Linux内核实现了操作系统的三⼤核⼼功能,即进程管理、内存管理和⽂件系统,对应操作系统原理课程中最重要的 3 个抽象概念是进程、虚拟地址和⽂件。其中,操作系统内核中最核⼼的功能是进程管理。本课程重点讲述的是进程管理和中断机制。
本课程内容概阔:
进程管理:管理最核心的CPU资源,保证各个进程能够合理地利用CPU资源完成自身任务。
内存管理:管理内存资源,使得内存被进程安全使用。
虚拟文件系统:为方便对外设进行管理,将如硬盘、光盘等外设均抽象为虚拟文件,Linux内核提供诸如open、write、read等接口函数对其统一管理。
网络系统:管理涉及网络操作的资源。
进程间通信:为进程间交流资源提供渠道。
Linux内核
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。
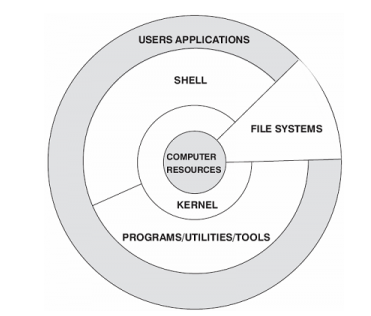
内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。
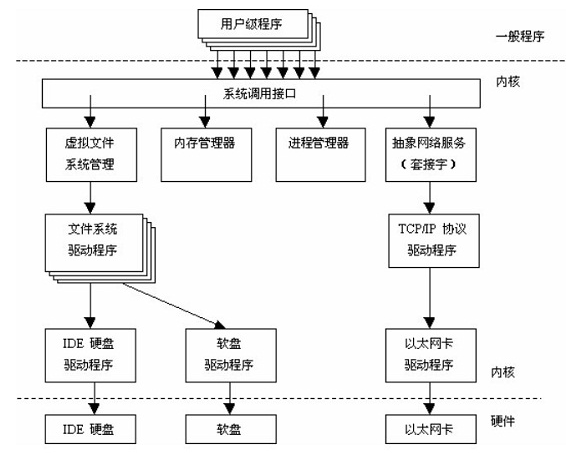
Linux 内核由如下几部分组成:内存管理、进程管理、设备驱动程序、文件系统和网络管理等。如图:
进程:
在操作系统原理中,我们通过进程控制块PCB描述进程。为了管理进程,内核要描述进程的结构,我们也称其为进程描述符,进程描述符直接或间接提供了进程相关的所有信息。
struct task_struct { ...... /* 进程状态 */ volatilelongstate; /* 指向内核栈 */ void*stack; /* 用于加入进程链表 */ structlist_head tasks; ...... /* 指向该进程的内存区描述符 */ structmm_struct*mm,*active_mm; ...... /* 进程ID,每个进程(线程)的PID都不同 */ pid_t pid; /* 线程组ID,同一个线程组拥有相同的pid,与领头线程(该组中第一个轻量级进程)pid一致,保存在tgid中,线程组领头线程的pid和tgid相同 */ pid_t tgid; /* 用于连接到PID、TGID、PGRP、SESSION哈希表 */ structpid_link pids[PIDTYPE_MAX]; ...... /* 指向创建其的父进程,如果其父进程不存在,则指向init进程 */ structtask_struct __rcu *real_parent; /* 指向当前的父进程,通常与real_parent一致 */ structtask_struct __rcu *parent; /* 子进程链表 */ structlist_head children; /* 兄弟进程链表 */ structlist_head sibling; /* 线程组领头线程指针 */ structtask_struct*group_leader; /* 在进程切换时保存硬件上下文(硬件上下文一共保存在2个地方: thread_struct(保存大部分CPU寄存器值,包括内核态堆栈栈顶地址和IO许可权限位),内核栈(保存eax,ebx,ecx,edx等通用寄存器值)) */ structthread_struct thread; /* 当前目录 */ structfs_struct*fs; /* 指向文件描述符,该进程所有打开的文件会在这里面的一个指针数组里 */ structfiles_struct*files; ...... /*信号描述符,用于跟踪共享挂起信号队列,被属于同一线程组的所有进程共享,也就是同一线程组的线程此指针指向同一个信号描述符 */ structsignal_struct*signal; /*信号处理函数描述符 */ structsighand_struct*sighand; ...... }
值得一提的是,task_struct数据结构的最后是保存进程上下⽂中CPU相关的⼀些状态信息的关键数据结构thread。struct thread_struct数据结构内部最关键的是sp和ip。sp⽤来保存进程上下⽂中的ESP寄存器状态,ip⽤来保存进程上下⽂中的EIP寄存器状态。
进程的生命周期
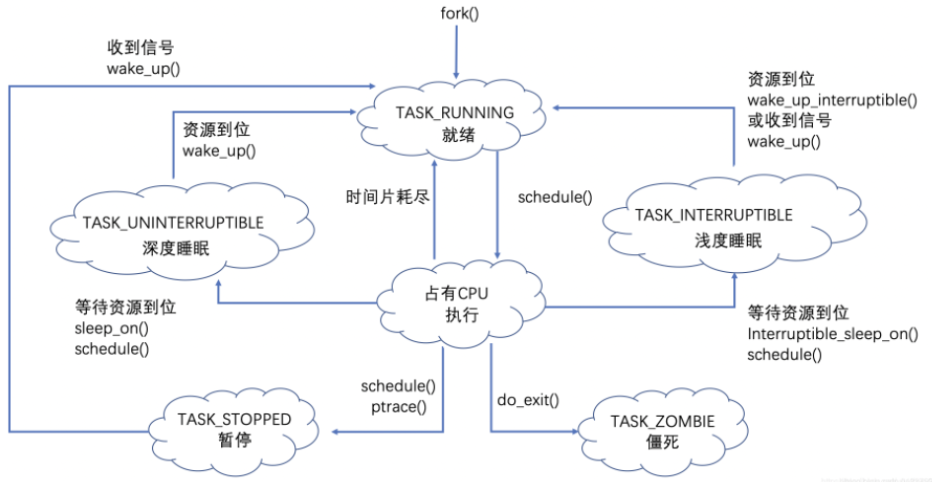
操作系统原理中的进程有就绪态、运⾏态、阻塞态这3种基本状态,实际的Linux内核管理的进程状态则与原理稍有出入,如原理中的就绪态和运行态,在linux中都是TASK_RUNNING态。在Linux中,进程的状态划分比原理更加复杂,如终止态中又多了僵尸态;阻塞态也有两种:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE。
进程的创建:
库函数fork是⽤户态创建⼀个⼦进程的系统调⽤API接⼝。
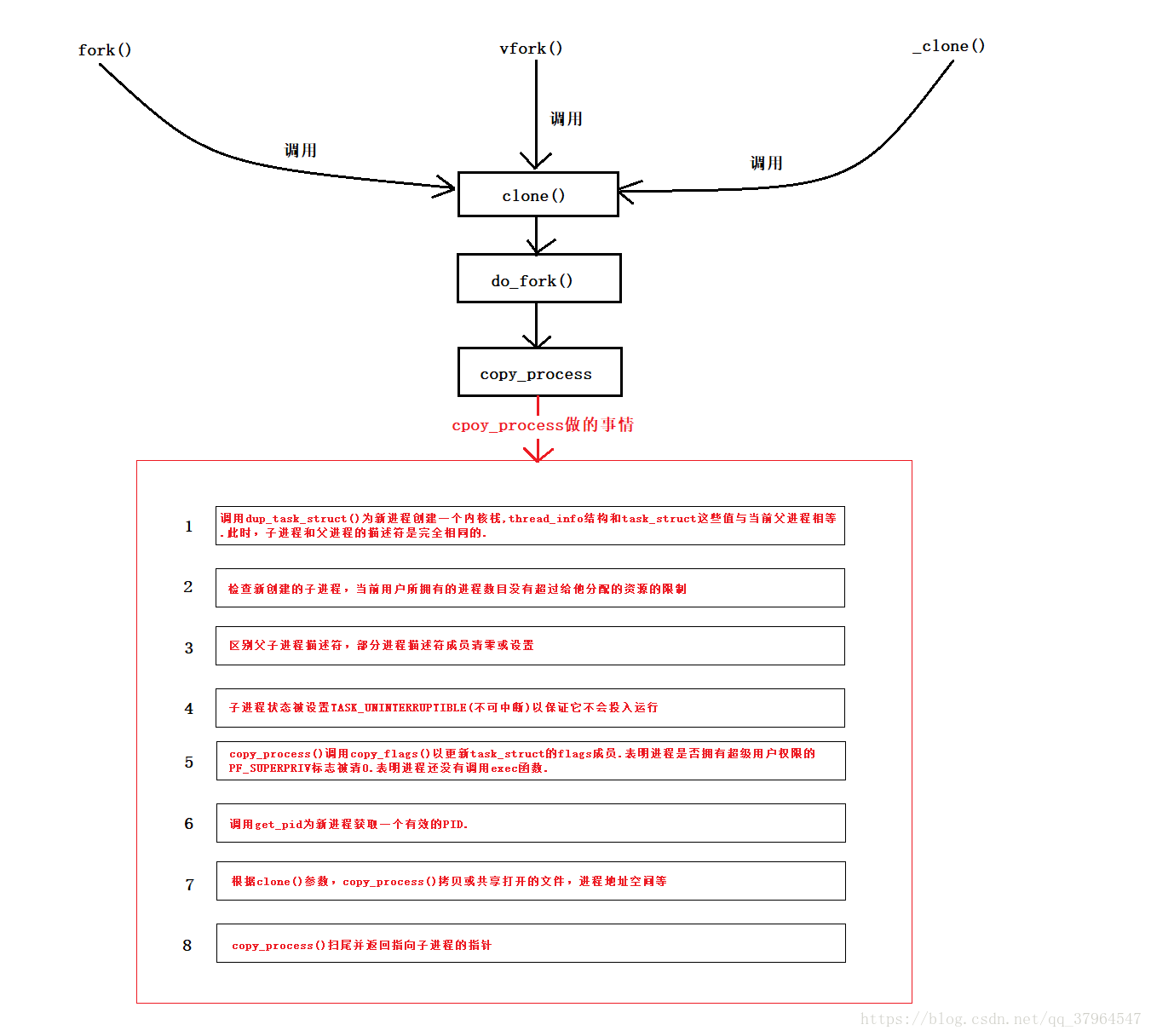
fork系统调⽤把当前进程⼜复制了⼀个⼦进程,也就⼀个进程变成了两个进程,两个进程执⾏相同的代码,只是fork系统调⽤在⽗进程和⼦进程中的返回值不同。
fork也是⼀个系统调⽤,和前述⼀般的系统调⽤执⾏过程⼤致是⼀样的。尤其从⽗进程的⻆度来看,fork的执⾏过程与前述描述完全⼀致。
fork系统调⽤创建了⼀个⼦进程,⼦进程复制了⽗进程中所有的进程信息,包括内核堆栈、进程描述符等,⼦进程作为⼀个独⽴的进程也会被调度,当⼦进程获得CPU开始运⾏时,它是从哪⾥开始运⾏的呢?从⽤户态空间来看,就是fork系统调⽤的下⼀条指令。但是,对于⼦进程来讲,fork系统调⽤在内核处理程序中是从何处开始执⾏的呢?
进程的创建过程⼤致是⽗进程通过fork系统调⽤进⼊内核_do_fork函数,采⽤写时复制技术复制进程描述符及相关进程资源、分配⼦进程的内核堆栈并对内核堆栈和thread等进程关键上下⽂进⾏初始化,最后将⼦进程放⼊就绪队列,fork系统调⽤返回;⽽⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏。
换种说法,fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位置继续向下执⾏,这和其他的系统调⽤是⼀样的。在⼦进程中fork也返回了⼀次,会返回到⼀个特定的点——ret_from_fork。
可执行程序
程序从源代码到可执⾏⽂件的编译步骤⼤致分为:预处理、编译、汇编、链接。每一步对应的shell命令如下:

汇编后形成的.o格式的⽂件已经是ELF格式⽂件了。程序编译后⽣成的⽬标⽂件⾄少含有3个节区,分别为.text、.data和.bss。BSS段通常是指⽤来存放程序中未初始化的全局变量,该节不占用文件空间;数据段通常是指⽤来存放程序中已初始化的全局变量;代码段通常是指⽤来存放程序执⾏代码。
而最后一步链接,是将各种代码和数据部分收集起来并组合成为⼀个单⼀⽂件的过程,本质上是节的拼接。链接分为静态链接和动态链接两种,各有优劣。动态链接又分为装载时动态链接和运行时动态链接。一个可执行文件被装载入内存后执行,其实是调用了exec系统调用。
在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来的那个可执⾏程序了,⽽是新的可执⾏程序。execve返回的是新的可执⾏程序执⾏的起点。
进程调度时机
Linux内核通过schedule函数实现进程调度,调⽤schedule函数的时机主要分为两类:1、中断处理过程中的进程调度时机;2、内核线程主动调⽤schedule()。换种说法,进程调度时机就是内核调用schedule函数的时机,它包括两种情况:1、⽤户进程上下⽂中主动调⽤特定的系统调⽤进⼊中断上下⽂,系统调⽤返回⽤户态之前进⾏进程调度、或者内核线程或可中断的中断处理程序,执⾏过程中发⽣中断进⼊中断上下⽂,在中断返回前进⾏进程调度;2、内核线程主动调⽤schedule函数进⾏进程调度。
进程调度策略
包括先进先出FIFO,短距离作业优先算法,时间片调度等。
文件系统
在LINUX系统中有一个重要的概念:一切都是文件。 其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。这样带来优势也是显而易见的
文件被组织到文件系统(file system)中,通常会成为一个树状(tree)结构。Linux有一个根目录/, 也就是树状结构的最顶端。这个树的分叉的最末端都代表一个文件,而这个树的分叉处则是一个目录(directory, 相当于我们在windows界面中看到的文件夹)。在图1中看到的是整个的一个文件树。如果我们从该树中截取一部分,比如说从目录vamei开始往下,实际上也构成一个文件系统。要找到一个文件,除了要知道该文件的文件名,还需要知道从树根到该文件的所有目录名。从根目录开始的所有途径的目录名和文件名构成一个路径(path)。比如说,我们在Linux中寻找一个文件app_mysql.c,不仅要知道文件名(app_mysql.c),还要知道完整路径,也就是绝对路径(/home/howin/linux/NO.8/app_mysql.c)。从根目录录/, 也就是树状结构的最顶端出发,经过目录home, howin, linux,NO.8,最终才看到文件app_mysql.c。整个文件系统层层分级(hierarchy),howin是home的子目录,而home是howin的父目录。
Linux下的文件系统结构如下:
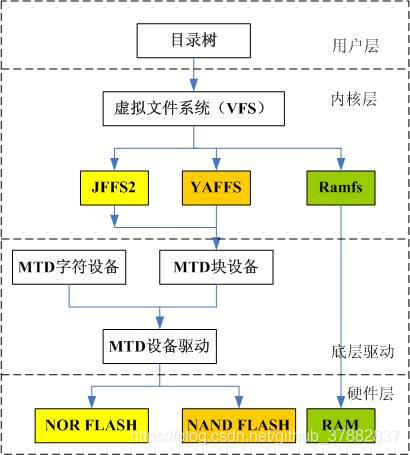
(参考博客https://blog.csdn.net/github_37882837/article/details/90672881)
Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。之后可以自动或手动挂载其他的文件系统。因此,一个系统中可以同时存在不同的文件系统。
不同的文件系统类型有不同的特点,因而根据存储设备的硬件特性、系统需求等有不同的应用场合。在嵌入式Linux应用中,主要的存储设备为RAM(DRAM, SDRAM)和ROM(常采用FLASH存储器),常用的基于存储设备的文件系统类型包括:jffs2, yaffs, cramfs, romfs, ramdisk, ramfs/tmpfs等。
文件存储结构大概如下:
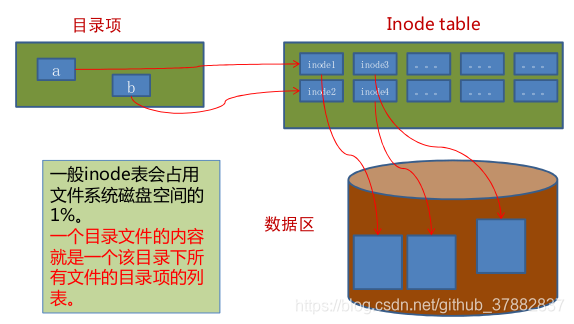
其中目录项的结构如下(每个文件的目录项存储在改文件所属目录的文件内容里):

其中文件的inode结构如下(inode里所包含的文件信息可以通过stat filename查看得到):
以上只反映大体的结构,linux文件系统本身在不断发展。但是以上概念基本是不变的。且如ext2、ext3、ext4文件系统也存在很大差别,如果要了解可以查看专门的文件系统介绍。
中断机制和系统调用
系统调用是一种特殊的中断
中断分外部中断(硬件中断)和内部中断(软件中断),内部中断⼜称为异常(Exception),异常⼜分为故障(fault)和陷阱(trap)。系统调⽤就是利⽤陷阱(trap)这种软件中断⽅式主动从⽤户态进⼊内核态的。⼀般来说,从⽤户态进⼊内核态是由中断触发的,可能是硬件中断,在⽤户态进程执⾏时,硬件中断信号到来,进⼊内核态,就会执⾏这个中断对应的中断服务例程。也可能是⽤户态程序执⾏过程中,调⽤了⼀个系统调⽤,陷⼊了内核态,叫作陷阱(trap)。所以,系统调⽤是特殊的中断。
此外,这里必须明确系统调用与普通的库函数API调用二者之间的区别。这二者间最明显的区别在于,系统调用会进入内核态,而库函数则未必。

如上图,系统调用执行的流程如下:
- 应用程序 代码调用系统调用( xyz ),该函数是一个包装系统调用的 库函数 ;
- 库函数 ( xyz )负责准备向内核传递的参数,并触发 软中断 以切换到内核;
- CPU 被 软中断 打断后,执行 中断处理函数 ,即 系统调用处理函数 ( system_call);
- 系统调用处理函数 调用 系统调用服务例程 ( sys_xyz ),真正开始处理该系统调用;
系统调用的传参方式
系统调⽤从⽤户态切换到内核态,在⽤户态和内核态这两种执⾏模式下使⽤的是不同的堆栈,即进程的⽤户态堆栈和进程的内核态堆栈,传递参数⽅法⽆法通过参数压栈的⽅式,⽽是通过寄存器传递参数的⽅式。寄存器传递参数的个数是有限制的,⽽且每个参数的⻓度不能超过寄存器的⻓度,32位x86体系结构下寄存器的⻓度最⼤32位。除了EAX⽤于传递系统调⽤号外,参数按顺序赋值给EBX、ECX、EDX、ESI、EDI、EBP(64位机为RDI、RSI、RDX、RCX、R8、R9这6个寄存器),参数的个数不能超过6个,即上述6个寄存器。如果超过6个就把某⼀个寄存器作为指针。
中断过程中中断上下文的切换过程(以系统调用为例)
int $0x80指令或syscall指令触发系统调⽤机制会在堆栈上保存⼀些寄存器的值,会保存中断发⽣时当前执⾏程序的栈顶地址(ESP、RSP)、当时的状态字(EFlags、RFlags)、当时的 CS:EIP/RIP 的值。同时会将当前进程内核态的栈顶地址、内核态的状态字放⼊ CPU 对应的寄存器,并且 CS:EIP/RIP 寄存器的值会指向中断处理程序的⼊⼝。中断保存了⽤户态 CS:EIP 的值,以及当前的堆栈段寄存器的栈顶,在 EFLAGS 寄存器的当前的值保存到内核堆栈⾥。然后执行SAVE_ALL ,完成中断服务,发⽣进程调度。如果没有发⽣进程调度,就直接 restore_all 恢复中断现场,然后 iret 返回到原来的状态。
总的来说,中断的全过程是当⼀个中断信号发⽣时,CPU把当前正在执⾏的进程X的CS:RIP寄存器和RSP寄存器等都压栈到了⼀个叫内核堆栈的地⽅,然后把CS:RIP指向⼀个中断处理程序的⼊⼝,做保存现场的⼯作,然后去执⾏其他进程⽐如Y,等重新回来时再恢复现场。
读文件的过程简述
-
进程调用库函数向内核发起读文件请求;
-
内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
-
触发系统调用sys_read(),获得当前进程的控制块,调用该文件可用的系统调用函数read()。read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
-
在inode中,通过文件内容偏移量计算出要读取的页;
-
通过inode找到文件对应的address_space;
-
在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
-
如果页缓存命中,那么直接返回文件内容;
-
如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存;
-
-
文件内容读取成功。
总结
通过本次课程我了解到linux的很多知识。对linux系统的一般执行过程有了一个概括性的框架,对中断机制、系统调用、进程管理、IO、文件管理等等概念也有了清晰的理解。
和老师一道进行分析内核中堆栈的内容及变化、看内核源码、模拟系统调用的过程。通过一次次实践作业和老师的点播,使我受益匪浅。
感谢老师们在学习上对我们的帮助,正值疫情时期,老师们积极尝试网上授课方式,不仅保证了形式也保证了质量,依然课堂和同学互动,接受学生反馈,敬业精神可见一斑。