Hadoop配置文档(二)
这一篇是介绍Hadoop伪分布式的配置中的Hadoop的配置。第一部分是Hadoop1.0配置,第二部分是Hadoop2.0的配置,大家可以自己选择查看。
Linux配置可以查看 Hadoop学习笔记(三)Linux环境配置
Hadoop1.0配置介绍
Hadoop的五个核心守护进程有:NameNode,SecondaryNameNode,DataNode,JobTracker,TaskTracker
所以不难理解,Hadoop方面的配置主要是对五个核心守护进程的配置。
NameNode配置
cd $HADOOP_HOME/conf/
vim core-site.xml
配置文件如下
<configuration>
<!-- NameNode节点地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://HOSTADDRESS:9000</value>
</property>
<!-- NameNode缓存文件地址 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
</configuration>
注意缓存文件地址手动创建,可以自由配置
DataNode
cd $HADOOP_HOME/conf/
vim hdfs-site.xml
配置文件如下
<configuration>
<!-- HDFS副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 权限检查不启用 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
SecondaryNameNode
cd $HADOOP_HOME/conf/
vim masters
将localhost替换为$HOSTNAME
指定SecondaryNameNode位置
JobTracker
cd $HADOOP_HOME/conf/
vim mapred-site.xml
文件配置如下
<configuration>
<!-- 指定JobTracker主机号与端口号 -->
<property>
<name>mapred.jdo.tracker</name>
<value>HOSTADDRESS:9001</value>
</property>
</configuration>
TaskTracker
cd $HADOOP_HOME/conf/
vim slaves
将localhost替换为$HOSTNAME。
指定DataNode和TaskTracker的位置
编译环境
cd $HADOOP_HOME/conf/
vim hadoop-env.sh
启用JDK配置,并配置到对应的JDK位置
NameNode格式化
cd $HADOOP_HOME/bin/
hadoop namenode -format
测试
start-dfs.sh
jps
jps查看java虚拟机运行进程,成功则显示
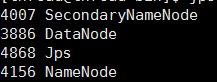
start-mapred.sh
jps
成功显示显示如下
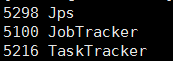
异常
若此时存在守护进程没有启动的情况,通常存在两种问题
- XML配置错误,XML文件修改过后,需要进行namenode formate
- 文件权限问题
文件权限问题需要对文件权限进行修改。
修改到的文件权限涉及到的目录主要有:
$HADOOP_HOME和TEMP目录,若存在相关问题可以更改文件权限解决
Hadoop2.0配置介绍
基本原理和第一篇相同,所以重复的内容就不浪费时间
core-site.xml
配置NameNode地址
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://thread.com:9000</value>
</property>
</configuration>
hdfs-site.xml
配置副本数
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
此处与Hadoop1.0不同,Hadoo2.0的资源调度交由yarn框架进行调度
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
yarn是资源调度框架,详细这边不多做介绍
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
NameNode格式化
cd $HADOOP_HOME/bin/
hadoop namenode -format
测试
start-all.sh
jps
jps查看java虚拟机运行进程,成功则显示
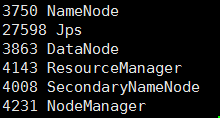
异常
若此时存在守护进程没有启动的情况,通常存在三种问题
- XML配置错误,XML文件修改过后,需要进行namenode formate
- 文件权限问题
- namenode在formate之后,datanode无法启动
文件权限问题需要对文件权限进行修改。
修改到的文件权限涉及到的目录主要有:
$HADOOP_HOME和TEMP目录,若存在相关问题可以更改文件权限解决
第三种情况,是由于datanode在创建后会保存namenode版本号,而namenode formate之后,版本号更新,datanode的版本号无法与最新namenode版本号进行匹配,需要手动更新
默认配置地址在/temp/hadoop-USERNAME/dfs/name/current/VERSION
以及/temp/hadoop-USERNAME/dfs/data/current/VERSION
nameVersion文件中
clusterID=CID-9d26b796-f8bd-41ec-a829-07b3c641ae9b
dataVersion文件中也存在clusterID,如果不匹配,则可以进行匹配
欢迎继续学习使用Hadoop Hadoop学习笔记(五)日志系统