个重要的应用就是推荐。推荐算法会伴随着大数据和AI的发展越来越重要。
2.推荐算法的条件
1.根据和你共同喜好的人来给你推荐。
2.根据你喜欢的物品找出和它相似的来给你推荐。
3.根据给出的关键字来给你推荐,这实际上就退化成了搜索算法。
4.上面的组合来给你推荐。
3.推荐算法分类(大致可以分三类)
1.基于内容的推荐算法
就是根据用户平时自己的行为,比如关注的内容、搜索的内容、收藏的内容等等,根据这些内容去数据集合里面查找相似东西,比如你看了变形金刚Ⅰ,基于内容的推荐算法可以发现变形金刚Ⅱ并且推荐给你。根据的是内容的关联性。优势是可以解决冷启动问题(假如变形金刚Ⅱ没被人关注过,系统自动把Ⅰ和Ⅱ关联上,用户依然可以看到Ⅱ的推荐)。缺点是推荐的内容可能会重复,你看了地震的新闻,后期推荐的全是灾难相关的东西,甚至是有很多地震的;另一个弊端就是一些多媒体(比如音乐、电影、图片等)由于很难提取内容特征,则很难进行推荐,一种解决方式则是人工给这些内容打标签(人工标注的成本比较高)。
2.协同过滤算法
原理是先把个体大体分为两个集合,一个是用户,一个是物品。对于关系的话,每
个用户都会和一些物品产生关联,这样就把两个点连上了一条边(当然根据实际情况我 们可以设计权重,通常也应该设计权重)。最后建立一个包含两个集合的图。这个图里 面同一个集合中的两个点虽然没有两边,但是可以通过另一个集合的一些点来联通过 来。再根据边的权值来算关联度,当然这个地方常见的协同过滤都是使用相关算法,比 如说是把个点映射到多维空间上,然后计算欧几里得距离,或者是计算皮尔逊相关系数 等,这个下面再细说。简单来说就是通过中间联通集合来计算两个没有直接连接的两个 点的相关性,同时以不同的集合为参照点的到的结果也是不一样的,这就涉及到了协同 过滤的两个不同方式user-based 和item-based。也是下面细说。
3.基于知识的推荐算法
有点类似与基于内容,当然也可以分到里面去。基于知识的推荐算法就是制定一些 规则规定,然后根据这些我们把一些新的东西自动就关联上了,也就是利用先验知识建 建立一个先验模型,在冷启动或者是数据比较疏松的时候都是比较好的方式。OK下面 整理协同过滤。
|-----------------------------------------------------------------------
1.什么是协同过滤(百度百科)Collaborative Filtering
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
算法分类和细节、可以分为两类,一类是基于用户的User-based另一类是基于项目的Item-based。
1.基于用户的User-based协同过滤算法:
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜好进行度量打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。例如如果A、B两个用户都购买了X、Y、Z三本书,并且给了好评,那么A和B就属于同一类用户。可以将A看过的图书W也推荐给用户B。
1.1 寻找偏好的相似用户
模拟5个用户对两件商品的评分,来说明如何通过用户对不同商品的态度和偏好寻找相似的用户,5个用户分别对两件商品进行评分。这里的分值可能表示真实购买,也可能表示用户对商品不同行为的量化指标。例如浏览次数、推荐、搜索、收藏、分享、评论等等。这些行为都可以表示用户对商品的态度和偏好程度。
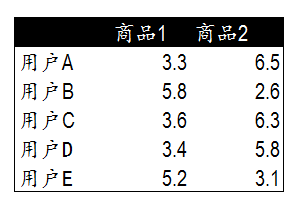
根据商品是2,建立一个二维的坐标系

然后看上面的图,就很容易发现A C D是一类,E B 是一类。实际过程中怎么通过数值来表示两点之间的相似程度?方法也很多,最基本的能想到的就是直接求欧几里得距离。这 个方法虽然简单,但是在机器学习算法中(比如图像特征提取)或其他很多复杂问题中 经常会用到。
二维的欧几里得距离公式:

算完之后得到的数值越小的两个点之间关联性约到,通常可以取到数这样方便观察出来关联程度。上面数据算完是这样:

还有就是用皮尔逊相关系数来表示关联程度,(百度百科)

再或者是求向量的内积外积,方法很多。
1.2为相似的用户提供推荐物品
当我们需要对用户C推荐商品时,首先我们检查之前的相似度列表,发现用户C和用户E的相似度较高。换句话说这三个用户是一个群体,拥有相同的偏好。因此,我们可以对用户C推荐D和E商品。但这里有一个问题。我们不能直接推荐前面商品1和5的商品。因为这些商品用户C已经浏览或者购买过了。不能重复推荐。因此我们要推荐用户C还没有接触过的商品。
提取了用户D和用户E评价过的另外5件商品A-F。并对不同商品的评分进行相似度加权。按加权后的结果对5件商品进行排序,然后推荐给用户C。这样,用户C就获得了与他偏好相似的用户D和E评价的商品。而在具体的推荐顺序和展示上我们依照D和用户E与用户C的相似度进行排序。
以上是基于用户的协同过滤算法,这个算法依靠用户的历史行为数据来计算相关度。也就是说必须要有一定的数据积累(冷启动问题)。对于新网站或者数据量较小的网站,还有一种方法基于物品的协同过滤算法。
2.基于物品的协同过滤算法Item-based
基于物品的协同欧过滤算法与基于用户的协同过滤算法很想,将商品和用户角色互 换。通过计算不同用户对不同物品的评分获得物品的关系。基于物品间的关系对用户进
相似物品推荐。这里的评分代表用户对商品的态度和偏好。简单来说如果用户A同时 购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商
1时,可以推荐他商品2。
实现过程和上面的user-based几乎一样,只是互换角色,细节就不说了。但是一定要注意这两者的区别,数据松散、数据量小、冷启动等问题上。Item比user好很多。建议在纸上画图理解。
优缺点
与传统文本过滤相比,协同过滤的优点是:
- 能够过滤难以进行机器自动基于内容分析的信息。如艺术品、音乐。
- 能够基于一些复杂的,难以表达的概念(信息质量、品味)进行过滤。
- 推荐的新颖性。
缺点:
- 用户对商品评价系数,这样基于用户的评价所得到的的用户间的相似性可能不准确。
- 随着用户和商品的怎过得,系统的性能会越来越低。
- 如果从来没有对某一件商品评价,则这个商品就很难被推荐(即最初评价问题)。
所以说现实中,都是用很多种方法混合这来进行推荐。