elasticsearch是什么:
elasticsearch 简称es,是一款基于Lucene的分布式搜索和分析引擎。它由索引(index),类型(type),文档(document),字段(field)这些基本元素组成搜索系统。
简单来说就是,当这种全文搜索的场景在使用数据库去搜索时,由于需要在所有数据中去找到对应的数据,那边就需要遍历数据库的所有数据,非常的占用数据库的资源,而且效率非常的低下。这款ES的搜索服务就是代替服务器处理这种全局搜索的场景的。至于它为什么适合这样的场景,就不得不提到它的一个索引规则:倒排索引。
倒排索引:
倒排索引表中的每一项都包括一个属性值和具有该属性值的各记录地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,这种索引称为倒排索引。
倒排索引中的索引对象是文档或者文档集合中的单词,用来存储这些单词在一个文档或者一组文档中的存储位置。
倒排索引的关键要素是关键词,频度(词的出现次数),位置(出现在文档中的位置)。好比中华词典,用户可以根据知道对应的字或者拼音,定位到对应的页码找到对应的注解。不用一页一页的翻看查找。
举个例子:
文章1:tom lives in zhej, i live in zhej too.
文章2:he once lived in beijing.
1.首先我们要取得两篇文章的关键词,第一步就是分解字符串,将其拆分成一个个单词,即分词。英文单词由于用空格分隔,比较好处理。中文单词由于是连在一起的,所以需要特殊的分词处理。
2.文章中的 in, once, too,等词没有实际的意义,跟中文中的 '的',‘是’等字类似,都不具备实际的意义。这些不代表概念的词可以过滤掉。
3.用户查询‘he’时通常希望能把‘he’和'HE'的文章都找出来,所以所有的单词都需要统一大小写。
4.用户通常还希望查询live时能把lives 和lived的文章也都查询出来,那么需要把lives 和lived 还原成live。
5.文章中的标点符号通常也会被过滤掉。
以上的这些过滤方式和规则是通过lucene的analyzer (分词器)去做的。不同的分词器有不同的过滤规则,适合不同的使用场景,ES可以在对应的字段上去创建不同的分词器,来实现数据的过滤。
得到的结果:
文章1:[tom][live][zhej][i][live][zhej]
文章2:[he][live][beijing]
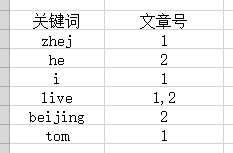
这个是倒排索引建立后的表格,将关键词和拥有该关键词对应的文章号的关系建立好。
通常知道关键词所在的文章号还不足以满足需求,还需要知道关键词在文章中出现的次数及位置。在加上出现次数和出现位置后的表格:
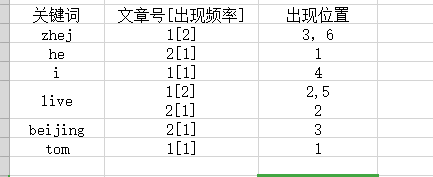
以live为例说明一下结构:live在文章1中出现2次,在文章2中出现1次,在文章1中出现的位置是2,5 在文章2中出现的位置是2。