redis-cluster的优势
· 高并发,redis号称单例10万并发,但是毕竟是有限的。
· 分布式架构,把数据分配到不同的位置,一起完成一项工作,减轻的集中式的压力,解决内存过载的问题。
数据库分布理论
分布式数据库就是把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
常见的分区规则有顺序分区和哈希分区,其中哈希分区又分为节点取余分区,一致性哈希分区,虚拟槽分区等。
顺序分区
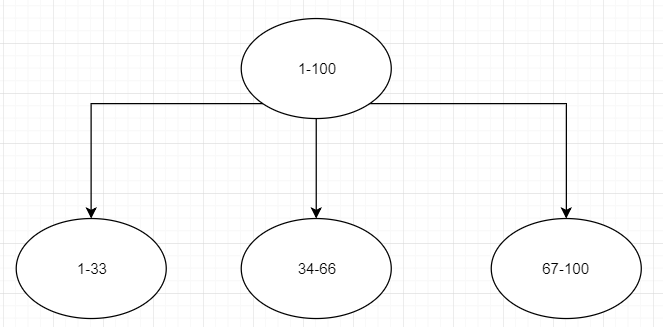
节点取余分区
如果分为三个节点,1-100的数据对3取余,那么余数可以分为0,1,2三种来进行分区,那么如果是4个节点就是hassh(key)%4

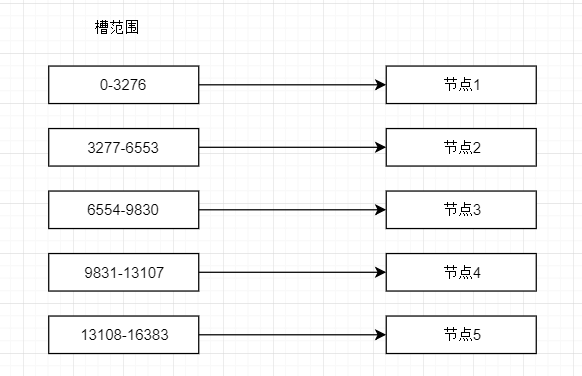
虚拟槽分区
虚拟槽分区巧妙的利用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围内的整数集合,整数的定义为槽(slot),redis的槽范围是0-16383,槽是集群内数据管理的基本单位,才有大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,每个节点复制一定数量的槽。计算公式为:slot = CRC16(key)&16383。
redis-cluster搭建
多个从服务端负责读写,彼此通信,redis指定了16384个槽位,把槽位分配给节点来管理数据(ruby脚本自动完成)。
搭建集群的步骤:
1,准备节点;2,节点通信;3,分配槽位给节点。
环境准备
1,配置redis.conf,开启redis-cluster。
port 7000 daemonize yes dir "/opt/redis/data" logfile "7000.log" dbfilename "dump-7000.rdb" cluster-enabled yes #开启集群模式 cluster-config-file nodes-7000.conf #集群内部的配置文件 cluster-require-full-coverage no #redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no
2,准备ruby环境
#下载ruby wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz #安装ruby tar -xvf ruby-2.3.1.tar.gz ./configure --prefix=/opt/ruby/ make && make install #准备一个ruby命令 #准备一个gem软件包管理命令 #拷贝ruby命令到path下/usr/local/ruby cp /opt/ruby/bin/ruby /usr/local/ cp bin/gem /usr/local/bin
3,安装gem包管理工具
wget http://rubygems.org/downloads/redis-3.3.0.gem gem install -l redis-3.3.0.gem #查看gem有哪些包 gem list -- check redis gem
4,创建软连接
ln -c /opt/redis/src/redis-trib.rb /usr/local/bin/
开启redis-cluster集群
#每个主节点,有一个从节点,代表--replicas 1 redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 #集群自动分配主从关系 7000、7001、7002为 7003、7004、7005 主动关系
查看集群状态
redis-cli -p 7000 cluster info redis-cli -p 7000 cluster nodes #等同于查看nodes-7000.conf文件节点信息 集群主节点状态 redis-cli -p 7000 cluster nodes | grep master 集群从节点状态 redis-cli -p 7000 cluster nodes | grep slave