1.1 定义
网络爬虫,也叫网络蜘蛛(Web Spider),如果把互联网比喻成一个蜘蛛网,Spider就是一只在网上爬来爬去的蜘蛛。网络爬虫就是根据网页的地址来寻找网页的,也就是URL。举一个简单的例子,我们在浏览器的地址栏中输入的字符串就是URL,例如:https://www.baidu.com/
URL就是同意资源定位符(Uniform Resource Locator),它的一般格式如下(带方括号[]的为可选项):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分就是协议,例如百度使用的就是https协议;
(2)hostname[:port]:第二部分就是主机名(还有端口号为可选参数),一般网站默认的端口号为80,例如百度的主机名就是www.baidu.com,这个就是服务器的地址;
(3)path:第三部分就是主机资源的具体地址,如目录和文件名等。
网络爬虫就是根据这个URL来获取网页信息的。
1.2 基本流程
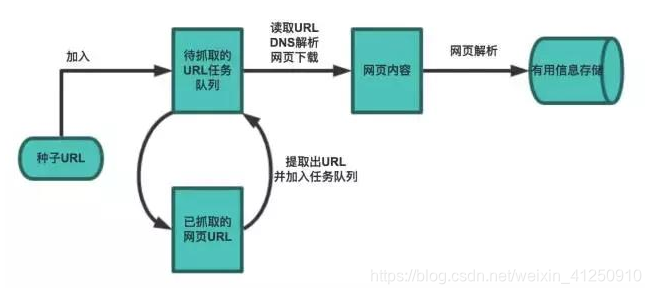
爬虫基本流程:
- 首先选取一部分种子URL
- 将种子URL加入到待抓取任务队列
- 从抓取任务队列中取出URL,解析DNS,并且获得主机IP,并将对应网页下载下来,存储下来,然后把URL放到已经抓取的任务队列中。
- 将网页中的数据解析出来。
- 分析已经抓取URL任务队列中的URL,其中包含的其他URL,放到待抓取的任务队列中。从而进去下一次循环。
2.1 urllib
urllib提供了一系列用于操作URL的功能。
Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库,其主要包括一下模块:
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
GET
我们使用urllib.request.urlopen()这个接口函数就可以很轻松的打开一个网站,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应,urlopen参数如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib使用使用request.urlopen()打开和读取URLs信息,返回的对象response如同一个文本对象,我们可以调用read(),进行读取,同样也可以使用geturl()方法、info()方法、getcode()方法。
- geturl()返回的是一个url的字符串;
- info()返回的是一些meta标记的元信息,包括一些服务器的信息;
- getcode()返回的是HTTP的状态码,如果返回200表示请求成功。
例如,对csdn首页https://www.csdn.net进行抓取,并返回响应:
from urllib import request
with request.urlopen('https://www.csdn.net/') as f:
data = f.read()
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', data.decode('utf-8'))
# 可以看到HTTP响应的头和JSON数据:
'''
Status: 200 OK
Server: openresty
Date: Mon, 15 Jul 2019 07:31:40 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: close
Vary: Accept-Encoding
Set-Cookie: uuid_tt_dd=10_35252089750-1563175899898-449903; Expires=Thu, 01 Jan 2025 00:00:00 GMT; Path=/; Domain=.csdn.net;
Set-Cookie: dc_session_id=10_1563175899898.455037; Expires=Thu, 01 Jan 2025 00:00:00 GMT; Path=/; Domain=.csdn.net;
Vary: Accept-Encoding
Strict-Transport-Security: max-age=31536000
Data: <!DOCTYPE html>...</script></div></html>
'''
如果我们要想模拟浏览器发送GET请求,就需要使用Request对象,通过往Request对象添加http请求头User-Agent,我们就可以把请求伪装成浏览器。例如,模拟手机端iphone6去请求csdn首页:
from urllib import request
req = request.Request('https://www.csdn.net')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))
#返回适合iPhone的移动版网页:
'''
<meta charset="utf-8">
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no">
'''
User Agent
有一些网站不喜欢被爬虫程序访问,所以会检测连接对象,如果是爬虫程序,也就是非人点击访问,它就会不让你继续访问,所以为了要让程序可以正常运行,需要隐藏自己的爬虫程序的身份。此时,我们就可以通过设置User Agent的来达到隐藏身份的目的,User Agent的中文名为用户代理,简称UA。
User Agent存放于Headers中,服务器就是通过查看Headers中的User Agent来判断是谁在访问。在Python中,如果不设置User Agent,程序将使用默认的参数,那么这个User Agent就会有Python的字样,如果服务器检查User Agent,那么没有设置User Agent的Python程序将无法正常访问网站。
Python允许我们修改这个User Agent来模拟浏览器访问,它的强大毋庸置疑。
常用的浏览器请求头User-Agent汇总:
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
f.read().decode(‘utf-8’) 这就是浏览器接收到的信息,只不过我们在使用浏览器的时候,浏览器已经将这些信息转化成了界面信息供我们浏览。当然这些代码我们也可以从浏览器中点击(F12或者开发者选项中)查看到。当然这个前提是我们已经知道了这个网页是使用utf-8编码的,怎么查看网页的编码方式呢?需要人为操作,且非常简单的方法是使用使用浏览器开发者选项,只需要找到head标签开始位置的chareset,就知道网页是采用何种编码的了。如下:

POST
我们可以使用data参数,向服务器发送数据。根据HTTP规范,GET用于信息获取,POST是向服务器提交数据的一种请求,
如果没有设置urlopen()函数的data参数,HTTP请求采用GET方式,也就是我们从服务器获取信息,如果我们设置data参数,HTTP请求采用POST方式,也就是我们向服务器传递数据。
data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式,具体格式我们不用了解, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
举例子说明:向有道翻译发送data,得到翻译结果。
具体详情见:https://blog.csdn.net/weixin_42251851/article/details/80489403
urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。
2.2 requests
Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,而且,缺少很多实用的高级功能。
更好的方案是使用requests。它是一个Python第三方库,处理URL资源特别方便。
使用requests要通过GET访问一个页面,只需要几行代码:
import requests
r = requests.get('https://www.csdn.net/')
print(r.status_code)
print(r.text)
对于带参数的URL,传入一个dict作为params参数:
r = requests.get('https://www.douban.com/search', params={'q': 'python', 'cat': '1001'})
print(r.url) # 实际请求的URL
'''
'https://www.douban.com/search?q=python&cat=1001'
'''
requests自动检测编码,可以使用encoding属性查看:
print(r.encoding)
'''
'utf-8'
'''
无论响应是文本还是二进制内容,我们都可以用content属性获得bytes对象:
print(r.content)
'''
b'<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
...'
'''
requests的方便之处还在于,对于特定类型的响应,例如JSON,可以直接获取:
r = requests.get('https://query.yahooapis.com/v1/public/yql?
r.json()
需要传入HTTP Header时,我们传入一个dict作为headers参数:
r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})
要发送POST请求,只需要把get()方法变成post(),然后传入data参数作为POST请求的数据:
r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'})
requests默认使用application/x-www-form-urlencoded对POST数据编码。如果要传递JSON数据,可以直接传入json参数:
params = {'key': 'value'}
r = requests.post(url, json=params) # 内部自动序列化为JSON
类似的,上传文件需要更复杂的编码格式,但是requests把它简化成files参数:
upload_files = {'file': open('report.xls', 'rb')}
r = requests.post(url, files=upload_files)
在读取文件时,注意务必使用’rb’即二进制模式读取,这样获取的bytes长度才是文件的长度。
把post()方法替换为put(),delete()等,就可以以PUT或DELETE方式请求资源。
除了能轻松获取响应内容外,requests对获取HTTP响应的其他信息也非常简单。例如,获取响应头:
r.headers
requests对Cookie做了特殊处理,使得我们不必解析Cookie就可以轻松获取指定的Cookie:
print(r.cookies['ts'])
'''
'example_cookie_12345'
'''
要在请求中传入Cookie,只需准备一个dict传入cookies参数:
cs = {'token': '12345', 'status': 'working'}
r = requests.get(url, cookies=cs)
最后,要指定超时,传入以秒为单位的timeout参数:
r = requests.get(url, timeout=2.5) # 2.5秒后超时
更多详细介绍,可参考:https://blog.csdn.net/pittpakk/article/details/81218566
https://www.liaoxuefeng.com/wiki/1016959663602400/1183249464292448