三种不同的方法计算前缀和,并与CPU的结果进行了对比。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <windows.h> 4 #include <time.h> 5 #include <math.h> 6 #include "cuda_runtime.h" 7 #include "device_launch_parameters.h" 8 9 #define ARRAY_SIZE (1024*7+419) 10 #define SIMPLE_TASK 1024 11 #define WIDTH 256 12 #define SEED 1 //(unsigned int)clock() 13 #define RAND_RANGE 10 // 取[-RAND_RANGE,+RAND_RANGE]范围的随机数 14 #define MIN(x,y) ((x)<(y)?(x):(y)) 15 #define CEIL(x,y) (int)(( x - 1 ) / y + 1) 16 17 typedef int format; // int or float 18 19 void checkCudaError(cudaError input) 20 { 21 if (input != cudaSuccess) 22 { 23 printf(" find a cudaError!"); 24 exit(1); 25 } 26 return; 27 } 28 29 int ceil_base2(int input)// 将input向上约化到2的整数幂上去 30 { 31 int i; 32 for (i = 1; input > 1; input = (input + 1) / 2, i *= 2); 33 return i; 34 } 35 36 int checkResult(format * in1, format * in2, const int length) 37 // 注意返回值为0(两向量相等)或者“值不等的元素下标加一”(防止0号元素就不相等),返回后若想使用该下标则需要减1 38 { 39 int i; 40 for (i = 0; i < length; i++) 41 { 42 if (in1[i] != in2[i]) 43 return i+1; 44 } 45 return 0; 46 } 47 48 void prefixSumCPU(const format *in, format *out, const int array_size) 49 { 50 out[0] = in[0]; 51 for (int i = 1; i < array_size; i++) 52 out[i] = out[i - 1] + in[i]; 53 return; 54 } 55 56 __global__ void select(const format *in, format *out, const int space)// 从in中等间距挑选元素放到out中去,注意要用 57 { 58 out[threadIdx.x] = (threadIdx.x == 0) ? 0 : in[(threadIdx.x)*space - 1]; 59 return; 60 } 61 62 __global__ void add(format *in, const format * addend, const int array_size)// 线程块内所有元素加上一个来自addend中的特定的元素 63 { 64 __shared__ format share_addend; 65 share_addend = addend[blockIdx.x]; 66 67 int id = blockIdx.x * blockDim.x + threadIdx.x; 68 if (id < array_size) 69 in[id] += share_addend; 70 return; 71 } 72 73 __global__ void prefixSumGPU1(const format *in, format *out, const int array_size)// 低效率分段闭扫描前缀和,可以处理任意长度 74 { 75 extern __shared__ format share_in[]; 76 int id = blockIdx.x * blockDim.x + threadIdx.x; 77 int jump; 78 share_in[threadIdx.x] = 0; 79 if (id < array_size) 80 share_in[threadIdx.x] = in[id]; 81 __syncthreads(); 82 83 for (jump = 1; jump < blockDim.x; jump *= 2) 84 { 85 share_in[threadIdx.x] += (threadIdx.x >= jump) ? share_in[threadIdx.x - jump] : 0; 86 __syncthreads(); 87 } 88 if (id < array_size) 89 out[id] = share_in[threadIdx.x]; 90 return; 91 } 92 93 __global__ void prefixSumGPU2(const format *in, format *out, const int array_size)//收集 - 分发树法,处理2的整数次幂个元素 94 { 95 extern __shared__ format share_in[]; 96 int id = blockIdx.x * blockDim.x + threadIdx.x; 97 int target; 98 int jump; 99 share_in[threadIdx.x] = 0; 100 if (id < array_size) 101 share_in[threadIdx.x] = in[id]; 102 __syncthreads(); 103 104 /*//收集树,与后面一个收集树等效,但是使用了离散的线程,读写效率较低 105 for (jump = 1; jump < blockDim.x; jump *= 2) 106 { 107 share_in[threadIdx.x] += ((threadIdx.x + 1) % (2 * jump) == 0) ? share_in[threadIdx.x - jump] : 0; 108 __syncthreads(); 109 } 110 */ 111 for (jump = 1; jump < blockDim.x; jump *= 2)// 收集树,利用连续的线程,减少逻辑分支 112 { 113 target = (threadIdx.x + 1) * 2 * jump - 1; 114 if (target < blockDim.x) 115 share_in[target] += share_in[target - jump]; 116 __syncthreads(); 117 } 118 for (jump = blockDim.x / 4; jump > 0; jump /= 2)// 分发树 119 { 120 target = (threadIdx.x + 1) * 2 * jump - 1; 121 if (target + jump < blockDim.x) 122 share_in[target + jump] += share_in[target]; 123 __syncthreads(); 124 } 125 if (id < array_size) 126 out[id] = share_in[threadIdx.x]; 127 return; 128 } 129 130 __global__ void prefixSumGPU3(const format *in, format *out, const int array_size)//改良版收集 - 分发树,处理的元素个数为线程数的2倍 131 { 132 extern __shared__ format share_in[]; 133 int id = blockIdx.x * blockDim.x + threadIdx.x; 134 int target; 135 int jump; 136 share_in[2 * threadIdx.x] = 0; 137 share_in[2 * threadIdx.x + 1] = 0; 138 if (2 * id + 1 < (array_size + 1) / 2 * 2)// 改动,调整下标范围以适应奇数个元素 139 { 140 share_in[2 * threadIdx.x] = in[2 * id];// 改动,一个线程要搬运两个全局内存 141 share_in[2 * threadIdx.x + 1] = in[2 * id + 1]; 142 } 143 __syncthreads(); 144 145 for (jump = 1; jump < 2 * blockDim.x; jump *= 2)// 改动,放宽了jump的上限 146 { 147 target = (threadIdx.x + 1) * 2 * jump - 1; 148 if (target < 2 * blockDim.x)// 改动,放宽了接收元素下标范围 149 share_in[target] += share_in[target - jump]; 150 __syncthreads(); 151 } 152 for (jump = blockDim.x / 2; jump > 0; jump /= 2)// 改动,放宽了jump的初始值 153 { 154 target = (threadIdx.x + 1) * 2 * jump - 1; 155 if (target + jump < 2 * blockDim.x)// 改动,放宽了接收元素下标范围 156 share_in[target + jump] += share_in[target]; 157 __syncthreads(); 158 } 159 if (2 * id + 1 < (array_size + 1) / 2 * 2)// 改动,调整下标范围以适应奇数个元素 160 { 161 out[2 * id] = share_in[2 * threadIdx.x];// 改动,一个线程要搬运两个全局内存 162 out[2 * id + 1] = share_in[2 * threadIdx.x + 1]; 163 } 164 return; 165 } 166 167 int main() 168 { 169 int i; 170 int simple_task = MIN(ceil_base2(ARRAY_SIZE), SIMPLE_TASK);//要么将原数组向上扩充到最小的2的整数次幂个大小,要么最大限制1024个元素 171 format h_in[ARRAY_SIZE], cpu_out[ARRAY_SIZE], gpu_out[ARRAY_SIZE]; 172 format *d_in, *d_out, *d_temp, *d_temp2; 173 174 cudaStream_t stream; 175 cudaStreamCreate(&stream); 176 clock_t time; 177 cudaEvent_t start, stop; 178 float elapsedTime1, elapsedTime2, elapsedTime3, elapsedTime4; 179 cudaEventCreate(&start); 180 cudaEventCreate(&stop); 181 182 checkCudaError(cudaMalloc((void **)&d_in, sizeof(format) * ARRAY_SIZE)); 183 checkCudaError(cudaMalloc((void **)&d_out, sizeof(format) * ARRAY_SIZE)); 184 int d_temp_length = CEIL(ARRAY_SIZE, WIDTH);// array首次分解为线程块的数量 185 checkCudaError(cudaMalloc((void **)&d_temp, sizeof(format) * d_temp_length)); 186 187 srand(SEED); 188 for (i = 0; i < ARRAY_SIZE; i++) 189 h_in[i] = rand() % (RAND_RANGE << 1 + 1) - RAND_RANGE; 190 191 time = clock(); 192 prefixSumCPU(h_in, cpu_out, ARRAY_SIZE); 193 time = clock() - time; 194 195 cudaMemcpy(d_in, h_in, sizeof(format) * ARRAY_SIZE, cudaMemcpyHostToDevice); 196 197 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 198 cudaEventRecord(start, 0); 199 prefixSumGPU1 << < 1, simple_task, sizeof(format) * simple_task >> > (d_in, d_out, MIN(ARRAY_SIZE, SIMPLE_TASK)); 200 cudaMemcpy(gpu_out, d_out, sizeof(format) * MIN(ARRAY_SIZE, SIMPLE_TASK), cudaMemcpyDeviceToHost); 201 cudaDeviceSynchronize(); 202 cudaEventRecord(stop, 0); 203 cudaEventSynchronize(stop); 204 cudaEventElapsedTime(&elapsedTime1, start, stop); 205 if (i = checkResult(cpu_out, gpu_out, MIN(ARRAY_SIZE, SIMPLE_TASK))) 206 printf(" Compute error at i = %d cpu_out[i] = %10d, gpu_out[i] = %10d ", i - 1, cpu_out[i - 1], gpu_out[i - 1]); 207 else 208 printf(" GPU1 Compute correctly! "); 209 210 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 211 cudaEventRecord(start, 0); 212 prefixSumGPU2 << < 1, simple_task, sizeof(format) * simple_task >> > (d_in, d_out, MIN(ARRAY_SIZE, SIMPLE_TASK)); 213 cudaMemcpy(gpu_out, d_out, sizeof(format) * MIN(ARRAY_SIZE, SIMPLE_TASK), cudaMemcpyDeviceToHost); 214 cudaDeviceSynchronize(); 215 cudaEventRecord(stop, 0); 216 cudaEventSynchronize(stop); 217 cudaEventElapsedTime(&elapsedTime2, start, stop); 218 if (i = checkResult(cpu_out, gpu_out, MIN(ARRAY_SIZE, SIMPLE_TASK))) 219 printf(" Compute error at i = %d cpu_out[i] = %10d, gpu_out[i] = %10d ", i - 1, cpu_out[i - 1], gpu_out[i - 1]); 220 else 221 printf(" GPU2 Compute correctly! "); 222 223 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 224 cudaEventRecord(start, 0); 225 prefixSumGPU3 << < 1, simple_task / 2, sizeof(format) * simple_task >> > (d_in, d_out, MIN(ARRAY_SIZE, SIMPLE_TASK)); 226 cudaMemcpy(gpu_out, d_out, sizeof(format) * MIN(ARRAY_SIZE, SIMPLE_TASK), cudaMemcpyDeviceToHost); 227 cudaDeviceSynchronize(); 228 cudaEventRecord(stop, 0); 229 cudaEventSynchronize(stop); 230 cudaEventElapsedTime(&elapsedTime3, start, stop); 231 if (i = checkResult(cpu_out, gpu_out, MIN(ARRAY_SIZE, SIMPLE_TASK))) 232 printf(" Compute error at i = %d cpu_out[i] = %10d, gpu_out[i] = %10d ", i - 1, cpu_out[i - 1], gpu_out[i - 1]); 233 else 234 printf(" GPU3 Compute correctly! "); 235 236 // 长向量前缀和,假设长度不大于WIDTH^2(两次迭代可完成) 237 cudaMemset(d_out, 0, sizeof(format) * ARRAY_SIZE); 238 cudaEventRecord(start, 0); 239 prefixSumGPU3 << < d_temp_length, WIDTH / 2, sizeof(format) * WIDTH, stream >> > (d_in, d_out, ARRAY_SIZE); 240 select << < 1, d_temp_length, 0, stream >> > (d_out, d_temp, WIDTH); 241 prefixSumGPU3 << < 1, ceil_base2(d_temp_length), sizeof(format) * ceil_base2(d_temp_length), stream >> > (d_temp, d_temp, d_temp_length); 242 add << < d_temp_length, WIDTH, 0, stream >> > (d_out, d_temp, ARRAY_SIZE); 243 cudaMemcpy(gpu_out, d_out, sizeof(format) * ARRAY_SIZE, cudaMemcpyDeviceToHost); 244 cudaDeviceSynchronize(); 245 cudaEventRecord(stop, 0); 246 cudaEventSynchronize(stop); 247 cudaEventElapsedTime(&elapsedTime4, start, stop); 248 if (i = checkResult(cpu_out, gpu_out, ARRAY_SIZE)) 249 printf(" Compute error at i = %d cpu_out[i] = %10d, gpu_out[i] = %10d ", i - 1, cpu_out[i - 1], gpu_out[i - 1]); 250 else 251 printf(" GPU4 Compute correctly! "); 252 253 // 长向量前缀和,可能多次迭代 254 // TODO 255 256 printf(" Spending time: CPU: %10ld ms 257 GPU1: %f ms GPU2: %f ms GPU3: %f ms GPU4: %f ms ", 258 time, elapsedTime1, elapsedTime2, elapsedTime3, elapsedTime4); 259 260 cudaFree(d_in); 261 cudaFree(d_out); 262 cudaFree(d_temp); 263 cudaStreamDestroy(stream); 264 cudaEventDestroy(start); 265 cudaEventDestroy(stop); 266 getchar(); 267 return 0; 268 }
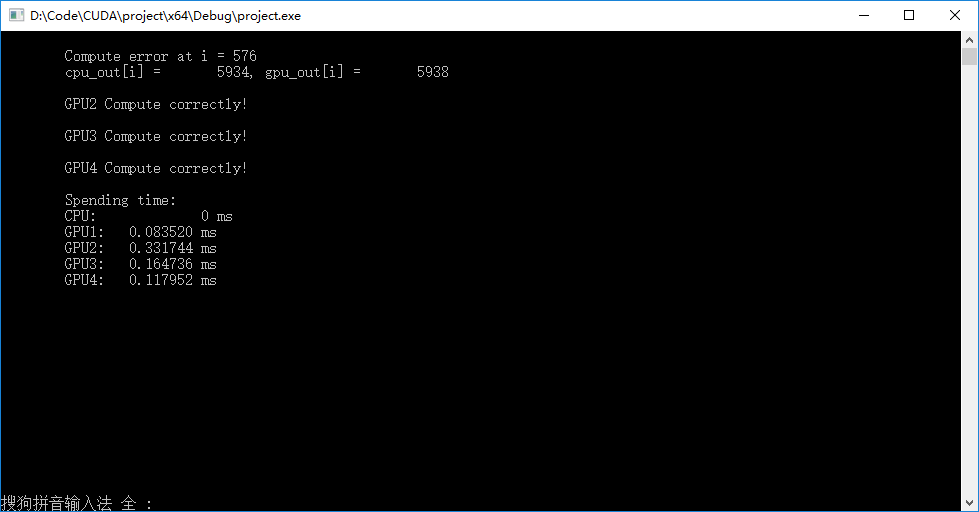
▶ 结果如下图。第一种方法存在不可重现的bug,且仅当输入数组规模大于512时开始出现,原因未知。其他几种方法计算结果均正确,再计算较短的响亮的时候第三种方法(改良的收集 - 分发树法)效率最高,当向量长度远大于自己设定的阈值1024(单个线程亏最大处理大小)时,第四种方案的效率很高。由于warm-up的原因,第四种方案计算全部向量的速度还有可能快于第三种方案计算前1024个元素的速度。