首先创建一个借口,用来表示耗费资源的计算
package cn.xf.cp.ch05; public interface Computable<A, V> { V compute(A arg) throws Exception; }
实现接口,实现计算过程
package cn.xf.cp.ch05; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.math.BigInteger; public class ExpensiveFunction implements Computable<String, BigInteger> { @Override public BigInteger compute(String arg) throws InterruptedException { //读取10个文件的和 BigInteger count = new BigInteger("0"); File file = null; InputStreamReader is = null; BufferedReader br = null; try { file = new File(String.valueOf(arg)); is = new InputStreamReader(new FileInputStream(file)); br = new BufferedReader(is); String line = ""; while((line = br.readLine()) != null) { String longdata[] = line.split(" "); for(int j = 0; j < longdata.length; ++j) { //统计和 String temp = longdata[j]; BigInteger bitemp = new BigInteger(temp); count = count.add(bitemp); } } } catch (Exception e) { e.printStackTrace(); } finally { try { br.close(); is.close(); } catch (IOException e) { e.printStackTrace(); } } //返回统计结果 return count; } @org.junit.Test public void test() { String s = "132456789123456789326549873218746132165432176134653216874649761"; BigInteger bi = new BigInteger("0"); System.out.println(bi.add(new BigInteger("1")).toString()); } }
功能实现1,这个不是现场安全的,就是一个简单的缓存机制,如果有就直接从缓存中获取,没有的话就添加到缓存中
package cn.xf.cp.ch05; import java.util.HashMap; import java.util.Map; public class Memoizer1<A, V> implements Computable<A, V> { /** * 这里使用hashmap来作为缓存对象,其实并不是一个好的选择,hashmap并不是一个线程安全的类 */ private final Map<A, V> cache = new HashMap<A, V>(); private final Computable<A, V> c; public Memoizer1(Computable<A, V> c) { //初始化C的值 this.c = c; } /** * 由于hashmap并不是一个线程安全的,所以我们队这个操作加锁,避免意外 * 但是如果有一个问题,如果一个线程阻塞了这个方法,那么其他线程就无法通过这个方法获取到对应的缓存 * 那么就可能会造成使用缓存的结果却比不使用缓存更慢,性能并不会得到任何的提升 * @param arg * @return * @throws InterruptedException */ @Override public synchronized V compute(A arg) throws Exception { V result = cache.get(arg); if(result == null) { result = c.compute(arg); //如果没有的话,那么就放到对应的缓存对象中 cache.put(arg, result); } return result; } }
功能实现2:添加一个future进行异步处理,就是把原来的数据计量分化到异步处理中,这样就不会产生阻塞在一个地方,造成其他线程等待很耗费资源的计算产生结果的问题
package cn.xf.cp.ch05; import java.util.Map; import java.util.concurrent.Callable; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.Future; import java.util.concurrent.FutureTask; public class Memoizer2<A, V> implements Computable<A, V> { private final Map<A, Future<V>> cache = new ConcurrentHashMap<A, Future<V>>(); private final Computable<A, V> c; public Memoizer2(Computable<A, V> c) { this.c = c; } /** * 这个里面的复合操作,没有就添加future,是在底层的MAP对象上执行的,而map无法通过加锁来确定原子性 */ @Override public V compute(final A arg) throws Exception { Future<V> f = cache.get(arg); if (f == null) { Callable<V> eval = new Callable<V>() { public V call() throws Exception { return c.compute(arg); } }; FutureTask<V> ft = new FutureTask<V>(eval); f = ft; cache.put(arg, ft); ft.run(); // call to c.compute happens here } return f.get(); } }
功能实现3:避免底层map的操作有影响,并防止缓存污染
package cn.xf.cp.ch05; import java.util.concurrent.Callable; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentMap; import java.util.concurrent.Future; import java.util.concurrent.FutureTask; public class Memoizer3<A, V> implements Computable<A, V> { private final ConcurrentMap<A, Future<V>> cache = new ConcurrentHashMap<A, Future<V>>(); private final Computable<A, V> c; public Memoizer3(Computable<A, V> c) { this.c = c; } @Override public V compute(final A arg) throws Exception { //不断循环,直到return while (true) { Future<V> f = cache.get(arg); if (f == null) { Callable<V> eval = new Callable<V>() { public V call() throws Exception { return c.compute(arg); } }; FutureTask<V> ft = new FutureTask<V>(eval); /* * 确定使用,这个避免重复添加 * 如果包含arg就返回,否则就把ft放入进去 */ f = cache.putIfAbsent(arg, ft); if (f == null) { f = ft; ft.run(); } } try { //返回计算结果 return f.get(); } catch (Exception e) { //计算失败,从缓存中移除,避免缓存污染,就是一个key返回一个空值,并返回从新运算 cache.remove(arg, f); } } } }
测试结果:
package cn.xf.cp.ch05; import java.math.BigInteger; public class MemeryTest { public static void main(String[] args) throws Exception { ExpensiveFunction ef = new ExpensiveFunction(); Memoizer1<String, BigInteger> m = new Memoizer1<String, BigInteger>(ef); BigInteger bresult1 = new BigInteger("0"); BigInteger bresult2 = new BigInteger("0"); //比较不同方式统计10次1文件的时间比较 long start1 = System.nanoTime(); for(int i = 1; i <= 10; ++i) { bresult1 = bresult1.add(ef.compute(String.valueOf(1))); } long end1 = System.nanoTime(); long start2 = System.nanoTime(); for(int i = 1; i <= 10; ++i) { bresult2 = bresult2.add(m.compute(String.valueOf(1))); } long end2 = System.nanoTime(); System.out.println("统计文件1~10使用时间" + (end1 - start1) + " 大小是:" + bresult1.toString()); System.out.println("统计文件1,10次使用时间" + (end2 - start2) + " 大小是:" + bresult2.toString()); } @org.junit.Test public void test2() throws Exception { ExpensiveFunction ef = new ExpensiveFunction(); Memoizer2<String, BigInteger> m = new Memoizer2<String, BigInteger>(ef); BigInteger bresult1 = new BigInteger("0"); BigInteger bresult2 = new BigInteger("0"); //比较不同方式统计10次1文件的时间比较 long start1 = System.nanoTime(); for(int i = 1; i <= 10; ++i) { bresult1 = bresult1.add(ef.compute(String.valueOf(1))); } long end1 = System.nanoTime(); long start2 = System.nanoTime(); for(int i = 1; i <= 10; ++i) { bresult2 = bresult2.add(m.compute(String.valueOf(1))); } long end2 = System.nanoTime(); System.out.println("统计文件1~10使用时间" + (end1 - start1) + " 大小是:" + bresult1.toString()); System.out.println("统计文件1,10次使用时间" + (end2 - start2) + " 大小是:" + bresult2.toString()); } @org.junit.Test public void test3() throws Exception { ExpensiveFunction ef = new ExpensiveFunction(); Memoizer3<String, BigInteger> m = new Memoizer3<String, BigInteger>(ef); BigInteger bresult1 = new BigInteger("0"); BigInteger bresult2 = new BigInteger("0"); //比较不同方式统计10次1文件的时间比较 long start1 = System.nanoTime(); for(int i = 1; i <= 10; ++i) { bresult1 = bresult1.add(ef.compute(String.valueOf(1))); } long end1 = System.nanoTime(); long start2 = System.nanoTime(); for(int i = 1; i <= 10; ++i) { bresult2 = bresult2.add(m.compute(String.valueOf(1))); } long end2 = System.nanoTime(); System.out.println("统计文件1~10使用时间" + (end1 - start1) + " 大小是:" + bresult1.toString()); System.out.println("统计文件1,10次使用时间" + (end2 - start2) + " 大小是:" + bresult2.toString()); } }
结果就是使用了缓存的话,速度会快10倍,这个决定于循环的次数
文件的话,就是简单的循环生成数据

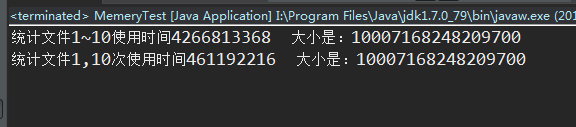
三种测试结果,差不多,因为这里并没有使用到多线程进行测试,结果和单线程是一样的。