4.3 和数据相关的操作符和伪指令
操作符和伪指令并非机器可执行的指令,相反,它们是由汇编器进行解释的。开发者可以使用一系列的MASM操作符或伪指令获取数据的地址以及大小等特征信息:
OFFSET操作符返回一个变量相对于其所在段开始的偏移。
PTR 操作符允许重载变量的默认尺寸。
TYPE操作符返回数组中每个元素的大小(以字节计算)。
LENGTHOF操作符返回数组内元素的数目。
SIZEOF操作符返回数组初始化时占用的字节数。
除此之外,LABEL伪指令还提供了对同一变量重新定义不同尺寸属性的方法。本章只是讲述MASM所支持全部操作符和伪指令的一小部分。MASM仍然支持历史遗留的伪指令LENGTH(和LENGTHOF有所不同)以及SIZE(和SIZEOF有所不同)。
4.3.1 OFFSET操作符
OFFSET操作符返回数据标号的偏移地址。偏移地址代表标号距离数据段开始的距离,单位是以字节计算的。下图解释说明了一个名为myByte的变量在数据段内的偏移:
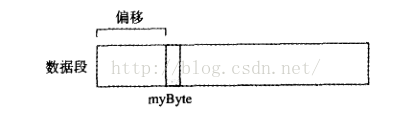
在保护模式下,偏移是32位的;在实地址模式下,偏移是16位的。
使用OFFSET的例子
.data
bVal BYTE ?
wVal WORD ?
dVal DWORD ?
dVal2 DWORD ?
如果bVal位于00000000处,那么OFFSET操作符的返回值如注释中所示
.code
mov esi ,OFFSET bVal ;ESI = 00000000
mov esi ,OFFSET wVal ;ESI = 00000001
mov esi ,OFFSET dVal ;ESI = 00000003
mov esi ,OFFSET dVal2 ;ESI = 00000007
OFFSET操作符也可以和直接偏移操作数联合使用。
4.3.2 ALIGN伪指令
可以使用ALIGN伪指令将变量的位置按字节、字、双字或段边界对齐,格式是:
ALIGN 边界值
边界值可以是1,2,4或16,把地址直接对齐到相关倍数上:
下面是书上例子的结果:
bVal BYTE ? ;00404000
ALIGN 2
wVal WORD ? ;00404002
bVal2 BYTE ? ;00404004
ALIGN 4
dVal DWORD ? ;00404008
dVal2 DWORD ? ;0040400C
4.3.3 PTR操作符
可以使用PTR操作符来重载操作数声明的默认尺寸,这在试图以不同于变量声明时所使用的尺寸属性访问变量的时候非常有用。
例如,假设要讲双字变量myDouble的低16位送AX寄存器,由于操作数大小不匹配,编译器将不允许下面的数据传送指令:
.data
myDouble DOWRD 12345678h
.code
Mov ax ,myDouble ;错误
但是WORD PTR 操作符使得将低字(5678)送AX成为可能:
mov ax ,WORD PTR myDouble
为什么不是1234h被送到AX寄存器了呢?这与之前说得使用小尾顺序存储格式有关。下图列出了myDouble变量在内存中以三种方式显示的布局:双字、两个字(5678h,1234h)和四个字节(78h,56h,34h,12h):
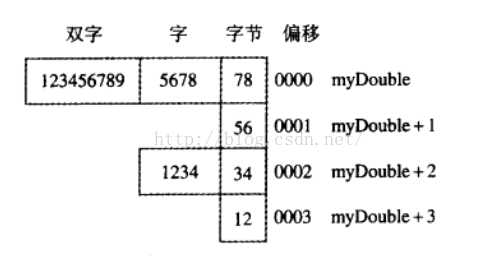
CPU能够以这三种方式中的任意一种访问内存,与变量定义的方式无关。例如,如果myDouble开始于便宜0000,存储在该地址的16位值是5678h,那么还可以使用下面的语句返回地址myDouble+2处的字1234h:
Mov ax ,WORD PTR [myDouble+2] ;1234h
类似地,可以使用BYTE PTR操作符把myDouble处的一个字节放到BL:
Mov bl ,BYTE PTR myDouble ;78h
注意,PTR必须和汇编器的标准数据类型联合使用:BYTE ,SBYTE ,WORD,SWORD,
DWORD ,SDWORD ,FWORD ,QWORD或TBYTE。
将较小值送较大的目的操作数中:有时候,或许需要把内存中两个较小的值送到较大的目的操作数中。在下例中,第一个字将复制到EAX的低半部分,第二个字将复制到EAX的高半部分,DWORD PTR操作符使者一切成为可能:
.data
wordList WORD 5678h ,1234h
.code
Mov eax ,DWORD PTR wordList ;EAX = 12345678h
4.3.4 TYPE操作符
TYPE操作符返回按字节计算的变量的单个元素的大小。1个字节(byte)的TYPE值等于1,一个字(word)的TYPE值等于2...,下面定义了一些不同的类型变量:
.data
Var1 BYTE ?
Var2 WORD ?
Var3 DWORD ?
Var4 QWORD ?
然后是对应的TYPE

4.3.5 LENGTHOF 操作符
LENGTHOF操作符计算数组中元素的数目,元素由出现在同一行的值(作为其标号)定义。如下:
.data
Byte1 BYTE 10,20,30
Array1 WORD 30 DUP(?) ,0 ,0
Array2 WORD 5 DUP(3 DUP (?))
Array3 DWORD 1,2,3,4
Digitstr BYTE “12345678”,0
调用LENGTHOF结果如下:

注意当在数组的定义中使用嵌套DUP定义时,LENGTHOF将返回两个计数器的乘积。
如果声明了一个跨多行的数组,LENGTHOF只把第一行的数据作为数组的元素。在下例中,LENGTHOF myArray的返回值是5:
myArray BYTE 10,20,30,40,50
BYTE 60,70,80,90,100
如果想显示结果为10,那么就在第一行后面加一个逗号定义,如:
myArray BYTE 10,20,30,40,50,
60,70,80,90,100
4.3.6 SIZEOF 操作符
SIZEOF操作符的返回值等于LENGTHOF和TYPE返回值的乘积。下例中,intArray的TYPE等于2 ,其LENGTHOF等于32,因此SIZEOF intArray等于64:
.data
intArray WORD 32 DUP(0)
.code
Mov eax,SIZEOF intArray
4.3.7 LABEL伪指令
LABEL伪指令允许插入一个标号并赋予其尺寸属性而无需任何实际的存储空间。LABEL伪指令可以使用BYTE、WORD、DWORD、QWORD或TBYTE等任意的标准尺寸属性。LABEL伪指令的一种常见的用法是为数据段内其后定义的变量提供一个别名以及一个不同的尺寸属性。下例中在val32前面声明了一个名为val16的标号并赋予其WORD属性:
.data
Val16 LABEL WORD
Val32 DWORD 12345678h
.code
Mov ax,val16 ;AX = 5678h
Mov dx,[val16+2] ;DX = 1234h
Val16是名为val32的存储地址的一个别名。LABEL伪指令本身并不占用实际存储空间。
有时需要用两个较小的整数构造一个较大的整数。在下例中,由两个16位变量构成的32位值被装入到了EAX中:
.data
val16 LABEL WORD
val32 DWORD 12345678h
.code
mov ax,val16 ;AX = 5678h
mov dx,[val16+2] ;DX = 1234h
val16 是名为val32的存储地址的一个别名。LABEL伪指令本身并不占用实际存储空间。
有时需要用两个较小的整数构造一个较大的整数。在下例中,由两个16位变量构成的32位值被装入到了EAX中:
.data
LongValue LABEL DWORD
Val1 WORD 5678h
Val2 WPRD 1234h
.code
Mov eax ,LongValue ;EAX = 12345678h
4.4 间接寻址
保护模式:间接操作数可以是任何用方括号括起来的任意的32位通用寄存器(EAX EBX ECX EDX ESI EDI EBP ESP),寄存器里面存放着数据的偏移。下列中 ESI中存放着val1的偏移地址。MOV指令使用间接操作数作为源操作数,此时ESI内的偏移地址被用来进行寻址,该地址处的一个字节被送至AL:
.data
val1 BYTE 10h
.code
mov esi , OFFSET val1
mov al ,[esi] ;AL = 10h
或者如下例,间接操作数作为目的操作数,一个新值将被存放在寄存器所指向的内存位置:
mov [esi] ,bl
实地址模式:实地址模式下使用16位的寄存器存放变量的偏移地址,如果要使用寄存器做间接操作数的话,只能使用SI、BI、BX或BP寄存器、通常应
免使用BP,因为BP常用来寻址堆栈而不是数据段。下例中使用了SI来引用val1:
.data
val1 BYTE 10h
.code
main proc
Startup
Mov si ,OFFSET val1
Mov al,[si] ;AL = 10h
通用保护故障:在保护模式下,如果有效地址指向程序数据段之外的区域,CPU就有可能会产生通用保护故障(GP,General Protection Fault)。既使指令饼不修改内存,这种情况可可能发生。例如,如果ESI未初始化,下面的指令就有可能产生通用保护故障:
mov ax ,[esi]
在使用作为间接操作数的寄存器应对其进行初始化。这个规则同样适用于使用下表和指针的高级语言程序设计。实地址模式下不会产生通用保护故障,这使得未初始化的间接操作数难于检测。
PTR:与间接操作数的联合使用。有时候在一条指令的上下文中,操作数的大小通常并不明确。对于下面的指令,在编译时汇编器将产生错误信息。
inc [esi] ;错误
这是因为编译器并不知道ESI是指向一个字节、一个字、一个双字或者是其他什么尺寸的操作数。在这里,使用PTR操作符可以指明操作数的尺寸大小:
inc BYTE PTR [esi]
4.4.2 数组
由于间接操作数的值(寄存器内的偏移地址)可以在运行时进行修正,因此在处理数组时特别有用。与数组下标类似,间接操作数可以指向数组的不同元素。例如在下例中arrayB包含三个字节,我们可以递增ESI的值,使之依顺序指向各个字节:
.data
arrayB BYTE 10h ,20h ,30h
.code
mov esi ,OFFSET arrayB
mov al ,[esi] ;AL = 10h
inc esi
mov al,[esi] ;AL = 20h
inc esi
mov al,[esi] ;AL = 30h
如果使用16位的整数数组,就需要给ESI加2以便寻址后续的各个数组元素:
.data
arrayW WORD 1000h ,2000h ,3000h
.code
mov esi ,OFFSET arrayW
mov ax,[esi] ;AX = 1000h
add esi,2
mov ax,[esi] ;AX=2000h
...
4.4.3 变址操作符
变址操作数(indexed operand)把常亮和寄存器相加得到一个有效地址,任何32位通用寄存器都可以作为变址寄存器,MASM允许使用两种不同的变址操作数格式(方括号是格式的一部分,而非表示其中的部分是可选项):
constant[reg]
[constant+reg]
第一种格式把变量的地址和寄存器结合在一起,变量的名字是代表变量偏移地址的常量。下表显示了两种格式之间的对应关系:

在访问数组第一个元素之前变址寄存器应初始化为零:
.data
arrayB BYTE 10h,20h,30h
.code
mov esi ,0
mov al,[arrayB + esi] ;AL = 10h
加偏移地址:另外一种变址寻址方式是把变址寄存器和常量偏移联合起来使用,不过是用变址寄存器存放数组或结构的基地址,用常量标示各个数组元素。下例演示了是如何对一个16位的数组做到这一点的:
.data
arrayW WORD 1000h,2000h,3000h
.code
mov esi ,OFFSET arrayW
mov ax,[esi] ;AX = 1000h
mov ax,[esi+2] ;AX = 2000h
mov ax,[esi+4] ;AX = 3000h
使用16位寄存器:在实地址模式下使用16位的寄存器作为变址操作是很普遍的,不过这时只能使用SI、DI、BX和BP寄存器:
mov al ,arrayB[si]
mov ax,arrayW[di]
mov eax,arrayD[bx]
同间接操作数一样,除非寻址堆栈上的数据,否则应该尽量避免使用BP寄存器。
变址操作数中的比例因子
使用变址操作数,在计算机便宜地址时必须考虑每个元素的大小。例如在下面的例子的双字数组中,把下标3乘以4(双字的尺寸),以得数组元素400h的偏移地址:
.data
arrayD DWORD 100h ,200h ,300h ,400h
.code
mov esi ,3*TYPE arrayD ;arrayD[3]的偏移地址
mov eax,arrayD[esi] ;EAX = 400h
比例因子是指数组中每个元素的大小。
.data
arrayD DWORD 1,2,3,4
.code
mov esi ,3 ;下标
mov eax,arrayD[esi*4] ;EAX = 4
或者
mov esi ,3 ;下标
mov eax ,arrayD[esi*TYPE arrayD] ;EAX = 4
4.4.4 指针
包含其他变量地址的变量成为指针变量,操纵数组和数据结构时指针是非常有用的,使用指针使得进行动态内存分配成为可能。基于Intel的程序使用两种类型的指针:NEAR和FAR,它们的尺寸受当前处理器的影响(16位实地址模式或32位保护模式)。

下面是例子,prtW指向ptrW,ptrB指向prtB:
arrayB BYTE 10h,20h,30h,40h
arrayW WORD 1000h,2000h,3000h
ptrB DWORD arrayB
ptrW DWORD arrayW
或者这样会显得更清晰一些:
ptrB DWORD OFFSET arrayB
ptrW DWORD OFFSET arrayW
使用TYPEDEF操作符
TYPEDEF操作符允许创建自己定义的类型。
例如下面的声明创建了一种新的数据类型,指向字节的指针PBYTE:
PBYTE TYPEDEF PTR BYTE
这样的声明一般被至于程序的开始处,通常在数据段之前。此后,就可以使用PBYTE来定义变量了:
.data
arrayB BYTE 10h ,20h ,30h ,40h
ptr1 PBYTE ? ;未初始化
ptr2 PBYTE arrayB ;指向数组
PS:这个地方我一直感觉很别扭,上面说有两种类型的指针,而素有的指针例子都是只是创建了内存变量,比如DOWRD或者是BYTE,没有用什么NEAR或者FAR。
下面是指针的小程序(哎!和我的疑问一样,也就是指针只是保存地址的普通变量?)
TITLE Pointers (Pointers.asm)
INCLUDE Irvine32.inc
;创建用户自动以类型
PBYTE TYPEDEF PTR BYTE ;字节指针
PWORD TYPEDEF PTR WORD ;字指针
PDWORD TYPEDEF PTR DWORD ;双字指针
.data
arrayB BYTE 10h ,20h ,30h
arrayW WORD 1,2,3
arrayD DWORD 4,5,6
;创建一些指针变量
prt1 PBYTE arrayB
ptr2 PWORD arrayW
ptr3 PDWORD arrauD
.code
main PROC
;使用指针变量访问数据
mov esi,ptr1
mov al,[esi]
mov esi,ptr2
mov ax,[esi0]
mov esi,ptr3
mov eax,[esi]
exit
main ENDP
END main
4.5 JMP和LOOP指令
默认情况下,CPU加载程序并按谁许执行其中的指令。但是可能遇到条件语句,这也就意味着当前指令有可能会根据CPU的标志值把控制权转交到程序中的一个新的地址处。汇编语言程序使用条件处理指令实现高级语言中的条件处理(IF)语句和循环语句。每种条件处理语句都有可能导致控制转移到(跳转到)内存中的一个新的地质处。控制转移或者说分支转移是一种改变语句执行顺序的方法。控制转移可分为两种:
无条件转移:无论何种情况下,程序都转移到一个新的地址,CPU在新的地址继续执行。JMP指令就是一个很好的例子。
条件转移:如果特定条件满足则程序转移。Intel提供了大量的条件转移指令,这些指令结合起来可以创建各种条件逻辑结构。CPU根据ECX寄存器和标志寄存器的内容解释条件的真或假。
4.5.1 JMP指令
JMP指令导致像代码段内的目的地址做无条件转移。JMP指令的格式是:
JMP 目的地址
CPU执行无条件转移指令时,目标标号的偏移地址将被装入指令指针钟,CPU立即开始在新的地址继续执行指令。通常情况下,JMP指令只能跳转到当前过程中的标号处。
创建了一个循环:JMP指令提供了一种创建循环的简单方法,只要跳到循环顶端的标号就可以了:
top:
.
.
.
jum top ;无限循环
4.5.2 LOOP指令
LOOP指令重复执行一块语句,执行的次数是特定的,ECX被自动用作计数器,每次执行后减1,格式如下:
LOOP 目的地址
LOOP指令的执行包含两步:首先,ECX减1,接着与0比较。如果EXC不等于0,则跳转到目的地址(标号)处;如果ECX等于0,则不发生跳转,这是控制权将转移到紧跟在LOOP后面的指令处。
在实地址模式下,用作默认循环计数器的是CX寄存器。不论是在实地址模式下还是在保护模式下,LOOPD指令总是使用ECX作为循环计数器,而LOOPW总是使用CX作为循环计数器。
在下例中,每次执行循环时AX加1,当循环结束的时候AX=5,ECX=0:
mov ax,0
mov ecx,5
L1:
inc ax
loop L1
常见的编程错误是在循环开始之间将ECX初始化为0。这种情况下,LOOP指令执行后,ECX减1得到FFFFFFFFh,结果是循环将重复4294967296次!如果是用CX做循环计数器,循环将重复65536次。
循环的目的地址与当前地址只能在相距-128-+127字节之内。机器指令的平均大小是3字节左右,因此一个循环平均最多只能含大约42条指令。下面语句是由于LOOP指令的目的标号地址距过远时MASM产生的错误信息:

如果在循环内修改了ECX的值,LOOP指令就有可能无法正确工作了。下例中ECX在循环中加1,因此执行LOOP指令后ECX永远不会为0,循环也不会结束:
top:
.
.
inc ecx
loop top
如果用光了所有的寄存器,但又因为种种原因必须使用ECX寄存器的话,可以在循环开始把ECX保存在变量中并在LOOP指令之前将其恢复:
.data
count DWORD ?
.code
mov ecx,100 ;设置循环计数
top:
mov count,ecx ;保存寄存器
.
mov ecx,20 ;修改ECX
.
mov ecx,count ;恢复ECX
loop top
循环的嵌套:在循环内创建另一个循环的时候,必须考虑ECX中的外层循环计数该如何处理。一个较好的解决方案是把外层循环的技术保存在一个变量中:
.data
count DWORD ?
.code
mov ecx,100
L1:
mov count,ecx
mov ecx,20
L2:
.
.
loop L2
mov exc ,count
loop L1
作为一条一般性的规则,应该尽量避免使用嵌套深度超过两层的循环。否则,管理循环计数将很蛋疼。
4.5.3 整数数组求和
TITLE Summing an Array (SumArray.asm)
INCLUDE Irvine32.inc
.data
intarray WORD 100h,200h,300h,400h
.code
main PROC
mov edi,OFFSET intarray ;intarray的地址
mov ecx,LENGTHOF intarray;循环计数器
mov ax,0
L1:
add ax,[edi] ;加上一个整数
add edi,TYPE intarray ;指向下一个整数
loop L1 ;重复循环直到ECX=0为止
exit
main ENDP
END main
4.5.4 复制字符串
TITLE Copying a String (CopyStr.asm)
INCLUDE Irvine32.inc
.data
source BYTE “This is the source string”,0
target BYTE SIZEOF source DUP(0),0
.code
main PROC
mov esi,0 ;变址寄存器
mov ecx,SIZEOF source ;循环计数器
L1:
mov al,source[esi] ;复制一个字符
mov target[esi],al ;存进去
inc esi ;移到下一个字符
loop L1 ;循环重复
exit
main ENDP
END main
MOV指令不能同时对两个内操作数进行操作,因此每个字符首先宋源字符串考到AL中,再从AL中拷贝到目的字符串中。
4.6 本章小结

