概述
全文引擎使用全文索引中的信息来编译可快速搜索表中的特定词或词组的全文查询。全文索引将有关重要的词及其位置的信息存储在数据库表的一列或多列中。全文索引是一种特殊类型的基于标记的功能性索引,它是由 SQL Server 全文引擎生成和维护的。生成全文索引的过程不同于生成其他类型的索引。全文引擎并非基于特定行中存储的值来构造 B 树结构,而是基于要编制索引的文本中的各个标记来生成倒排、堆积且压缩的索引结构。在 SQL Server 2008 中,全文索引大小仅受运行 SQL Server 实例的计算机的可用内存资源限制。
最近遇到一个需求,需要在一个100万的表中通过关键字对一个大型字符字段进行检索,类似于百度搜索引擎的搜索,查询出所有包含关键字的数据并进行分页处理,并且将匹配度最高的数据排在第一位,要求查询响应时间控制在1秒左右。
测试环境:SQL Server 2008 r2
目录
全文索引概念
- 全文索引是针对数据表,只能对表创建全文索引,不能对数据库创建全文索引。
- 每个数据库可以不包含全文目录或包含多个全文目录,一个全文目录可以包含多个全文索引,但一个全文索引只能用于构成一个全文目录。
- 一个数据表只能创建一个全文索引,一个全文索引可以包含多个字段。
- 创建全文索引的表必须要有一个唯一的非空索引,并且这个唯一的非空的索引只能是一个字段,不能是组合字段。
- 每个表只允许有一个全文索引。若要对某个表创建全文索引,该表必须具有一个唯一且非 Null 的列。您可以对以下类型的列创建全文索引:char、varchar、nchar、nvarchar、text、ntext、image、xml、varbinary 和 varbinary(max),从而可对这些列进行全文搜索。对数据类型为 varbinary、varbinary(max)、image 或 xml 的列创建全文索引需要您指定类型列。类型列是用来存储每行中文档的文件扩展名(.doc、.pdf、xls 等)的表列。
全文搜索由全文引擎提供支持。全文引擎有两个角色:索引支持和查询支持。
全文搜索体系结构:
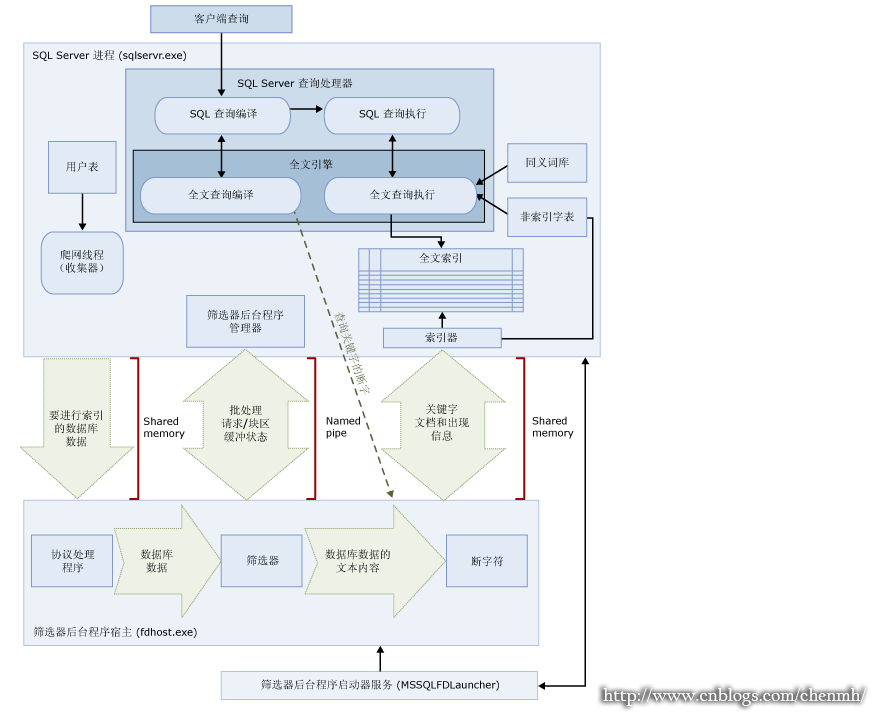
从 SQL Server 2008 开始,全文搜索体系结构包括以下进程:
- SQL Server 进程 (sqlservr.exe)
- 筛选器后台程序宿主进程 (fdhost.exe)。
SQL Server 进程组件:
- 用户表 这些表包含要进行全文索引的数据。
- 全文收集器 全文收集器使用全文爬网线程。它负责计划和驱动对全文索引的填充,并负责监视全文目录。
- 同义词库文件 这些文件包含搜索项的同义词。
- 非索引字表对象 非索引字表对象包含对搜索无用的常见词列表。
- SQL Server 查询处理器 查询处理器编译并执行 SQL 查询。如果 SQL 查询包含全文搜索查询,则在编译和执行期间该查询都会发送到全文引擎。查询结果将与全文索引相匹配。
- 全文引擎 SQL Server 中的全文引擎现已与查询处理器完全集成。全文引擎编译和执行全文查询。作为查询执行的一部分,全文引擎可能会接收来自同义词库和非索引字表的输入。在 SQL Server 2008 和更高版本中,SQL Server 的全文引擎在 SQL Server 查询处理器内部运行。
- 索引编写器(索引器) 索引编写器生成用于存储索引标记的结构。
- 筛选器后台程序管理器 筛选器后台程序管理器负责监视全文引擎筛选器后台程序宿主的状态。
筛选器后台程序宿主组件:
筛选器后台程序宿主是一个由全文引擎启动的进程。它运行下列全文搜索组件,这些组件负责对表中的数据进行访问、筛选和断字,同时还负责对查询输入进行断字和提取词干:
筛选器后台程序宿主的组件如下:
- 协议处理程序 此组件从内存中取出数据,以进行进一步的处理,并访问指定数据库的用户表中的数据。其职责之一是从全文索引列中收集数据,并将所收集的数据传递给筛选器后台程序宿主,从而由该宿主根据需要应用筛选和断字符。
- 筛选器 某些数据类型需要筛选,然后才能为文档中的数据(包括 varbinary、varbinary(max)、image 或 xml 列中的数据)创建全文索引。给定文档采用何种筛选器取决于文档类型。例如,Microsoft Word (.doc) 文档、Microsoft Excel (.xls) 文档和 XML (.xml) 文档分别使用不同的筛选器。然后,筛选器从文档中提取文本块区,删除嵌入的格式并保留文本,如有可能的话也会保留有关文本位置的信息。结果将以文本化信息流的形式出现。
- 断字符和词干分析器 断字符是特定于语言的组件,它根据给定语言的词汇规则查找词边界(“断字”)。每个断字符都与用于组合动词及执行变形扩展的特定于语言的词干分析器组件相关联。在创建索引时,筛选器后台程序宿主使用断字符和词干分析器来对给定表列中的文本数据执行语言分析。与全文索引中的表列相关的语言将决定为列创建索引时要使用的断字符和词干分析器。
创建全文索引
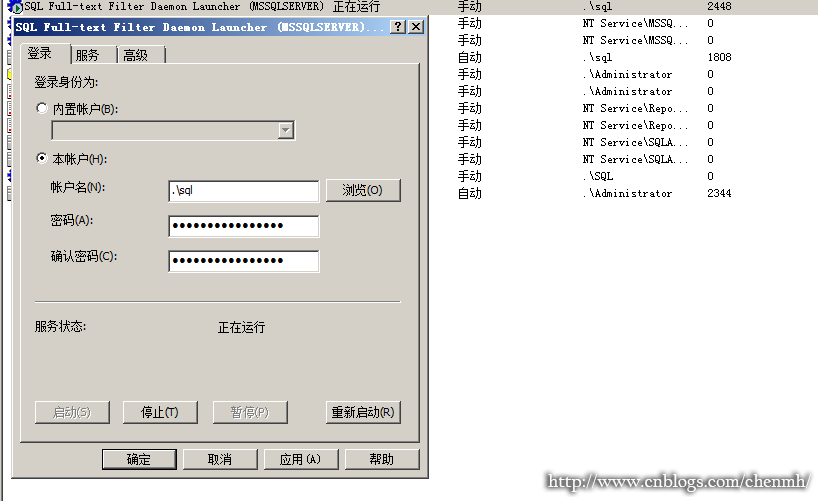
启动服务
在SQL Server配置管理工具中,找到'SQL Full-text Filter Daemon Launcher'服务用本地用户启动。
创建全文目录
打开需要创建全文目录的数据库-存储-全文目录-右键新建全文目录

用语句创建全文目录
CREATE FULLTEXT CATALOG [FD_HouseSearch]WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
AUTHORIZATION [dbo]
此外还可以通过存储过程创建全文目录,并且可以指定全文目录文件所在磁盘上的位置,如下所示:

USE [pratice]
GO
--创建全文索引的方式1:
-------------开启全文索引和创建全文索引目录 全文目录创建的路径是D:fulltext
--fulltext_pratice是自己自定义的全文目录名称
EXEC [sys].[sp_fulltext_database] @action = 'enable' -- varchar(20)
--如果数据库中已存在全文目录fulltext_pratice要先drop掉
--EXEC [sys].[sp_fulltext_catalog] @ftcat = 'fulltext_pratice', -- sysname
-- @action = 'drop' -- varchar(20)
EXEC [sys].[sp_fulltext_catalog] @ftcat = 'fulltext_pratice', -- sysname
@action = 'create', -- varchar(20)
@path = N'D:fulltext' -- nvarchar(101)
当然使用SSMS创建全文目录的时候也会有一个选项叫你选择目录位置,全文索引就存放在这个位置
创建全文索引
右键需要创建全文索引的表-全文索引-定义全文索引
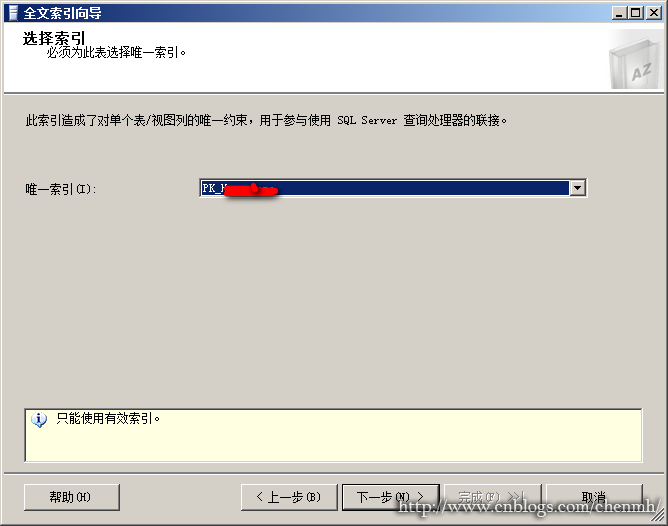
1.全文索引必须要有一个唯一非空索引,这里选择主键。
2.选择需要全文搜索的列,并且选择断字符语言,因为该字段主要用来存储中文,所以这里也选择了简体中文。
断字符:断字符用来对全文搜索数据进行语言分析,查找单词的边界,也就是怎样将一段很长的内容拆分成日常的词语或字。例如“全文搜索”,可能会断字成“全文”、‘搜索’、‘全’、‘文’、‘搜’、‘索’等符合中国人正常的习惯的词或字。
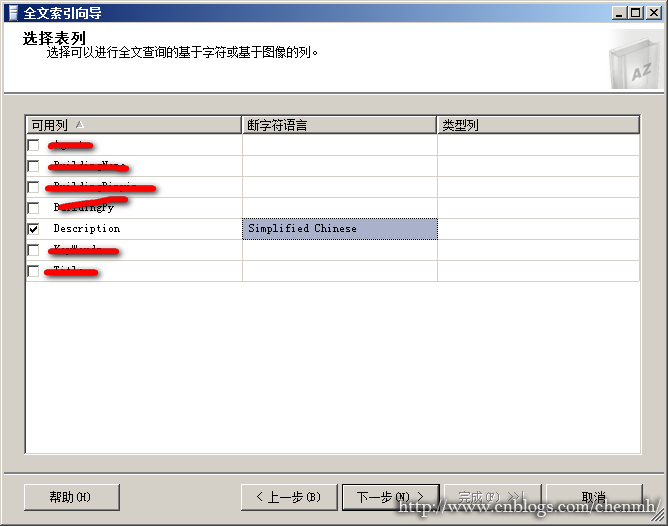
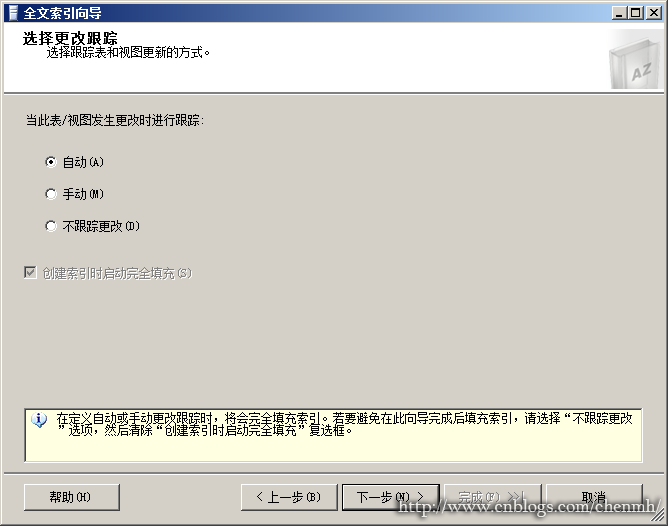
3.选择跟踪方式,这里选择自动跟踪,就是表发生更改时自动填充索引。
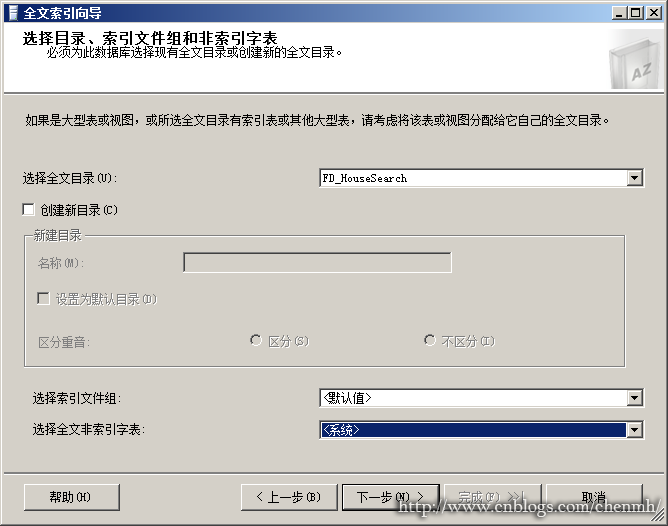
4.选择全文目录、索引文件、非索引字表
非索引字表:在刚才的断字中讲了怎样断字,这里就是将断的字保存在一张表中,该处选择系统默认的非索引字表.
----查询断字表
SELECT TOP 1000 * FROM sys.dm_fts_index_keywords(db_id(''), object_id(''))
5.填充计划
可以新建填充计划来填充全文索引,填充计划可以是完全填充、增量填充、更新填充。
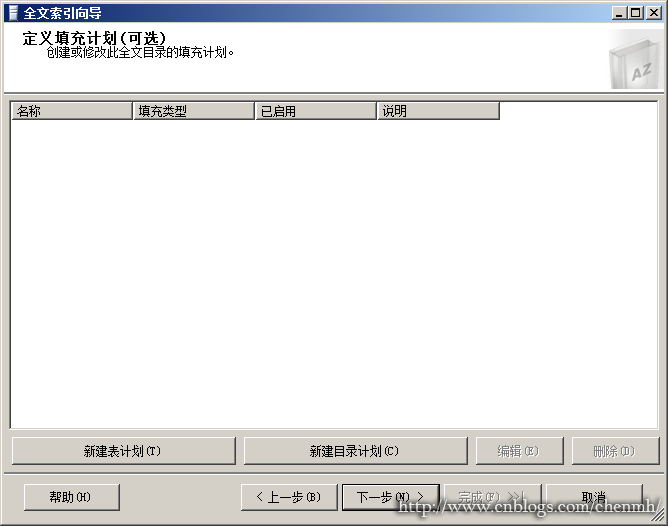

这里说明下填充计划这个东西,如果使用语句创建填充计划,其实你会发现所谓的填充计划就是一个SqlAgent里面的Job,然后执行了更新全文索引的Sql语句,如下所示用语句创建增量填充计划:
--添加作业
USE [msdb]
GO
DECLARE @jobId BINARY(16)
EXEC msdb.dbo.sp_add_job @job_name = N'启动对[fulltext_test]表增量填充', @enabled = 1,
@start_step_id = 1,
@description = N'已为数据库pratice中的全文目录 fulltext_pratice 计划了对[fulltext_test]表的增量填充。',
@job_id = @jobId OUTPUT
SELECT @jobId
GO
-----------------------------------------
--指定要运行本作业的服务器
EXEC msdb.dbo.sp_add_jobserver @job_name = N'启动对[fulltext_test]表增量填充',
@server_name = N'joe'
GO
--------------------------------------
--添加作业计划
USE [msdb]
GO
DECLARE @schedule_id INT
EXEC msdb.dbo.sp_add_jobschedule @job_name = N'启动对[fulltext_test]表增量填充',
@name = N'fulltext_test', @enabled = 1, @freq_type = 4, @freq_interval = 1,
@freq_subday_type = 1, @freq_subday_interval = 0,
@freq_relative_interval = 0, @freq_recurrence_factor = 1,
@active_start_date = 20130815, @active_end_date = 99991231,
@active_start_time = 120742, @active_end_time = 235959,
@schedule_id = @schedule_id OUTPUT
SELECT @schedule_id
GO
--------------------------------------
--添加作业步骤
USE [msdb]
GO
EXEC msdb.dbo.sp_add_jobstep @job_name = N'启动对[fulltext_test]表增量填充',
@step_name = N'全文索引', @step_id = 1, @cmdexec_success_code = 0,
@on_success_action = 1, @on_success_step_id = -1, @on_fail_action = 2,
@on_fail_step_id = -1, @retry_attempts = 0, @retry_interval = 0,
@os_run_priority = 0, @subsystem = N'TSQL', @command = N'
USE pratice
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START INCREMENTAL POPULATION
', @database_name = N'master'
GO
此外全文索引的填充计划有三种分别是
更新填充:
--(1)把自动跟踪更改设置为手动,然后UPDATE POPULATION更新填充
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL
GO
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START UPDATE POPULATION;
GO
增量填充(需要注意的是:增量填充要求数据表必须具有 timestamp 数据类型的列。 如果 timestamp 列不存在,则无法执行增量填充。另外,如果影响表全文索引的任意元数据自上次填充以来发生了变化,则增量填充请求将作为完全填充来执行。 这包括更改任何列、索引或全文索引定义所引起的元数据更改):
--(2)把自动跟踪更改设置为手动或者关闭,然后INCREMENTAL POPULATION增量填充
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL
GO
--或者
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF
GO
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START INCREMENTAL POPULATION
GO
关于Sql Server中的timestamp数据类型列的介绍,可以参考下面这段摘要:
timestamp timestamp 这种数据类型表现自动生成的二进制数,确保这些数在数据库中是唯一的。timestamp 一般用作给表行加版本戳的机制。存储大小为 8 字节。 注释 Transact-SQL timestamp 数据类型与在 SQL-92 标准中定义的 timestamp 数据类型不同。SQL-92 timestamp 数据类型等价于 Transact-SQL datetime 数据类型。 Microsoft® SQL Server™ 将来的版本可能会修改 Transact-SQL timestamp 数据类型的行为,使它与在标准中定义的行为一致。到那时,当前的 timestamp 数据类型将用 rowversion 数据类型替换。 Microsoft® SQL Server™ 2000 引入了 timestamp 数据类型的 rowversion 同义词。在 DDL 语句中尽可能使用 rowversion 而不使用 timestamp。rowversion 受数据类型同义词行为的制约。有关更多信息,请参见数据类型同义词。 在 CREATE TABLE 或 ALTER TABLE 语句中,不必为 timestamp 数据类型提供列名: CREATE TABLE ExampleTable (PriKey int PRIMARY KEY, timestamp) 如果没有提供列名,SQL Server 将生成 timestamp 的列名。rowversion 数据类型同义词不具有这样的行为。指定 rowversion 时必须提供列名。 一个表只能有一个 timestamp 列。每次插入或更新包含 timestamp 列的行时,timestamp 列中的值均会更新。这一属性使 timestamp 列不适合作为键使用,尤其是不能作为主键使用。对行的任何更新都会更改 timestamp 值,从而更改键值。如果该列属于主键,那么旧的键值将无效,进而引用该旧值的外键也将不再有效。如果该表在动态游标中引用,则所有更新均会更改游标中行的位置。如果该列属于索引键,则对数据行的所有更新还将导致索引更新。 不可为空的 timestamp 列在语义上等价于 binary(8) 列。可为空的 timestamp 列在语义上等价于 varbinary(8) 列。
完全填充:
--(3)把自动跟踪更改设置为关闭,然后进行完全填充,一般完全填充只在刚刚创建完全文索引的时候使用
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF
GO
ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START FULL POPULATION
GO
这三种填充类型的详细解释,请见如下MSDN链接:
https://msdn.microsoft.com/zh-cn/library/ms142575.aspx
用语句创建全文索引
--语句少了很多默认参数,其它就按系统默认即可
CREATE FULLTEXT INDEX ON dbo.Housetest
(Description
)
KEY INDEX PK_Housetest
ON FD_HouseSearch
全文谓词
全文查询使用全文谓词(CONTAINS 和 FREETEXT)以及全文函数(CONTAINSTABLE 和 FREETEXTTABLE)。它们支持复杂的 Transact-SQL 语法,这种语法支持各种形式的查询词。若要编写全文查询,必须了解何时以及如何使用这些谓词和函数。
CONTAINS 谓词可以搜索:
- 词或短语。
- 词或短语的前缀。
- 与另一个词相邻的词。
- 由另一个词的词形变化而生成的词(例如,drive 一词是 drives、drove、driving 和 driven 词形变化的词干)。
- 使用同义词库确定的另一个词的同义词(例如,metal 一词可能有 aluminum 和 steel 等同义词)。
---下面的示例将查找包含 "Mountain"
USE AdventureWorks2008R2;
GO
SELECT Name, ListPrice
FROM Production.Product
WHERE CONTAINS(Name, 'Mountain');
GO
--下面的示例将查找包含 "Mountain"或 "Road"
USE AdventureWorks2008R2;
GO
SELECT Name
FROM Production.Product
WHERE CONTAINS(Name, ' "Mountain" OR "Road" ')
GO
---下面的示例返回的所有产品名称中,其 Name 列中至少有一个词以前辍 chain 开头
USE AdventureWorks2008R2;
GO
SELECT Name
FROM Production.Product
WHERE CONTAINS(Name, ' "Chain*" ');
GO
FREETEXT谓词的用法这里就不做解释了!
需求
现在来说一下我最近的需求,表数据100万条,数据这里就不弄出来了,只把方案说一下,title类似于文章的标题,Description是内容也是全文索引字段
方案1:like,测试后果断排除, like关键字根本就不会用到全文索引,所以like做模糊查询的效率非常差。
方案2:直接使用全文搜索进行,排序消耗大。
方案3:由于查询需要对Title进行排序,建Title字段的倒序索引包含其它字段,最后选择该方案(创建Title字段的倒序索引很重要)。
--给出部分字段
CREATE TABLE [dbo].[Housetest](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Title] [varchar](200) NULL,
[Description] [nvarchar](max) NOT NULL,
[IsOnline] [tinyint] NOT NULL,
CONSTRAINT [PK_Housetest] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
创建索引
CREATE INDEX IX_Housetest ON Housetest
(Title DESC
)
INCLUDE
(ID,
Description,
IsOnline
)
查询Description包含“美园”,并且如果Title是“美园”则排在第一位,并且以分页的形式显示,每页20条记录。
select * from (SELECT ROW_NUMBER() OVER(Order by (case when Title='美园' Then 1 Else 0 End) desc ) as RowsNumber,ID,Title,Description
From Housetest
Where contains(Description,'美园') and IsOnline=1) tab1
where RowsNumber between 1 and 20

总结
大家不要拿这个与搜索引擎做对比,肯定是没法比的,因为我这里只需要解决需求就好,所以方案适合我目前的需求。
全文索引功能类似于百度的搜索引擎,但是百度这类搜索引擎有自己的数据字典,在关键字表中对关键字进行排序,保存关键字对应的 文档id,一个文档只会保留很少的关键字,就跟平时写文章要添加标签一样,一般一篇文章就几个标签,当搜索的时候匹配的速度就会非常快,这就需要一个很完善的数据字典表。
全文搜索还有另外的一个功能就是FileStream,需要添加文件流,在服务中启用该功能可以在字段中将文档以二进制的形式保存在字段当中,这样大型文档也可以随数据库一起备份,很多网站存储图片都是存储图片的路径,这样备份数据库的时候图片不会一起备份。
全文索引带来好处的同时也会对性能有一定的影响,特别是在进行筛选操作的时候对服务器性能会带来影响,所以选择一个功能的同时需要考虑对性能带来的影响。
这里有个题外话,全文搜索也会用到操作系统的搜索服务,详情点击这里
全文索引不方便的地方:备份,还原,附加数据库非常不方便,需要特别指定全文目录的文件夹,是否需要附加全文目录,之前项目经理就是这个原因而放弃使用
全文搜索,他之前搞的一个网站的评论功能就需要使用全文搜索,听他说自从那次使用全文搜索之后现在都没有使用了,现在他使用like关键字来代替全文
但是,因为全文有分词,数据压缩,搜索条件比较灵活等功能所以个人觉得like关键字是没有办法和全文搜索比较的