reading-report-2-cww97
Research on Facebook and Social Graph
Weiwen Chen 10152510217
School of Computer Science and Software Engineering
East China Normal University
cww970329@qq.com
Abstract: As the biggest social network company in the world, Facebook has advanced and original technology on social graph computing and it is meaningful to do some research on its users. This paper has some study on unicorn which is created originally by Facebook and how Facebook compute the distance in social graph.
Keywords: Facebook, Social Graph, unicorn.
I. DISTANCE OF SOCIAL GRAPH
A. Distance Research In The Past
For a long time, scholars showed great interest on the distribution of social graph and it became a hot topic to find the difference between social graph and other complex graphs. The most famous one is Milgram’s series of experiments in the last century. These experiments have led to the famous “Six Degree Theory”. He selected 296 volunteers and asked them to send a message to one Boston Shareholders. This message cannot be sent directly to the target but must be sent to whom believe that they are most likely to know this shareholder will be forwarded again. Volunteers include 100 Boss residents, 100 Nebraska shareholders and 96 randomly selected Nebraska State residents.
The results of the experiment are very interesting, with Boston residents (about 4.4 middlemen) and within who are very significant differences between the two populations in Brasil (about 5.7 middlemen), but within who are no significant differences between the two populations in Las Ramblas. In all completed chains, the average middleman is about 5.2. Largest communication before Facebook’s research.
Figure study is a study of 180 million people and 1.3 billion edges in Microsoft’s message network snapshot. The average distance between people is 6.6, with an average of 5.5 middlemen. But Microsoft’s ditch plot studies are limited to the relationships of people who communicated in a given month, ignoring the particular ones. There is no communication between people in the month. Qi Ye did some research on small social networks.
In fact, the networks chosen in their research are all undirected small networks. The characteristics of these networks. According to the author, some interesting sampling methods were proposed but these methods are not very good. It is displayed on the directed graph of non-strong Unicom.
B. Facebook’s Research On Social Graph
The most striking difference between Facebook’s research and Milgram’s research is: Milgram studied the length of the routing path in the social network. It is the upper bound of the average distance because of volunteering.
The person does not necessarily give the message to the middleman who can get the shortest path, but Facebook’s study looked at the calibration of the shortest path. Unlike Microsoft’s research, Facebook’s “current” graph also only studied active users in May 2011, Facebook also explored. Some historical social networking diagrams of the past.
II. RESEARCH DETAILS ON SOCIAL NETWORK DISTANCE
A. Distance Algorithm
Since we must calculate the distance in the social network, we must calculate the so-called neighbor function which given a finite number of steps, t returns all node pairs (x, y) which satisfies y for x in t steps.
Facebook’s research uses the HyperANF algorithm to quickly estimate the neighbor function in large graphs and Web Graph to represent the shape of a compressed and quickly accessible graph Style. The central idea of HyperANF is to calculate the distance around each node from a distance of zero.
The radius range covers the node that is the “ball” of the node and gradually increases the radius to cover the entire map. Directly recording data for each round of storage requirements is too large, HyperANF uses Hyper Log meter recorder to record, each counter is composed of a small number of registers. The entire data flow is divided at random to different registers in averaging algorithm. In addition, HyperANF uses a shrinking way to avoid double counting “balls” that do not change.
B. Experimental Design
Facebook studied the entire Facebook map, the United States sub-map, the Italian sub-map, and the Swedish sub-map. The selection of subgraphs is not random. Researchers hope to study whether there are significant differences in social network distances in different regions by studying two geographically isolated subgraphs. After selecting the subgraph, the researchers compressed the Facebook sub map, which was converted to the previously mentioned Web Graph.
After the conversion, multiple scans will become faster. This requires converting the ID in Facebook to a more continuous number, and the compressed Facebook graph takes up approximately 86% of the theoretical lower bound. The compression process using the BV compression method is specifically three kinds of successor nodes to process a node: if the similarity degree of the successor node table is sufficient, the previous node is duplicated in a small window as a successor node; if there is a clear continuous successor sequence, the successor node is The left limit and length are used instead; if the successor sequence crosses the previous sequence, the difference between consecutive successors is used instead of the successor table entry.
In this case, a graph will have a better compression effect when it has a higher degree of similarity and a better locality: the process of renumbering is likely to increase the continuity, plus one person in real life Social networking time is usually almost the same as several friends. In addition, the LLP can also steadily increase the locality of the graph. LLP combines clusters of different granularity to increase locality and similarity. However, this method requires high computational requirements. For the Facebook network, this large-scale graph needs It takes ten days to complete. The combination of LLP and BV compression is currently the best compression method for social networks, and the final compression rate is about 53%. After the data processing is completed, during the running process, because the size of the graph is too large, in order to avoid excessive I/O operations, the “ball” of each node is stored in memory conveniently for radius r-1 and r.
C. Result Analysis
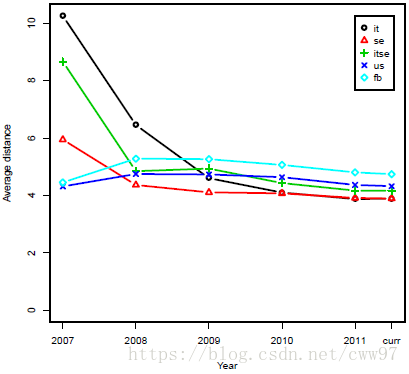
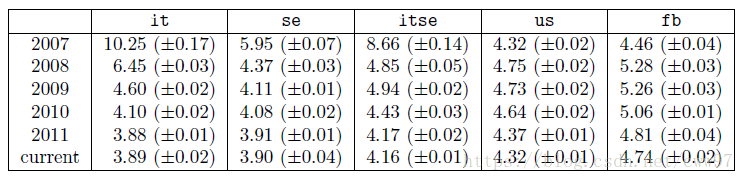
As shown in the figure, in September 2006, Facebook opened its registration for non-university students. So at the beginning of 2007, the distance between the Italian and Swedish subgraphs was very high, the connectivity of the entire network was very low, and then quickly decreased. This basically belongs to Facebook’s relative backwardness in the rise of these two countries, so the results of network expansion were relatively late. In the following years, the connectivity of several subgraphs becomes closer and more balanced. There is no mention in the paper but it is interesting to note that the distance between the US subgraph and the initial general map is rising first and then decreasing. At first glance, it seems a little strange because the distribution of users of ordinary products should actually be represented by the subgraphs of Italy and Sweden. The same is sparsely densified. However, it is not difficult to understand this phenomenon in combination with the history of Facebook itself. In the early days of Facebook, it was a social network for US campuses. Therefore, the user community is actually very concentrated. The social network distance among student groups is actually relative to the society as a whole. Lower, and these users are the main force of the entire early Facebook users, so the similarity of the US sub-map after the social registration for the user group is diluted, and then as the user registration volume rises and continues to decline steadily. As for the entire Facebook map, it is actually the early users who are mostly in the United States and therefore show a high degree of similarity with the US sub-map. After that, the similarities are diluted as users from all over the world join.
At the time of the fastest growth of Facebook, the decay of the average distance is also very fast. Over time, as more and more active users have joined the network, the distance attenuation will be slow. This is consistent with the “shrinking diameter” effect mentioned in the article: In the course of a large map that was initially discovered and evolving, the effective diameter is actually attenuated. The characteristics of the Facebook network now also show that it is increasingly close to the global social network, but there is still a certain gap is still growing. In addition, as shown in the above table, the distances in the subgraphs of Italy and Sweden are significantly lower but the values are similar, showing that the correlation between the average distance and the geographic distance of the user is greater than the correlation with the size of the network.
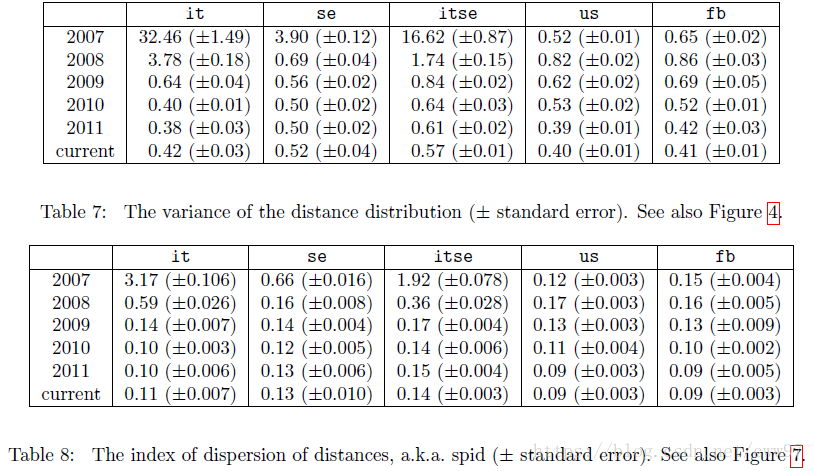
As for the spid, the dispersive index of the distance distribution, the social network is closer to the Internet distribution when spid is greater than 1, and less than 1 is called so-called moderate social. The main feature of so-called moderate social networking is that very long links in the web network are more common but social networks are heavily biased towards short links. As shown in the above figure, it is surprising that the Facebook study found that, in general, the average distance and spid are almost irrelevant, and the apparent correlation is actually the correlation between the average distance and the variance.
In this study, the value of spid was 0.09, which is a very social network. Finally, regarding the diameter, it was mentioned earlier that HyperANF cannot accurately calculate the diameter. Calculating the diameter directly is also a very tricky task: For a matrix-based algorithm, a huge map has great difficulty in storage, and for a breadth-based approach The algorithm for prioritizing searches can be very time-consuming when the graph is very large. Facebook implemented a highly parallel version of iFUB to directly calculate the diameter to solve this problem and calculate the diameter of the undirected graph. The general idea is as follows:
For a node x, find the node y farthest from x and look for z that is farthest from y, then the distance between y and z is the lower bound of the diameter. In particular, this distance is the diameter of the graph when this graph is a tree. At any point between y and z c, note the farthest distance h from distance c, then 2h is the upper boundary of the diameter. When the upper bound is lower than the lower bound, the process ends. Otherwise, the node whose distance is distance c is exactly the node of h is the boundary node. Let M be the farthest distance of the node on the boundary, and max{2(h-1), M} is the new The upper bound and M are the new lower bounds. This iterative boundary node will eventually converge to the upper and lower bounds. The implementation of Facebook is multi-core BFS. The queue of nodes with distance d is divided into small pieces and calculated for different kernels. After the current round, the sequence of d+1 distances has been calculated. This method is still very fast. The diameter of the US sub-diagram can be calculated in 20 minutes. Facebook’s total map needs ten hours of calculation time, which is still very efficient.
III. UNICORN PROFILE AND FEATURES

In order to quickly search for basic structured information in social graphs and perform complex set operations on results, Facebook developed Unicorn, an online memory social graph indexing system that searches trillions of edges and billions of users and entities. Unicorn’s standards-based information retrieval concept has similarities with traditional retrieval systems, but since it has its own unique perspective at the beginning of its establishment, it has significant differences in the ways and perspectives of supporting social graph retrieval. In addition, there is no online graph indexing system in Unicorn that can reach a scale with Unicorn in terms of data volume and query capacity.
Facebook stores the relationship between people and things in a database as social graphs: people and things are nodes and relations are edges. Some sides are directional and others are symmetric. As shown in the above table, mutual friend is a kind of stacked relationship, and like is a one-way relationship. It is well understood that social graphs are sparse, so it is well understood that social graphs are represented as a series of adjacency lists. Unicorn is an inverted indexing service implemented as an adjacency table service. Each adjacency table contains an ordered list of labels and information. The index is an integer. Clicks are first sorted by index and then by label in ascending order. Therefore, labels with greater influence in the world will be in the front of the adjacency list. If a label id has an association with an index in an adjacency table, then it has a correspondence with this id in all adjacency lists. In traditional full-text search systems, the so-called Hitdata is the location information of matching files, but it is different in Unicorn. Hitdata does not appear in all entries, because some of the data corresponding to ids is stored separately in some data structures. Sometimes HitData is used to store some extra information for filtering results. For example: a list of all users who graduated from a university, and Hitdata can represent these people’s majors and graduation years. Unicorn splits the query output according to the result file. This is not without reason. Segmentation based on results helps the system still have availability in the event of crashes or network problems. Returning partial results during query is better than completely ineffective. In addition, segmentation based on results ensures that most collection operations can be completed at the bottom of the index server without crossing the higher level in the run stack, so that the computational burden can be distributed to more machines. Bandwidth requirements will also decrease. When a user makes a query, the query request is assigned to the nearest available Unicorn cluster from the user. The query request consists of a series of operators that describe the collection operations that the client needs. After the query is completed, sometimes the result is in the order of the file label. More often than not, the result is more preferences based on the number of matches based on the number of matches.
IV. UNICORN IMPLEMENTATION DETAILS
A. Structure
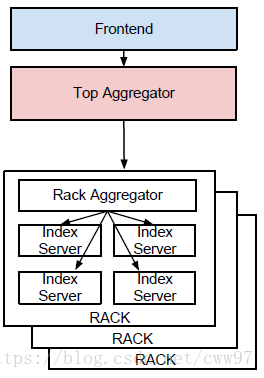
As shown in the figure, the client’s query request is first sent to the top-level aggregation server, then to the aggregation servers of each track, and finally to the index server according to the track where each index server is located. Then the aggregation server is responsible for combining and reducing the partitioned The result in different index fragments, finally the top aggregator returns the result to the user. The track aggregator is used to resolve the available bandwidth in the track that is greater than the available bandwidth between the tracks. Of course, peer servers will increase throughput and redundancy through mirroring. Each track aggregation server is part of the image of the peer server. When a fragment is unavailable, it will send a message to another image request to continue to distribute the request.
The index processor stores adjacency lists and performs collective operations on these lists, such as common operations such as cross, merge, and difference. Each index fragment often contains billions of entries, but the total number of different user entries in the entire system is approximately 10 billion. Although the total number of entries is larger than the common full-text search system, the posting list is relatively short—the 50-digit length is 3, and the 99-digit total is 59. In Unicorn, inverted indexing is a combination of different index forms to optimize decoding efficiency and storage access. The update is first applied to a layer of index that can be changed. This index is built on a layer of unchangeable index. The unchangeable index layer implements the update as an increase or decrease of the posting list. After the indexing is based on the Hadoop framework, the raw data is obtained from the scrape of the database containing the columns of the relevant data tables, and the access to scrape is based on Hive.
B. Figure Search
In the process of completing the graph search, sometimes useful results and the distance between the source node is more than one edge, which requires supporting more than one round of query between the top aggregate server and the index server. Because the entry itself is a combination of id and edge type, Unicorn uses the pre-defined model in the implementation to perform the next round of search in the result of the combination. So in addition to some basic operations, Unicorn has some unique operations
1. Apply

Apply allows the user to query some ids and use the result set to construct new queries. The query first finds the inner result and then the outer search needs to properly take the inner result. The Apply operation has many advantages. First, because additional lookups are performed within the Unicorn cluster using high-performance languages, the network latency is reduced by allowing complex operations to be limited to lower-level servers throughout the system. Second, the client code is simplified because the user does not need to deal with the cumbersome aggregation of different query rounds and the entry generation code. Take the example of a friend who is looking for a friend: The top-level aggregation server first sends the internal query to all user tracks. When it collects all the internal query results, it creates an external query on the internal query result set. When it collects the external query, As a result, the results are rearranged and shrunk as necessary and returned to the client. In the amount of Facebook users, if you look up the list of friends directly for each user and then find friends of friends, you will need too much space, this time the characteristics of the Apply operation can save a lot of space and become a necessary requirement.
2. Extract

Sometimes the query problem involves a one-to-many mapping, such as finding people tagged in a person’s photo. This is a good idea to store the secondary vertical result id in the positive index and continue to search directly. : The id of the person tagged in a photo is stored in the relevant index data of the photo in all photos. Extract is used to extract the required id from the positive row index. Extract is not part of the score, so that you can keep it simple. The disadvantage of this implementation is that the same result may be returned to multiple fragments, aggravating the work of the top aggregation server.
3. WeakAnd
This is an operator derived from And, which allows some of the results to be missed in the index fragmentation. The user determines the optional count or optional weight to specify that the entry can omit a certain amount or a proportion of the result. If optional count is not 0, the entry is not required to have a specific hit, and then the index server reduces the optional count for hits that do not have a match. When the optional count is 0, the entry becomes mandatory and must be included in the entry to the result set.
4. StrongOr
This is an operator derived from Or that requires certain actions to appear in a certain percentage of matching results. StrongOr’s involvement in diversity like the result set makes sense. For example, if you want to find Jon Jone’s friends in Beijing, San Francisco, and Palo Alto, the following statement can force at least 20% of the results in Beijing, 20 % of San Francisco results, 10% of Palo Alto results, and others are people anywhere.

5. Search Completion
Using the above-mentioned operators, Facebook implements an important application of graph search: search completion. When looking for relevance, the WeakAnd operation can achieve interesting results in some of the results, but not all results must include them. StrongOr guarantees diversity. When the results are returned, they will need to be ranked in a different order than DocId.
Unicorn provides a regular index to associate the id with the blob containing the relevant metadata. The user can select a scoring function to score each DocId and then sort. The highest scored result is given by the aggregator higher priority, but the sort is also Not completely based on the score because this may be the result of the loss of WeakAnd and StrongOr. When searching for different types of entities such as pages, activities, and applications, in order to support different types of entity searches while limiting the system’s mass, Unicorn is classified as vertical according to the entity type, and the top-level aggregation server also looks up the aggregation results according to a variety of vertical. The same type of edges are in the same vertical, so basic operations like And and Or can be performed only on the index server, and the id will exist as long as the id and merge operations are not performed. In addition, splitting the architecture into different verticals allows each team to optimize vertical sorting for this type of data. The top-level aggregation server distributes the query from the front-end to the relevant vertical, and some verticals can also be masked based on user requirements.
V. SUMMARY
Facebook’s research on social network distances and social graphs has been very innovative based on the characteristics of the Facebook network, revealing significant changes in the distance of modern social networks, and adding a lot of interesting features to social graph searches. Made a very creative contribution to social networking research.
// I am pretty sleepy now. TAT
VI. REFERENCES
- Jure Leskovec, Jon Kleinberg, Christos Faloutsos: Graphs over Time: Densification Laws, Shrinking Diameters and Possible Explanations, Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, 2005
- Michael Curtiss etc.: Unicorn: A System for Searching the Social Graph, VLDB, 2013
- Lars Backstrom etc.: Four Degrees of Separation, WebSci, 2010.