机器学习主要工作大致分为以下几步,数据预处理,包括数据切分,特征选取,数据缺失值处理,来了解数据。接下来分割数据,分别分出训练集和测试集。第三步,选择模型,使用训练数据训练模型参数,再对测试数据进行预测,保存预测结果。第四步,对预测结果性能分析,根据分析结论调节参数。
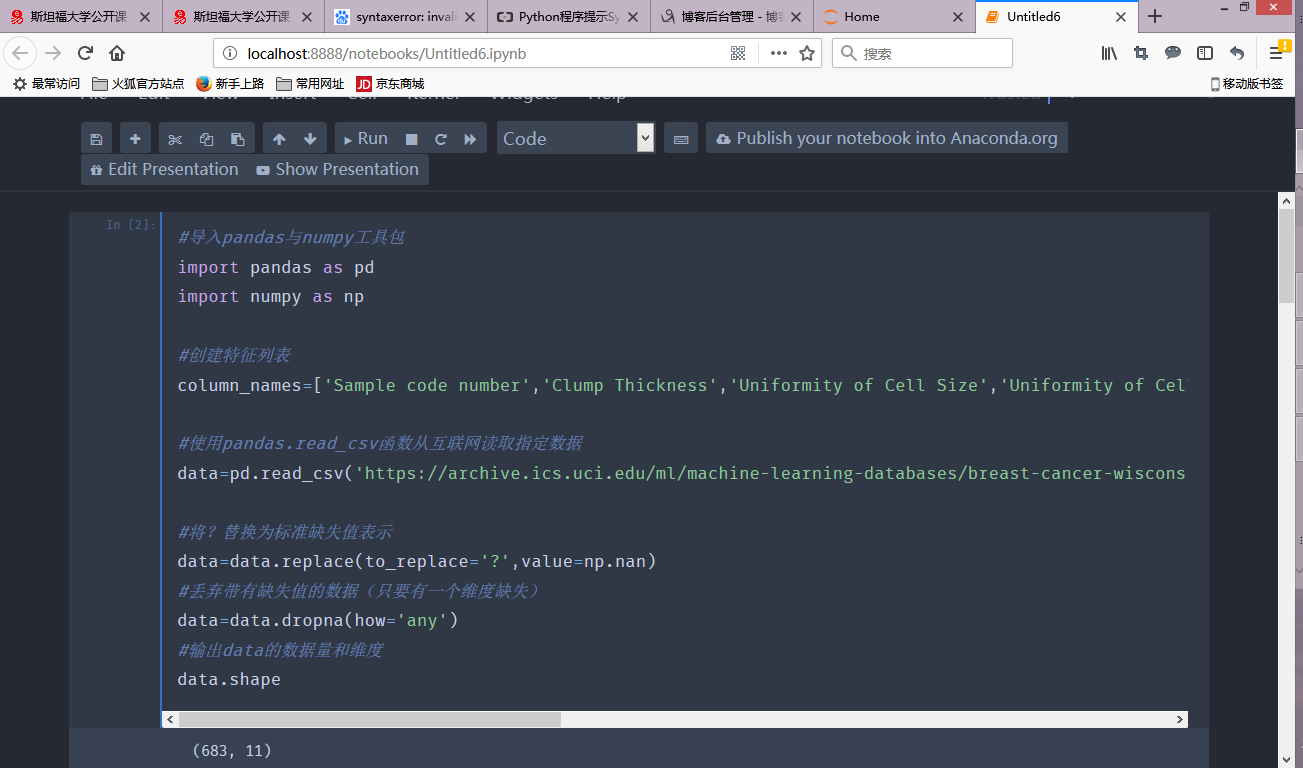
pandas包处理数据,分析数据
numpy包提供高级的数学运算和高效的向量及矩阵运算能力
pandas.read_csv函数从互联网读取指定数据
查看data数据量和维度 data.shape
使用sklearn.cross_valiation中的train_test_split模块切分数据
训练模型参数前,标准化数据,保证每个维度的特征数据方差为1,均值为0.使得预测结果不会被某些过大的特征值主导(会不会说明什么问题?),这里使用sklearn.preprocessing中的X_train=StandardScaler.fit_transform(X_train)
觉得jupyter默认风格不太好看,搜了下如何个性化设置
pip install --jupyterthemes
jt -l#查询主题
……
期间遇到下载不成功的问题,除了是网渣渣,还有cannot remove****问题,解决***condone setuptools
还有就是 要把打开的notbook关掉!
不怕遇上事!一会可以安心吃晚饭了:)