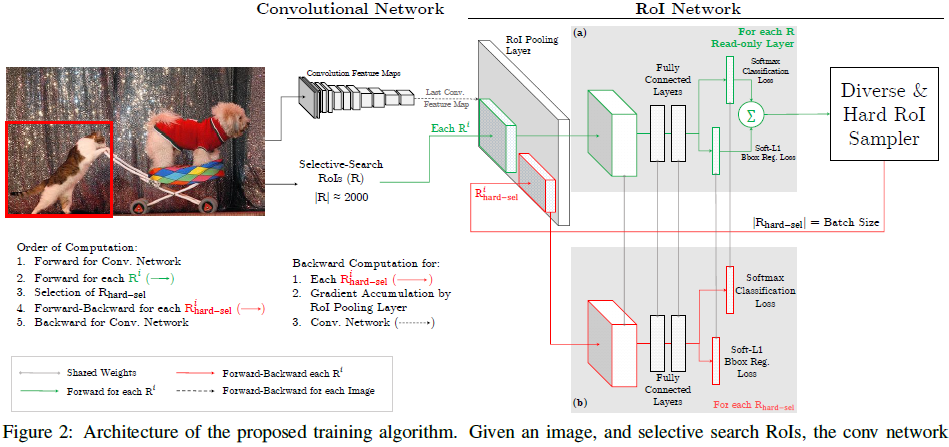
OHEM算法的核心思想就是根据输入样本的损失进行筛选,筛选出hard example表示对分类和检测影响较大的样本,然后将筛选得到的这些样本应用在随机梯度下降中训练,在实际操作中将原来的一个ROI Network扩充为两个ROI,这两个ROI Network共享参数,其中前面一个ROI Network只有前向操作,主要用于计算损失,后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失后回传梯度。
网络结构如下所示。
该算法的优点是:
(1)对于数据的不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强。
(2)随着数据集的增大,算法的提升更加明显。
下面介绍一下困难样本。
闭集分类问题(closed-set problem),即测试和训练的每个类别都有具体的标签,不包含未知的类别(unknown category or unseen category); 如著名的MNIST和ImageNet数据集,里面包含的每个类别为确定的。以MNIST(字符分类)为例,里面包含了0~9的字符类别,测试时也是0~9的类别,并不包含如字母A~Z等的未知类别,闭集分类问题的目的即:正确划分这10个类别
开集分类问题(open-set problem)不仅仅包含0~9的字符类别,还包含其他如A~Z等等的未知类别,但是这些未知的类别并没有标签,分类器无法知道这些未知类别里面图像的具体类别,如:是否是A,这些许许多多的不同类别图像共同构成了一个类别:未知类别,在检测里面我们叫做背景类别(background),而开集分类问题的目的即是:正确划分这10个类别且正确排除非数字类别,关于开放环境下的分类问题会在后续的文章中作全面的总结
所以对于物体检测问题而言,检测器面对的是整个世界的物体,这些物体里面只有非常少的被标记了具体类别,大量的物体其实并没有类别信息,甚至根本不知道如何标记他的类别,所以面对开集问题,我们要求检测(分类)器要有非常好的排他能力或排除背景类别能力,那么训练数据将会非常重要,为了有这样的能力我们需要切割下大量的背景作为负样本(negative samples)来训练,但是这些背景样本是否足够了?不管加了多少背景数据,目前都无法从理论上回答这个问题:背景是否足够。 而事实上不管如果加背景数据训练,模型总能遇到不能正确分类或很难分类的背景样本(false positive) ,这个就是我们常说的困难负样本(hard negative samples) 与之相反的是 hard positive samples,统称为困难样本(hard samples)
算法流程:
ROI经过ROI Pooling层生成feature map,然后进入只读的ROI Network,得到所有ROI的Loss,然后hard ROI sampler结构根据损失排序选出hard example,并把这些hard example作为下面那个ROI Network的输入。注:即训练时选择前K个Loss比较大的样本进行反向传播,而Loss较小的样本则认为分类正确不用BP。