案例教学,把“问题”讲清楚了,赞
Pony.ai 在多传感器感知上积累了很多的经验,尤其是今年年初在卡车上开始了新的尝试。我们有不同的传感器配置,以及不同的场景,对多传感器融合的一些新的挑战,有了更深刻的认识,今天把这些经验,总结一下,分享给大家,与大家一起讨论。

本次分享分为三部分:
- 为什么需要多传感器融合?
- 传感器融合的一些先决条件
- 如何做传感器融合?
▌为什么需要多传感器融合?
首先,单一传感器在自动驾驶中,都有各自的挑战,所以先了解下常用的传感器的挑战是什么:
1. Camera data

照相机数据遇到的挑战:
① 没有深度信息。
② 视场角有限,以卡车的传感器配置来说,需要比较多的摄像头,这里用到了6个摄像头覆盖了270°的视场角。
③ 摄像头受外界条件的影响也比较大,(上图右下方)这是当车行驶到桥下时,由于背光,且光线变化比较大,导致无法识别正前方的交通灯。
2. Lidar data
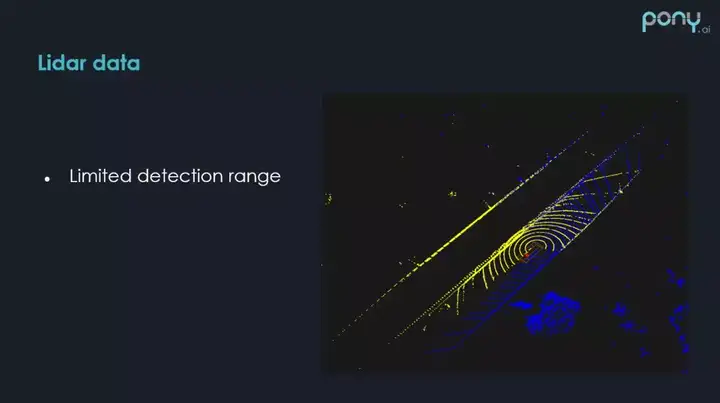
激光雷达数据的一个比较大的挑战是感知范围比较近,如右图所示,感知范围平均在 150m 左右,这取决于环境和障碍物的不同。
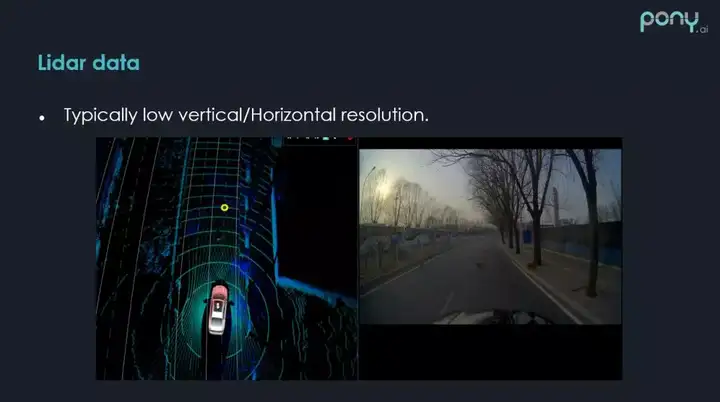
激光雷达在角分辨度上远远不如照相机,如上图,有三条小狗在过马路,在照相机上可以清楚的看到,但是在激光雷达上,采集到的点是比较少的,这样的场景在每天复杂道路路测的时候会经常遇到。

激光雷达对环境的敏感度也是比较大的,上图为 Pony 路测的时候经常遇到的虚拟噪点的 Case,在车经过建筑工地的时候,在图像上可以看到并没有任何的障碍物,但是在雷达上前面有很多的噪点,右边是雨天中的测试,车辆行驶中溅起来的水花,在激光雷达上都是有噪点的,如何去除这样的噪点,是我们经常面临的挑战。
3. Radar data

毫米波雷达,本身的一个挑战是没有高度信息,毫米波雷达能告诉你这个物体在哪个位置,但是不知道多高,这个 case 就是前面有一个比较高的指路牌,毫米波雷达知道这儿有个障碍物,但是不知道是悬空的。
4. Why sensor fusion

当看过了这些单一传感器在自动驾驶中面临的挑战,自然会想到,做多传感器融合,进行传感器之间的取长补短,来帮助整个感知系统效果的提升。这里的例子是,如何利用多传感器来提升感知的探测距离,当障碍物距离 150m 左右时,激光雷达的反射点已经比较少了,但是这时毫米波雷达和照相机还是比较稳定的。

当障碍物驶出 200m 的范围,基本上没有任何的激光雷达反射点了,但是 200m 取决于自动驾驶车辆本身的车速是多少,200m 的感知距离还是必要的,这时只能通过毫米波雷达和摄像头,来提升对障碍物的感知距离,从图中可以看到障碍物还是可以稳定识别出来的。
▌传感器融合的先决条件
1. 运动补偿 & 时间同步
① Ego motion
为什么做运动补偿?在自动驾驶传感器感知过程中,传感器采集数据,一般都不是瞬时发生的,以激光雷达为例,采集一圈数据需要 0.1s,在这 0.1s 内,本身车会发生一定的位移,障碍物也会发生一定的位移,如果我们不考虑这样的位移的话,我们检测出来的位置就会不准确。
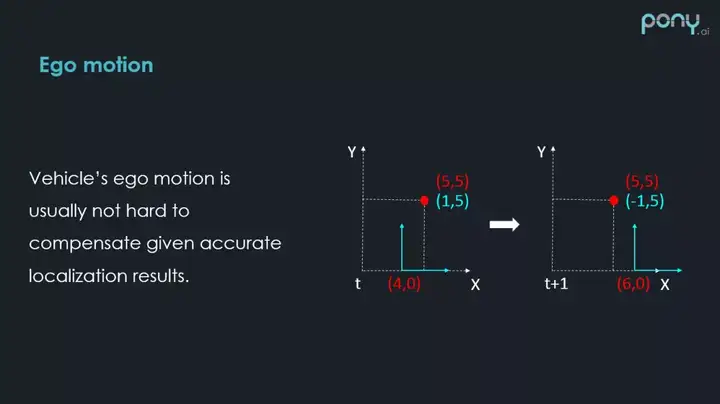
位移有俩种,第一种就是车自身的位移 Ego motion。右边画了一个示意图,虚线部分可以认为是世界坐标系,红色的点代表一个静态的障碍物,它在坐标系中有一个稳定的坐标(5,5),蓝色部分代表车自己的坐标系是局部坐标系,(4,0)为这个坐标系的原点,在 t+1 时刻,这个坐标系移动到了(6,0)的位置,车沿着 X 方向向前移动了2,在 t 时刻在车自身的坐标系下,障碍物的坐标是(1,5),在 t+1 是时刻,则是(-1,5)。如果不做车自身运动的补偿,静止的物体在2帧之间,测量的局部坐标是不一样的,就会产生错误的速度,因此,要去补偿车本身的位移,做自身的 Motion compensation 运动补偿。这个问题比较简单,因为车是有比较准确的定位信息的,它会提供这俩个时刻,车本身的姿态差距,我们可以利用姿态差,比较容易的补偿车移动了多少,那我们就可以知道这个障碍物其实是没有移动的。
② Motion from others

第二种要考虑的是运动物体在传感器采集的时间段内,运动物体发生的位移,相对于自身运动补偿,这是一个更难的 case,首先快速移动的物体,在激光点云里很可能会被扫到俩次,大家可以看下红圈内,尾部会有拖影。所以我们如何想办法消除对方车的 Motion,也是要考虑的。解决的方式有很多,现在激光雷达本身从硬件上也会有些配置,来缓解这样的现象,简单解释下,当你用多个激光雷达在自动驾驶车辆时,可以让激光雷达按照同样的方式一起转,在某一个特定的时段,特定的方向,应该扫到同样的东西,这样来减少快速移动的物体产生拖影这样的问题。
③ 时间同步
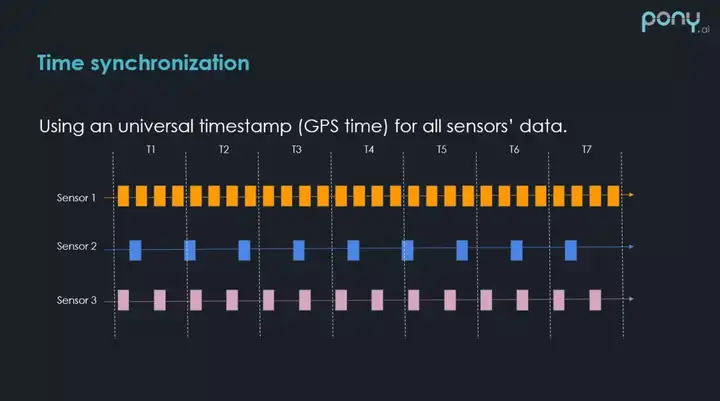
在很多自动驾驶车辆传感器中,大部分支持 GPS 时间戳的时间同步方法。这个方法比较简单,如果传感器硬件支持这些时间同步的方法,拿到传感器数据的时候,数据包中就会有全局的时间戳,这样的时间戳以 GPS 为基准,非常方便。但是,时间戳查询数据会有一个比较明显的问题,举个例子,图中有三个数据,三个传感器和时间轴,不同传感器是以不同频率来采集数据的,以传感器2为例,在 T1 时刻,传感器2有一个数据,在这个时刻,想知道对应的传感器1和传感器3的数据是多少,肯定需要去查找,查找的方式是找对应的传感器数据和传感器2时间差最近的数据包,然后拿过来用,这就取决于查的时候,数据包的时间和 T1 时刻传感器2数据包的时间到底差多少,如果差距比较大,本身障碍物都是在移动的,这样误差会比较大。

然后就有了第二种时间同步的方法,来缓解刚刚说的这种现象。就是主动数据同步的方法,比如以激光雷达作为触发其它传感器的源头,当激光雷达转到某个角度时,触发那个角度的摄像头,这样就可以大大减少时间差的问题,如果把这套时间方案做到硬件中,做到比较低的误差,那么对齐的效果比较好。如上图所示,这时激光雷达的数据就很好的和摄像头的数据结合在了一起。

刚才说到如果一个自动驾驶车辆用了多个激光雷达,激光雷达之间如何同步,减少扫到同样车在不同时间这样的问题,velodyne 是我们常用的一个品牌,支持一种 Phase Lock 功能,能够保证在某一时刻,所有的激光雷达的角度,都可以根据 Phase Lock 的配置,在固定的角度附近。这样如果用俩个前向的激光雷达都设置一个角度,在同一时刻,扫到的东西应该是类似的,这样一个快速行驶的车,被扫到2次的概率就会减少,当然这个办法也不能完全解决问题,比如有个人和我们的激光雷达以同样的频率一起转,那么在激光雷达扫描的点云中,人一直会出现,所以还要通过软件的方法,设置的一些规则或者模型来想办法剔除。
2. 传感器标定
接下来是另外一个比较大的话题:Sensor Calibration 传感器标定。这里主要是指传感器外参的标定。

传感器外参其实就是刚体旋转,因为物体上的俩个点,在经过旋转和平移之后,两个点之间的 3D 位置是不会变的,所以叫刚体旋转,在自动驾驶和机器人上,刚体旋转还是比较常见的。传感器外参的标定就是要找到这样的一个刚体旋转,可以把一个传感器的数据和另一个对齐。相当于把一个传感器测量的数据从其本身的坐标系,通过刚体旋转,转到另一个传感器坐标系,这样就可以进行数据融合了。上图中,左边为图像,中间为雷达,如果有一个比较好的外参工具,可以把 3D 的点投射到 2D 图像上,所有的障碍物的点都可以对应上,相当于把 2D 上的像素都加上了深度的估计。这样在图像质量并不是很高的情况下,可以通过这样的方式把信息补回来。
传感器的标定一般有俩种思路,第一种是有激光雷达的传感器标定,第二种是无激光雷达的传感器标定,之所以这么分,是因为激光雷达采集的数据是完整的 3D 信息,空间中的 ( x,y,z ) 都是准确的,并不会有信息的丢失,而照相机得到的数据,可以认为是极坐标系下的坐标,没有深度和角度,而毫米波雷达是没有高度的。所以,如果有这样的传感器能够提供完全的 ( x,y,z ) 坐标,以此为参照物,其他传感器和激光雷达做绑定的话,会更容易和更准确。Pony 是有激光雷达的,所以今天主要讲有激光雷达的传感器标定方法。
① Multi-Lidar Calibration

首先讲下多激光雷达是如何标定的,上图可以看到正好用到的是两个前向激光雷达,这两个激光雷达在前向180°是有比较大的覆盖区域,如果对激光雷达之间的旋转和平移没有比较好的估计,当把俩张激光雷达的点云放在一起进行感知处理的时候,在红框位置会发现存在比较大的分隔(黄线和蓝线分别代表俩个前向激光雷达),这种情况肯定是不想遇到的,所以需要把多个激光雷达做比较准确的标定。

标定的方法是已知的,非常好解决的问题,因为激光雷达本身是有完全的3D信息,解决这样俩个数据集匹配的问题,就是 ICP(Iterative Closest Point)迭代式最近点方法。这个方法有很多的变种,感兴趣的同学可以百度或者 Google 搜索下。
② Camera Lidar Calibration

另外一个就是照相机和激光雷达之间的标定。照相机本身是没有距离信息的,那么如何去做标定?同样激光雷达是有 3D 信息的,可以通过标定的方式,把激光雷达投到图像的坐标系中,建立图像的像素点,和激光雷达投影后的点之间的匹配,然后通过某种优化方程,来解决这样一个匹配问题。举一个简单的例子,比如现在要选取一系列激光雷达检测出来的候选点,如何选这些点呢?这些点一定是在图像上比较容易能够识别出来的边界点。选取方法也比较简单,因为激光雷达有距离信息,只需要找相邻俩个激光点之间的距离差,就可以判断这样一个点是不是边界点,我们可以轻易的选出这样的候选点,通过这样的投影方式,红框是我们要求的标定参数,K 矩阵为相机本身的内参,通过这个数学关系,我们可以把刚才 3D 中检测的候选点,投到 2D 上,上图中的 X 就是投射后的位置。我们可以根据 3D 投影点和 2D 检测的边界,进行匹配,然后根据他们之间的距离匹配程度,建立这样一个优化方程,然后解这样一个优化问题,来估计出 Calibration 的参数。

大家如果感兴趣可以参考这篇 paper:Automatic Online Calibration of Cameras and Lasers,详细的讲述了其中的数值原理,可以看到绿色的是 3D 点投射到图像上,是一些边界点候选的区域,如果有一个比较好的标定结果,这些边界点会比较好的和图像匹配起来。
3. 传感器视场角
接下来看下传感器不同视场角带来的融合问题。

这里有一个简单的示意图,假设在这个位置上有两个激光雷达,它们有各自不同的视场角,但是前方有个障碍物 A 刚好在传感器2的视场角内把障碍物 B 完全遮挡了,障碍物 B 只出现在一个传感器检测的视场角内部,这带来的问题是:我们到底该不该相信这里存在一个障碍物?这是比较常见的问题,需要我们经过不断的路测,来完善。
▌如何做传感器融合?
1. Camera Lidar Fusion

首先讲下照相机和激光雷达融合,方法1之前大概讲过,就是说激光雷达有 ( x,y,z ) 比较明确的 3D 观测,通过标定参数,通过照相机本身的内参,就可以把 3D 点投到图像上,图像上的某些像素就会打上深度信息,然后可以做基于图像的分割或者 Deep Learning Model。需要注意的是,多传感器的时候,视场角可能会不一样,可能会造成噪点或者漏点,这里比较推荐的方法是把照相机和雷达安装在一起,越近越好。
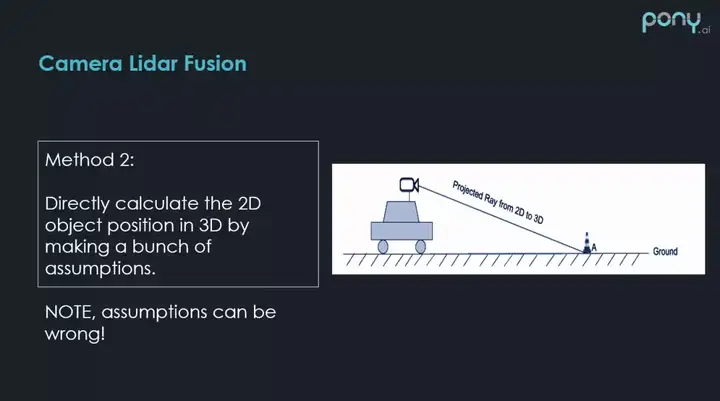
另一个比较直观的方法,是否能将 2D 检测出来的障碍物直接投影到 3D,然后生成这样的 3D 障碍物,这种方法,在做很多的假设条件下(比如障碍物的大小,地面是否平整),也是可以做的,如上图,相机的内参,车的位置高度,都是已知的,这时在 2D 上识别出的每个帧的障碍物,都可以还原成 3D 在照相机坐标系下的一条射线,然后找这条射线在 3D 坐标系下和平面的交点,就可以估计出 2D 障碍物在 3D 上的距离。
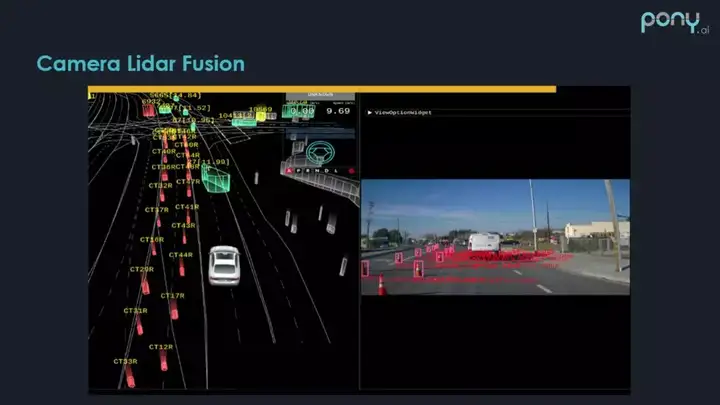
上图为 Pony 在建筑工地旁采集的数据,可看到这些路障都是直接生成到 3D 的(图中有个漏点,也是我们还需要努力提高的)。
2. Radar Lidar Fusion

至于毫米波雷达和激光雷达的融合方式就更简单了。因为在笛卡尔坐标系下,它们都有完整的 ( x,y ) 方向的信息,那么在普适的笛卡尔坐标系下,做针对于距离的融合,而且毫米波雷达还会测速,对障碍物速度也是有一定观测的,然后激光雷达通过位置的追踪,也会得到障碍物速度的估计,这些速度的信息也可以用来做融合,帮助筛选错误的匹配候选集。
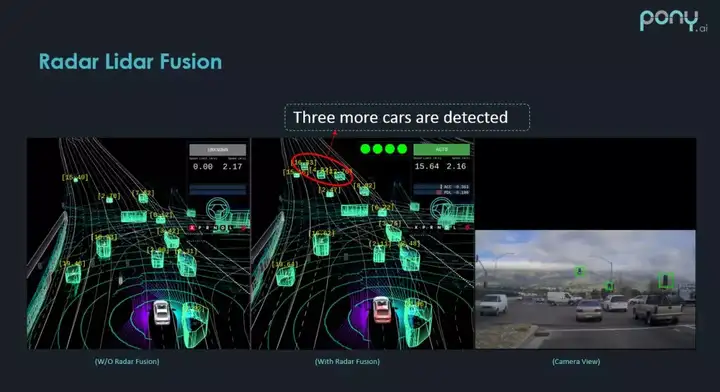
这是 Pony 激光雷达和毫米波雷达融合的效果,红圈里的障碍物是 radar 补充的。

当然,不同传感器之间融合的特例还是很多的,比如激光雷达和毫米波雷达融合的时候,可以看到,这个场景是前方有比较高的路牌时,毫米波雷达会在这个位置产生障碍物,恰好激光雷达也有噪音,因为恰好前方有车,这时在牌子底下也会产生噪点,所以激光雷达和毫米波雷达都在这个地方检测出来本不应该出现的障碍物,这时两个传感器都告诉你前方有个障碍物,只有摄像头说前方只有一个障碍物,这时该怎么办?(如果想了解 Pony 具体如何解决的,欢迎大家加入 Pony,我会告诉你答案o(∩_∩)o)
▌总结
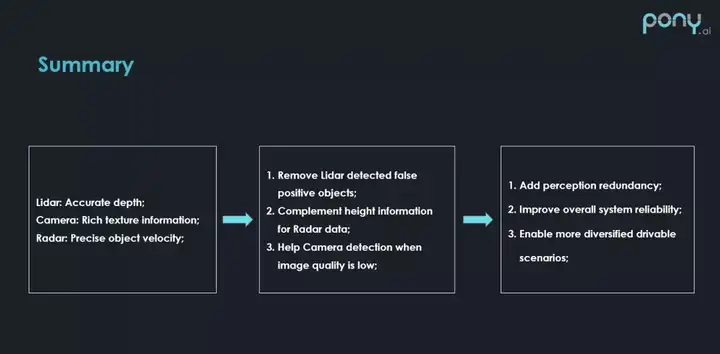
总结来说,每个传感器都有自己的一些问题,传感器融合就是说我们要把这些传感器结合起来做取长补短,提升整个感知系统的精度和召回度,今天就分享到这里,谢谢大家。
分享嘉宾:刘博聪 Pony.ai
编辑整理:Hoh Xil
内容来源:Pony.ai & DataFun AI Talk
出品社区:DataFun
注:文章虽好,记得点赞哦!