深度学习引擎
目录
本文目的
高效的Inference框架
主流框架的问题
Training
TensorFlow,PyTorch
Inference
已有框架
TensorFlow等这样的框架孱弱,Intel的OpenVINO,ARM的ARM NN,NV的TensorRT
为什么复杂,以及问题
- 设备可能会是多种多样的,如Intel CPU / Intel GPU / ARM CPU / ARM GPU / NV GPU / FPGA / AI芯片
- 各大设备厂商的框架并不具备通用性,比如对训练框架模型产生的算子支持不全
- 在一个设备厂商的Inference框架能跑,但是不一定在另外一个设备厂商的Inference框架上能跑
- 如果换了硬件,没有统一的使用体验,算子支持也不一样,性能还不一定是最好的
历史类似问题
曾经出现了很多种编程语言,有很多种硬件,历史上最开始也是一种语言对应一种硬件,从而造成编译器的维护困难与爆炸
解决方案:
抽象出编译器前端,编译器中端,编译器后端等概念,引入IR (Intermediate Representation)
- 编译器前端:接收C / C++ / Fortran等不同语言,进行代码生成,吐出IR
- 编译器中端:接收IR,进行不同编译器后端可以共享的优化,如常量替换,死代码消除,循环优化等,吐出优化后的IR
- 编译器后端:接收优化后的IR,进行不同硬件的平台相关优化与硬件指令生成,吐出目标文件
类似这样的架构:

深度学习解决方案
- 引入一个新的编译器,负责把这些编程语言识别,吐出IR,称为Graph IR
- TVM (https://tvm.ai/).
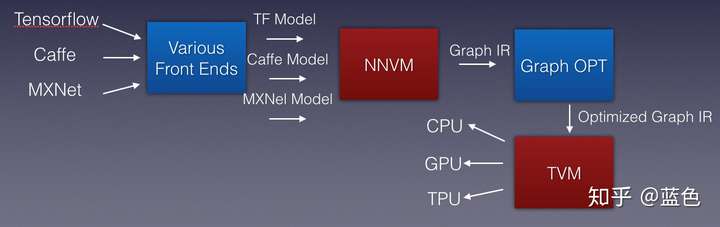
更详尽,更漂亮的一张图:
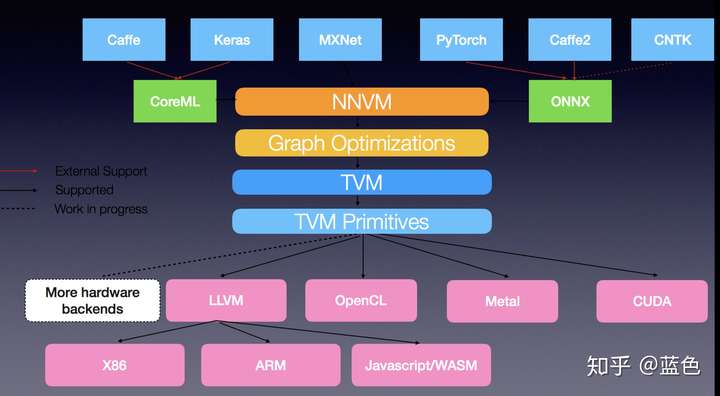
TVM
特点
- 基于编译优化思想的深度学习推理框架的完美体现
- AutoTVM(https://arxiv.org/pdf/1805.08166.pdf)机制
- [ARM][Performance] Improve ARM CPU depthwise convolution performance by FrozenGene · Pull Request #2345 · dmlc/tvm 将深度卷积的性能提高近2倍
- 最厉害的是具有非常强的适应性
- 采用了全栈编译器方法
- 结合了代码生成和自动程序优化功能,以生成可与经过大量手动优化的库相媲美的内核
- 在包括ARM CPU,Intel CPU,Mali GPU,NVIIDA GPU和AMD GPU在内的硬件平台上获得了最新的推理性能
- 允许手工提供微内核(micro kernel)用于优化4x4外积等
- 采用自动优化的办法优化内存排布和loop
- 用户可以通过构造特定的搜索空间模版来加入人工信息
竞争对手
- NCNN
- 对比:Automatic Kernel Optimization for Deep Learning on All Hardware Platforms
- XLA?
- TFLite这样的框架,即调用高效的GEMM加速库,
- 抑或着NCNN这样的框架,针对ARM CPU手写汇编
- TVM,GLOW,MLIR等,走编译优化来做深度学习推理引擎
TVM的IR
偏算子端的IR
Program -> Stmt Program | Null
Stmt -> RealizeStmt |
ProduceStmt |
ForStmt |
AttrStmt |
IfThenElseStmt |
ProvideStmt |
LetStmt
Expr
Realize -> realize TensorVar(RangeVar) {Program}
ProduceStmt -> produce TensorVar {Program}
ForStmt -> for (IterVar, Expr, Expr) {Program}
AttrStmt -> TensorVar Attribute {Program}
IfThenElseStmt -> if (Expr) then {Program} |
if (Expr) then {Program} else {Program}
ProvideStmt -> TensorVar(Params)=Expr
LetStmt -> let ScalarVar=Expr {Program}
Expr -> Const |
TensorVar |
ScalarVar |
IterVar |
RangeVar |
Binary |
Unary |
Call
偏计算图端的部分
是Relay(NNVM的后继),
Relay部分提供了DAG和A-Normal两种类型表达计算图的方式,
其中A-Normal是lambda表达式计算续体传递风格(CPS)的一种管理性源码规约,分别供偏好于深度学习和计算语言的人员使用,两者是基本等价的。
可以看到,TVM对于图部分的IR和算子部分的IR,有明显的分层
XLA的IR
- 为HLO IR,HLO为High Level Optimizer的缩写.这一层的IR主要描述的是设备无关优化,
- 而设备相关优化会借助LLVM后端来完成
HLO IR相比TVM IR最大的区别是:
- HLO IR中既表示DAG,又表示加减乘除这些细节的运算,以及相关的辅助功能,比如layout相关的reshape。
- TVM IR的分层标准是计算图和算子,而HLO IR的分层标准是设备无关和设备相关
eg代码优化
- Haswell架构支持的FMA指令
- 内存布局、并行、Blocking、更好的Cache命中率
- vectorize,即SIMD,
- 调整循环的顺序
- Array Packing,就是尽量让我们访问的数据在内存中是连续的
- Write Cache??
- AutoTVM:让AI来编译优化AI系统底层算子
- https://docs.tvm.ai/tutorials/autotvm/tune_simple_template.html#sphx-glr-tutorials-autotvm-tune-simple-template-py
- 量化压缩,图优化,子图分离,异构执行
- 算子融合
- Cache、Loop优化。Winograd, Spatial Pack, im2col,layout变换等
- 量化压缩
eg做深度学习推理引擎很适合做编译器、体系结构、HPC的人
Q:
NVPTX
nvcc
halide语言的
阿里最近开源的推理框架MNN
Gemfield
深度学习编译和传统编译的技术路线差别
| 传统编译器 | 深度学习编译器 | |
|---|---|---|
| 优化需求 | 传统编译器注重于优化寄存器使用和指令集匹配,其优化往往偏向于局部 | 深度学习编译器的优化往往需要涉及到全局的改写,包括之前提到的内存,算子融合等。目前深度学习框架的图优化或者高层优化(HLO)部分和传统编译的pass比较匹配,这些优化也会逐渐被标准的pass所替代。但是在高层还会有开放的问题,即高层的抽象如何可以做到容易分析又有足够的表达能力。TVM的Relay,XLA和Glow是三个在这个方向上的例子 |
| 自动代码生成 | 传统编译器的目标是生成比较优化的通用代码 | 深度学习编译器的目标是生成接近手写或者更加高效的特定代码(卷积,矩阵乘法等) |
| 解决的问题 |
方法
- 整数集分析和Polyhedral Model:核心思想是采用整数集来表示循环迭代的范围,利用整数集之间的关系来表示迭代变量之间的依赖,从而达到程序分析变换的目的
- 如何设计搜索空间:一般来说,这一搜索空间的定义需要大量吸收人工优化经验并且加以融入。具体的空间包括循环重排,映射部分计算到实际的加速器指令(张量化,tensorzation),流水线优化等。一般很难确定一个完整的解答
- 用机器学习优化机器学习:采用机器学习来自动优化算子。有兴趣的同学可以看 AutoTVM:让AI来编译优化AI系统底层算子