根据mysql内数据,python建倒排索引,再导回mysql内。
先把mysql内的数据导出,先导出为csv文件,因为有中文,直接打开csv文件会乱码,再直接改文件的后缀为txt,这样打开时不会是乱码,在第一行输入列名

保存时选另存为,将编码格式改为utf-8
这是建倒排索引时的代码(sort列没有空格和逗号) 运行是会报一个warning,但是结果没问题,代码结合了网络搜索结果,和我自己的修改,引用自:
https://blog.csdn.net/luoganttcc/article/details/89843699
https://github.com/luogantt/recommend_sys/blob/master/Inverted_index/invert_indexx.py 多谢分享!
from pprint import pprint
import pandas as pd
df = pd.read_csv("C:/Users/caiweiwen/Desktop/index_poem_dynasty.txt")
df['id'] = ' '
df['dynasty'] = ' '
all_dynasty = dict()
for i in range(len(df['poemid'])):
df['id'][i] = str(df['poemid'][i])
df['dynasty'][i] = "".join(str(df['dyn'][i]).split("朝代:"))
all_dynasty[df['dynasty'][i]] = 1
for dyn in all_dynasty.keys():
temp = []
for i in range(len(df['id'])):
if dyn == df['dynasty'][i]:
temp.append(df['id'][i])
all_dynasty[dyn] = temp
pprint(all_dynasty)
for sort in all_dynasty.keys():
with open('index_poem_dynasty.csv', 'a+', encoding='utf-8-sig') as f:
f.write(sort + ':'+','.join(all_dynasty[sort])+' ')
还有更复杂一点的诗歌标签的倒排索引:
from pprint import pprint
import pandas as pd
docu_set = dict()
df = pd.read_csv("C:/Users/caiweiwen/Desktop/index_poem_sort.txt")
key = ""
value = ""
for i in range(42440): #数据问题,之后的数据id和sort之间会换行
key = str(df['poemid'][i])
value = str(df['sort'][i]).split( ) #去掉每个sort里的空格,返回列表
docu_set[key]=value
print(key)
print(value)
tmp = []
for i in range(42439,len(df['poemid'])):
if(df['poemid'][i].isdigit()): #判断是否为数字,是则为id
key = df['poemid'][i]
docu_set[key] = tmp
else:
tmp.append("".join(str(df['poemid'][i]).split())) #先去掉sort里的空格,因为返回的列表项是列表,列表项应为string,所以又转为string
if(df['poemid'][i+1].isdigit()): #判断下一行是否为数字
docu_set[key] = tmp
print("key:" + key)
print("value:" + str(tmp))
tmp = []
pprint(docu_set) #输出字典
all_words = dict()
for i in docu_set.values():
for j in i:
all_words[j] = 1
print(all_words.keys())
invert_index = dict()
for b in all_words.keys():
temp = []
for j in docu_set.keys():
if b in docu_set[j]:
temp.append(j)
invert_index[str(b)] = temp
pprint(invert_index)
for sort in invert_index.keys():
with open('index_poem_sort.csv', 'a+', encoding='utf-8-sig') as f:
f.write(sort + ':'+','.join(invert_index[sort])+' ')
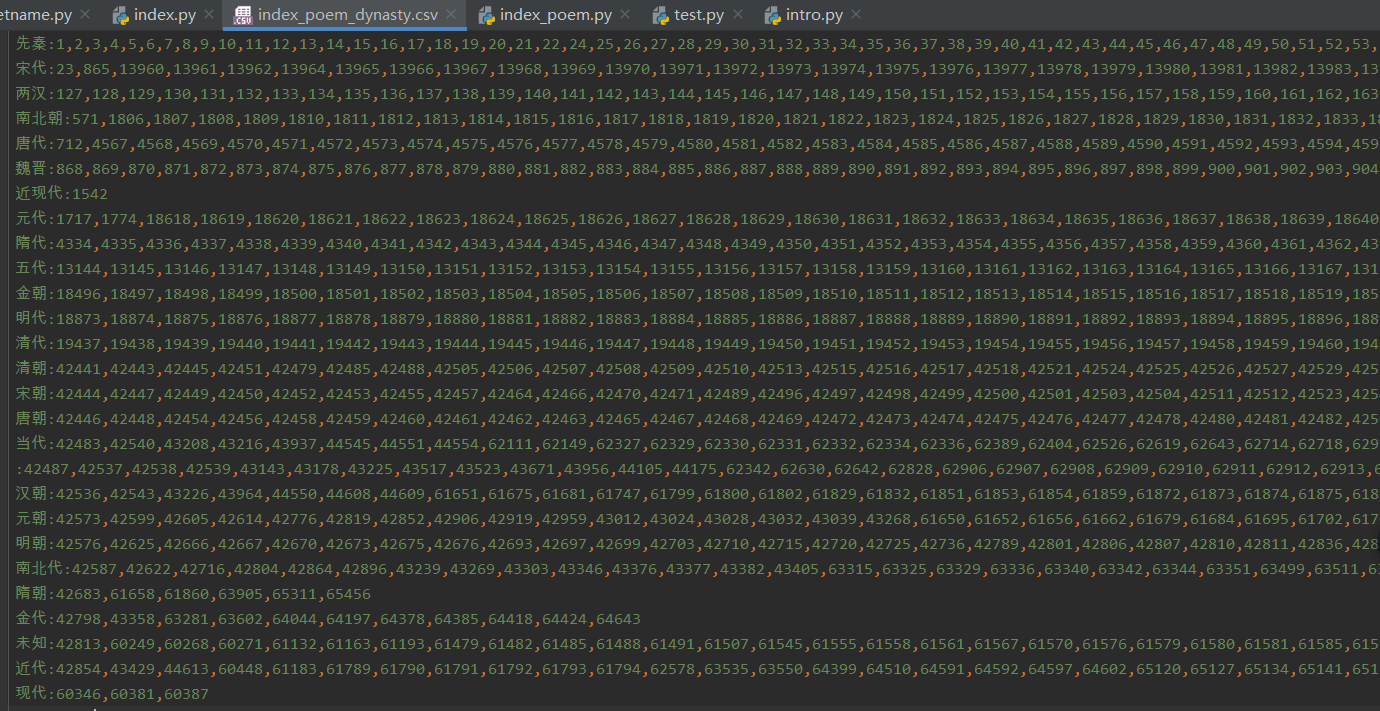
倒排结果:
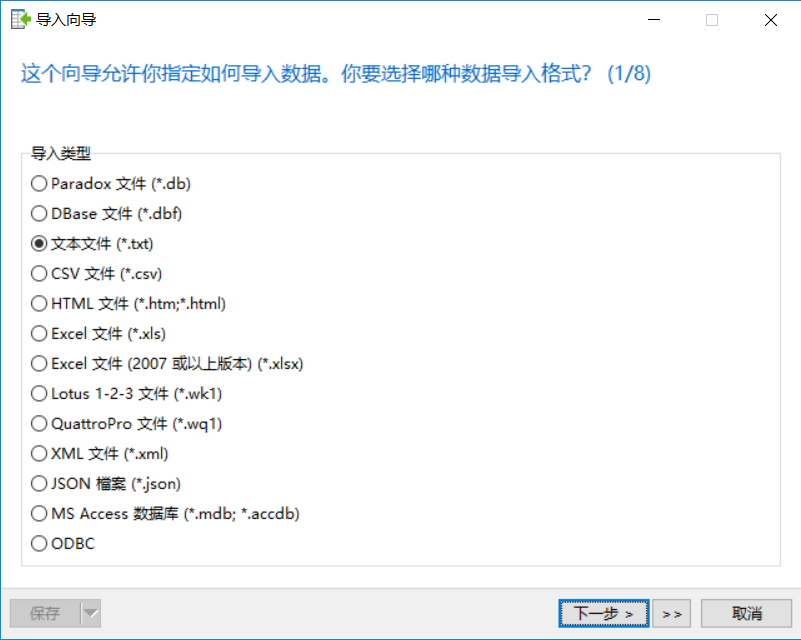
导入时选择txt文件的形式
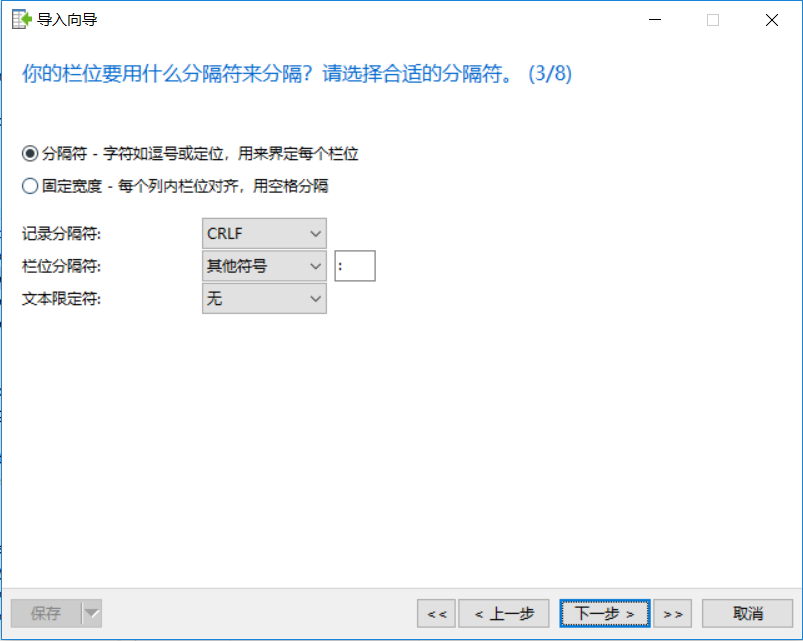
栏位分隔符我选择其他符号,我用冒号“ :”,视自己的具体情况而定,这样选源栏位和目标栏位时就很清晰了

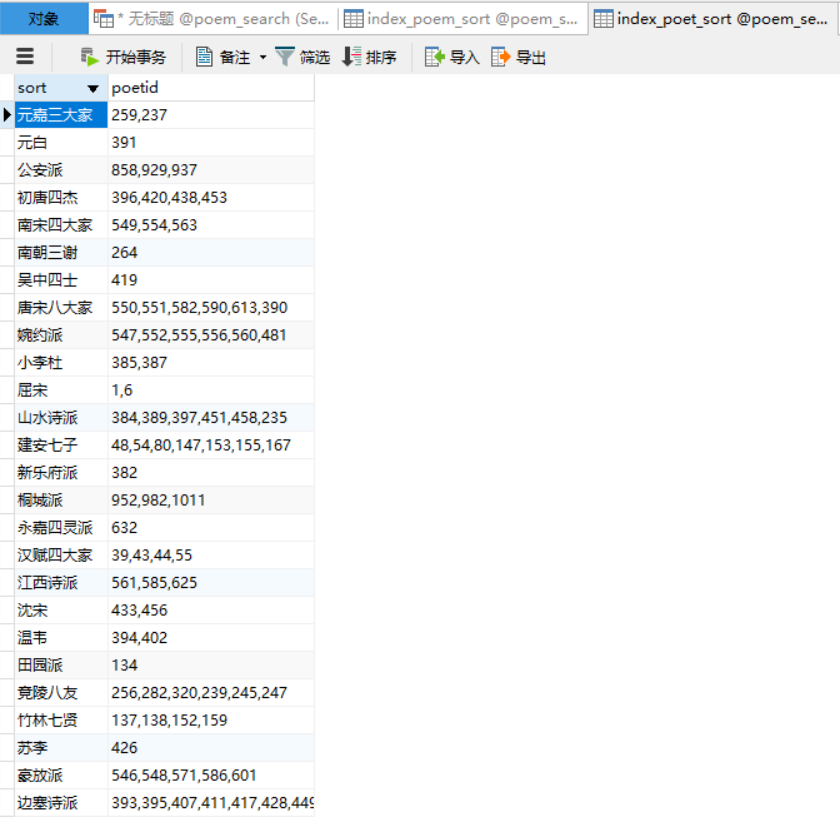
最后的成果:
总结:
刚开始还是走了很多弯路,用dataframe和它自带的建索引,结果不知道怎么用,还是上网搜了倒排索引的python代码后才知道该用什么数据类型,幸好看到的第一个就是对的哈哈哈,
以前第一次做android的时候就花了很多时间查百度都没对,问了大佬才知道要先系统地学习一遍。以后不知道怎么写的时候还是直接搜要做的内容吧,按自己的想法搜数据结构或者算法要
花很多时间。