HDFS设计目标
- 巨大的分布式文件系统:10PB以上,万个以上节点
- 运行于普通硬件:文件多重备份,探测失败和错误恢复
- 优化批处理:数据暴漏位置,以便计算能够挪到数据附近;提供高举和的带宽
- 用户控件可以位于异构的操作系统中
- 在整个集群中使用单一的命名空间
- 数据一致性:写入一次读取多次的访问模型;客户端只能追加已有的文件
- 文件被分割:默认一块64M;每一块复制到不同DataNode
- 智能客户端:客户端能找到文件块位置;客户端能直接访问DataNode中文件位置
- 程序采用“数据就近”原则分配节点执行
- 客户端对文件没有缓存机制
HDFS 缺陷
- 低延迟数据访问:毫秒级,高吞吐率
- 小文件存取:占用NameNOde大量内存;NameNode寻道时间过长
- 并发写入、文件随机修改
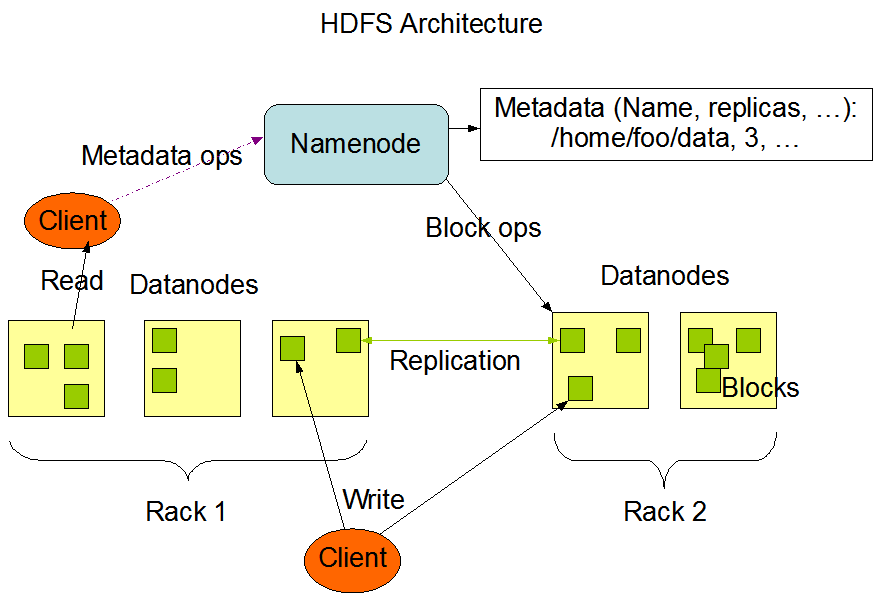
NameNode 和 DataNode
图片来自hadoop.apache.org
HDFS主/从体系结构。一个HDFS集群由一个单一的NameNode管理文件系统命名空间并控制客户端对文件的访问。此外,有许多的datanode对应一个集群中的每个节点,节点用于文件管理和存储。
HDFS公开文件系统名称空间并允许将用户数据存储在文件中。在内部,一个文件被分成一个或多个块,这些块存储在一组datanode。
NameNode执行文件系统名称空间操作,如打开,关闭,重命名文件和目录。它还决定了映射datanode的块。
datanode负责从文件系统的读写请求服务客户。
NameNode发出创建、删除和复制指令,由datanode在映射块上执行。
DataNode Blockreport默认一小时一次,HeartBeat默认三秒一次。HeartBeat带有,NameNode命令的返回结果,超过十分钟未接受心跳,则改节点不可用。
DataNode支持热启动和关闭。
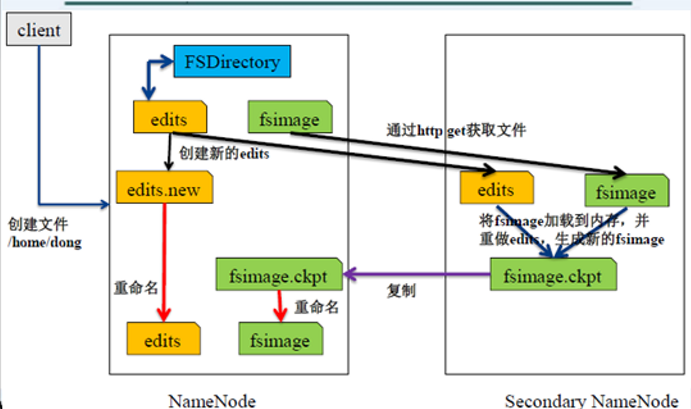
SecondaryNameNode
两个重要文件
- FSImage:元数据镜像文件(保存文件系统目录树)
- FSEdits:元数据操作日志
元数据镜像=FSImage+FSEdits
元数据镜像正常情况下保存在NameNode中。
SecondaryNameNode负责NameNode冷备份,定期合并FSImage和FSEdits。FSEdits文件会不断增大,导致NameNode速度慢。
HDFS权限管理
HDFS的权限管理和Linux类型,web端可以看到。
HDFS并没有实现严格的权限管理,文件仅仅通过用户名验证。
HDFS权限目的:阻止好人做错事,而不阻止坏人做坏事。
HDFS文件系统
层次性文件结构,类似Linux、Win,不支持软硬连接。
可以 创建、移动、复制、删除、重命名、追加文件。
不可以修改文件。
根据分析我们不难得出,HDFS的文件系统实际是通过NameNode控制的。
但HDFS数据流不通过NameNode,避免NameNode成为系统瓶颈。
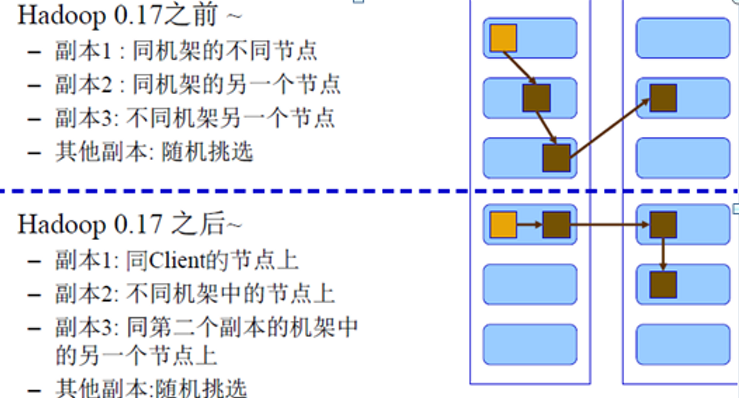
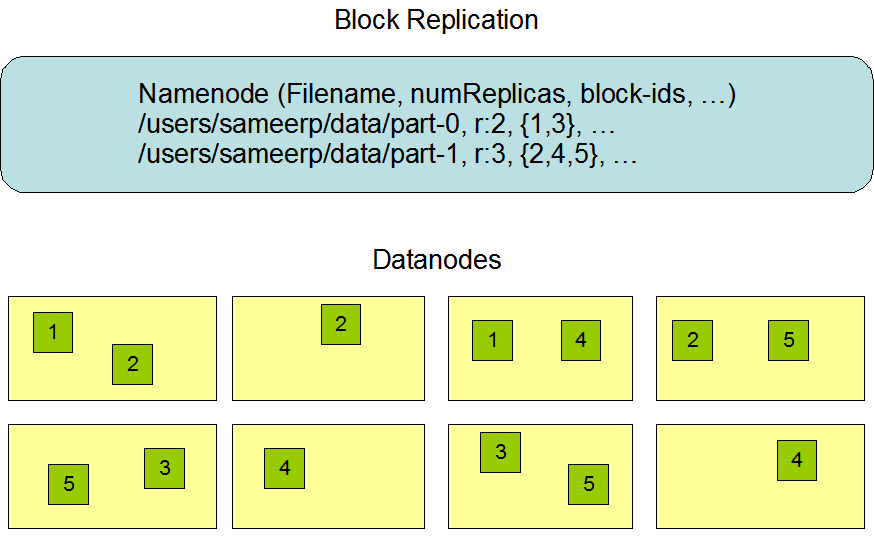
副本策略
HDFS为了容错,会对数据备份。一个文件的副本的数目称为该文件的复制因子。
HDFS用于解决大文件,因此会将大文件分割成小块,文件存储在NameNode上为块的序列,实际数据分散到各个DataNode上。
块大小和复制因子可以设置,复制因子在数据存储之后可以更改。
常见错误
常见三种错误情况:
- 文件损坏:CRC32校验、多副本
- 网络故障:HeartBeat、BlockReport
- 机器故障:FSImage(文件系统镜像),Editlog(操作日志)
复制策略
数据复制之前,NameNode会周期性接收心跳信号(Heartbeat)和块报告(Blockreport)。心跳信号表示DataNdoe正在运行,块报告包含DataNode节点块列表。
来自 hadoop.apache.org
对于常见的情况下,复制因子为三个,HDFS的放置策略是把第一个副本放在本地机架的一个节点,第二个副本放置在本地机架上的另外一个节点,第三个副本放置在另外一个机架的节点上。这种策略削减了机架间的写操作从而提高写入性能。机架故障几率比节点故障低的多; 这种策略不会影响数据的可靠性和可用性。
然而,它确实减少读取数据时的带宽,块数据只来自于两个机架而不不是三个机架。根据此策略,文件副本块不必均匀地分布在一个机架。副本块的三分之一在当前节点上,副本块的三分之一在同一机架上,另外三分之一是均匀分布在其余的机架。这一政策提高写入性能并且不会影响数据可靠性和读取性能。
这里注意Hadoop的副本实际上保存的是块的序列,并且序列上的块会有多个副本。
Hadoop副本在读取时会选取最优策略,就近选择节点和机架。
安全模式
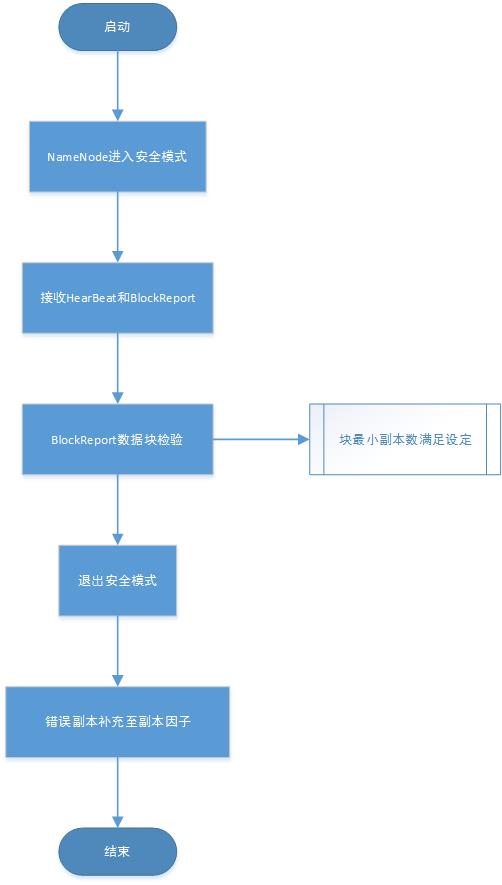
数据损坏
DataNode读取时,计算CheckSum。若CheckSum与NameNode不一致,则损坏。读取其他备份。并且对正确的备份再备份数量达到复制因子。
DataNode在其文件创建后三周校验CheckSum。