https://blog.csdn.net/hy_jz/article/details/78877483
基于meta-path的异质网络Embedding-metapath2vec
metapath2vec: Scalable Representation Learning for Heterogeneous Networks
metapath2vec https://dl.acm.org/citation.cfm?id=3098036是17年发表的,使用基于meta-path的随机游走重构节点的异质邻居,并用异质的skip-gram模型求解节点的网络表示。DeepWalk 是同质网络中的表示学习方法,并不能直接应用到异质网络。比如:并不能解决多种类型节点的“word-context”对的问题,异质网络中的random walk问题。
本文提出了两种模型,metapath2vec 和 metapath2vec++。模型框架如下图所示:
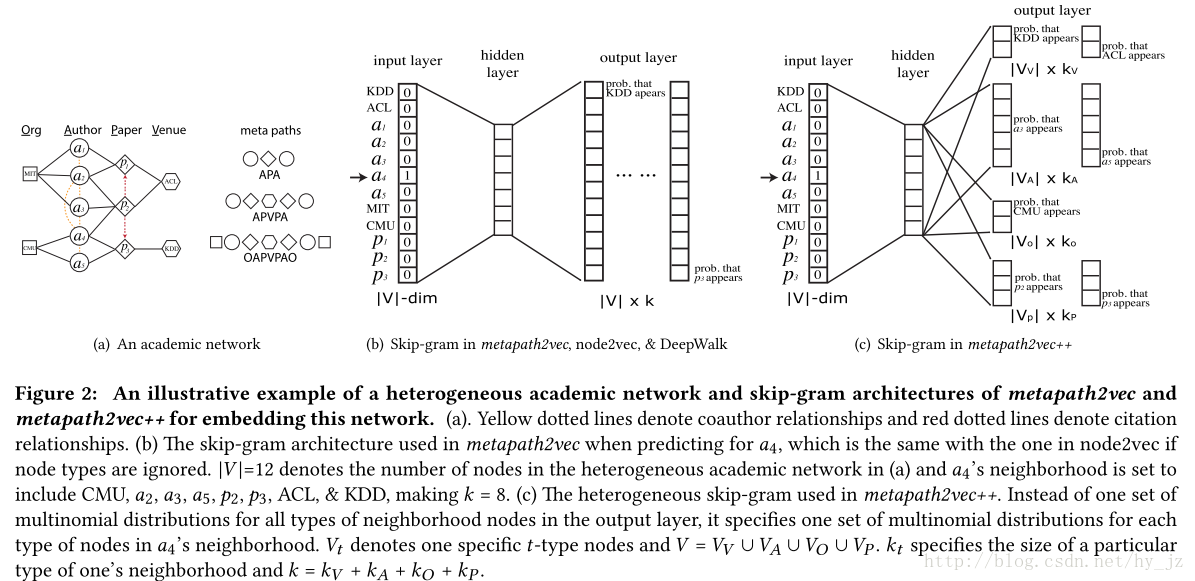
- Heterogeneous Skip-Gram
对于一个的异质网络,metapath2vec通过skip-gram模型学习网络表示。给定一个节点v, 它最大化节点的异质上下文(context)
条件概率定义为soft-max函数。
这个公式,每计算一次,就会遍历所有的节点,计算起来并不高效,根据Word2vector中的负采样优化,上式可以写为
metapath2vec在构建P(u)分布的时候,忽略了节点的类别信息。
- Meta-path-based Random Walks
跟deep walk是类似的,本文也是通过随机游走的方式保留网络结构。但是在异质网络中,决定游走下一步的条件概率 不能像deep walk那样,直接在节点的所有邻居上做标准化(Normalized Probability)。如果这样做忽略了节点的type信息。yizhou su etc.在论文PathSim http://web.engr.illinois.edu/~hanj/pdf/vldb11_ysun.pdf中指出:异质网络上的随机游走生成的路径,偏向(biased)于高度可见的节点类型(具有优势/主导数量的路径的节点)和 集中(concentrated)的节点(即:具有指向一小组节点路径的 大部分百分比)。因而,本文提出了基于元路径的随机游走,捕获不同类型节点之间的语义和结构相关性。
给定一个异质网络 G=(V,E,T) 和meta-path 那么第i步的转移概率可定义为:
其中, 并且代表的是节点的邻居中属于t+1type的节点集合。换句话说,游走是在预先设定的meta-path 的条件上。而且,meta-path一般都是用在对称的路径上:

部分源代码
meta-path-based Random Walk的源代码连接https://www.dropbox.com/s/0ss9p4dh91i3zcq/py4genMetaPaths.py?dl=0

作者在论文中用的meta-path是”APVPA”。
-
metapath2vec++
这就为skip-gram最后一层输出层中的 每个类型都指定了一个多项分布。负采样的目标函数:
metapath2vec在计算softmax时,忽略了节点类型。换句话说,在采集负样本时,没有考虑样本是否与正样本属于同一个节点类型。因而本文提出,异质的负采样 (Heterogeneous negative sampling)。也就说条件概率在特定的节点类型上做标准化。 -
实验
在实验方面,本文主要做了multi-class分类,节点聚类,相似性搜索,可视化。
本文将AMiner数据集按照论文发表的会议分为八大类,对于每个作者节点的标签,则是选择作者曾经发表的论文中,占比例较大的标签;如果是相等的,那么从中随机选择一个标签。
在聚类任务上,作者使用的是K-Means的方法,NMI指标。
从代码实现来看,本文主要研究的是作者-会议之间的一种关系,这种关系并不能直接观察到,而是通过作者-论文-会议这样一种路径构建的。因而,最终学到的只是作者、会议节点的embedding向量表示。在分类等任务上也是针对的作者,会议节点。
metapath2vec: Scalable Representation Learning for Heterogeneous Networks 阅读笔记
转载请注明出处:
每周一篇机器学习论文笔记zhuanlan.zhihu.com
论文来源:KDD 2017
论文链接:2017_KDD_metapath2vec...
论文原作者:Yuxiao Dong , Microsoft Research , Homepage
(侵删)
Abstract
这篇文章是关于异构网络的特征表示学习。异构网络的最大挑战来源于不同种类的节点与连接,因此限制了传统network embedding的可行性。论文提出了两种特征学习模型:metapath2vec以及metapath2vec++,它们的具体做法是基于元路径的随机游走来指定一个节点的邻居,之后利用异构skip-gram模型来实现embedding。
Introduction
传统的网络挖掘方法,一般都是先将网络转化成邻接矩阵,然后再用机器学习的模型从而完成网络挖掘任务,比如社区检测,连接预测,离群点检测等等。然而这样的话,邻接矩阵通常都很稀疏,且维数很大。network embedding是近来比较火的领域,近几年也是发展迅猛。它主要是从网络中学到隐式的表达矩阵,使得网络重要的信息能够被包含在一个新的相对低维的空间向量中,之后再对这个隐式表达矩阵采样机器学习的算法,从而能够更好地完成网络挖掘任务。
近年来各种顶会上也出现了很多network embedding的文章,公认不错的一些算法有deepwalk, node2vec, line等等,然而它们大多数都是针对同构网络的,也就是忽略了网络的异质性,只考虑一种节点对象中的一种关系。然而,现实生活中更多存在的网络是包含不多种类的节点以及连接。比如在DBLP网络,节点种类有会议,论文,作者等,而不同种类节点之间的连接也代表着不同语义,比如说论文和论文之间存在着引用和被引用关系,作者和作者存在合著关系,论文和会议存在发表/被发表关系。因此相比于同构网络,异构网络融合了更多信息,以及包含更丰富的语义信息。所以作者提出了两个在异构网络做network embedding的算法模型,metapath2vec以及metapath2vec++。
Algorithm
这篇论文的算法还是比较简单的。首先回顾deepwalk算法,它的原型是NLP领域中Mikolov提出的word2vec算法,本质上是基于神经网络建立统计语言模型的表示学习。
word2vec算法在网上已经有很多大牛进行过浅谈详解,感兴趣的可以查一查。
word2vec主要有两种模型,一种是CBOW,一种是Skip-Gram。 CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。经过学习,隐层到输出层的权重参数就是最后所需的该单词的词向量,也就是我们需要的embedding空间。
将word2vec的想法应用到网络分析中是14年KDD的Deepwalk提出来的。思路很简单,就是通过在网络上随机游走,从而保存“单词上下文”这样一个概念。将每一条随机游走路径看做一句话,节点看做单词,节点的邻居节点看做上下文,之后同样是利用Skip-Gram模型来完成network embedding。
随机游走从局部上一定程度保持了节点与它邻居之间的连接性,即网络结构信息,然而对于异构信息网络来说,由于节点与连接的异质性的存在,所以异构network embedding最大的难点在于如何有效地在多种类型节点之间保存“节点上下文”的概念。
论文提出的想法是:基于预先指定的元路径来进行随机游走来进行随机游走,构造路径,从而能够保持“节点上下文”的概念。
meta-path-based random walks:

这样一来就可以产生一条在不同类型的节点之间且能同时捕捉到网络结构信息以及语义的路径。
在得到随机游走路径后,就可以进行skip-gram的建模。论文提出了两种算法:metapath2vec以及metapath2vec++,它们唯一的不同是skip-gram不同。在metapath2vec中,softmax值是在所有节点无论什么类型上进行归一化;而在metapath2vec++中,softmax值是在相同类型节点上进行归一化。
softmax in metapath2vec:
softmax in metapath2vec++:
由于网络的节点一般很多,归一化会耗时严重,所以会采样负采样进行优化加速。直接用原始softmax函数里的分子定义了逻辑回归的函数,所以objective function为:
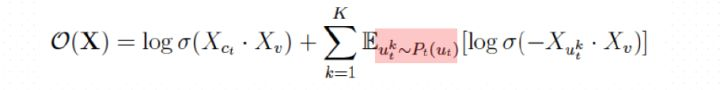
Experiment
(作者主页分享了代码以及数据)
对比实验主要有Deepwalk,node2vec,LINE,PTE,实验进行了三个任务,分别是:节点多分类,社区挖掘,相似度搜索。数据采用的是AMiner Academic Network,包含3m个论文节点,3800+会议节点,1.7m作者节点,人为地划分了8个领域,给会议以及作者节点标上类标。
节点多分类任务用的是逻辑回归分类,测量指标为Macro-F1和Micro-F1;社区挖掘用的是KMeans算法,测量指标是NMI;相似度搜索是一个case study,用的是cosine similarity进行相似度测量。实验结果显示,论文提出的算法效果更好。
除此之外,论文提出的算法也适用于并行化运行。
个人看法
这篇论文的思路比较简单:就是通过一个基于元路径的随机游走,从而将异构信息网络和network embedding这个领域结合在了一起。不过最后embedding得到的隐式表达矩阵是在同一个向量空间的,意思就是虽然异构信息网络的节点种类不同,但都是通过同一个embedding向量空间去表示它们,个人觉得这里会有点欠乏解释性。
network embedding在异构信息网络这一块的话还有很多地方可以探究,需要继续努力学习,希望能有自己的发现。

在论文笔记《Inductive Representation Learning on Large Graphs》中,我们介绍了一种归纳式学习图节点特征表示的算法--GraphSAGE。 在该笔记的最后提到了该方法的一些不足,如1)为了计算方便,每个节点采样同等数量的邻居节点;2)邻居的特征通过Mean、 LSTM、Max-Pooling等方式聚集,平等对待所有邻居节点。基于GraphSAGE,本篇论文引入了注意力机制,通过学习赋予不同邻居节点差异化的重要性且避免了采用过程。同时,邻居节点的特征是根据权值来聚集的,即相似的节点贡献更大。

模型:
给定图上所有节点在当前层的输入h,假设我们当前需要更新节点i的表示,j表示节点i的一个邻居。那么节点j对i的重要性系数的计算公式如下:

其中,a为注意力模型,线性变换参数W为可学习的权值矩阵,h_i和h_j分别是i和j节点在上一层的输出,亦即本层的输入。在上面的计算中,节点i是可以attend到全部的节点。考虑图本身的结构特征后,使用掩码将节点i的非邻居节点全部掩盖。由于下面的公式使用了softmax函数,mask中非i邻居节点的位置可以置为负无穷。

N_i表示节点i的所有邻居。本篇论文中,注意力机制是由一层全连接网络实现的,如下:

Alpha为权值向量。在最终的聚集过程中,按注意力机制得到的权值进行加权求和并紧跟一层非线性变换,如下:

进一步,参考谷歌机器翻译中采用的“multi-head self attention",本文也使用了“multi-head”机制,最后将各个头attention的结果进行拼接或取平均(本文实验用了拼接)。

模型的优点:
-
计算高效。模型中的注意力机制可以在所有的边上并行,节点的特征计算也是可以并行的。模型不需要类似特征分解这样高复杂度的矩阵操作。
-
不同于GCN,模型允许为不同的邻居赋予不同的权值。对注意力权值的分析可以增加模型的解释性。
-
注意力机制的参数是共享的,且可以区分对待有向边,因此可以扩展到有向图上。同时,使用局部邻居聚集的方式也保证了模型可以扩展到训练过程未见过的节点。
-
避免了GraphSAGE中采用固定数量的邻居。

模型的缺点:
因为attention本质上是在所有的节点(不仅仅是邻居节点)上计算的,当图的节点数目过大时,计算会变得非常低效。作者在论文中提出了这个问题,并留作未来的工作。
评估:
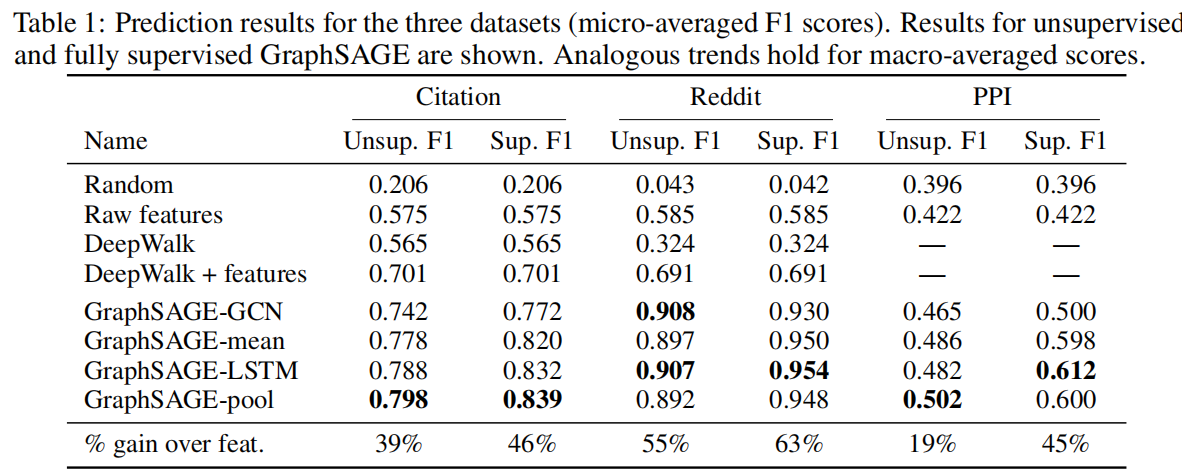
使用的数据集有:Cora,Citeseer和PPI。 在transductive learning任务上,GAT相比之前的state-of-the-art GCN有显著提升。 在inductive learning任务航,GAT相比GraphSAGE的提升更为明显,micro-averaged F1由0.612提升到0.942。
总结:
本篇论文提出的方法能够有效的进行邻居特征聚集,但是问题是还不能在大规模图上应用(全局attention的限制)
Inductive Representation Learning On Large Graphs【阅读笔记】
前言
Network Embedding 旨在为图中的每个顶点学习得到特征表示。近年的Deepwalk,LINE, node2vec, SDNE, DNGR等模型能够高效地、直推式(transductive)地得到节点的embedding。然而,这些方法无法有效适应动态图中新增节点的特性, 往往需要从头训练或至少局部重训练。斯坦福Jure教授组提出一种适用于大规模网络的归纳式(inductive)学习方法-GraphSAGE,能够为新增节点快速生成embedding,而无需额外训练过程。
大部分直推式表示学习的主要问题有:
- 缺乏权值共享(Deepwalk, LINE, node2vec)。节点的embedding直接是一个N*d的矩阵, 互相之间没有共享学习参数。
- 输入维度固定为|V|。无论是基于skip-gram的浅层模型还是基于autoencoder的深层模型,输入的维度都是点集的大小。训练过程依赖点集信息的固定网络结构限制了模型泛化到动态图的能力,无法为新加入节点生成embedding。
模型
本文提出了一种基于邻居特征聚集的方法,由以下三部分组成:
- 邻居采样。因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居。
- 邻居特征聚集。通过聚集采样到的邻居特征,更新当前节点的特征。网络第k层聚集到的 邻居即为BFS过程第k层的邻居。
-
训练。既可以用获得的embedding预测节点的上下文信息(context),也可以利用embedding做有监督训练。
在实践中,每个节点的receptive field设置为固定大小,且使用了均匀采样方法简化邻居选择过程。作者设计了四种不同的聚集策略,分别是Mean、GCN、LSTM、MaxPooling。
-
Mean Aggregator: 对所有对邻居节点特征取均值。
- GCN Aggregator: 图卷积聚集W(PX),W为参数矩阵,P为邻接矩阵的对称归一化矩阵,X为节点特征矩阵。
- LSTM Aggregator: 把所有节点按随机排列输入LSTM,取最终隐状态为聚集之后对表示。
- Pooling Aggregator: 邻接特征经过线性变换化取各个位置上对最大值。
模型最终的损失函数为edge-wise loss,也使用了负采样方法。

代码解析
GraphSAGE代码的开源地址here。在此,我针对部分关键代码进行解析。
首先,邻接表的构建和采样分布在minibatch.py和neigh_samplers.py中,
def construct_adj(self):
adj = len(self.id2idx)*np.ones((len(self.id2idx)+1, self.max_degree))
deg = np.zeros((len(self.id2idx),))
for nodeid in self.G.nodes():
if self.G.node[nodeid]['test'] or self.G.node[nodeid]['val']:
continue
neighbors = np.array([self.id2idx[neighbor]
for neighbor in self.G.neighbors(nodeid)
if (not self.G[nodeid][neighbor]['train_removed'])])
deg[self.id2idx[nodeid]] = len(neighbors)
if len(neighbors) == 0:
continue
if len(neighbors) > self.max_degree:
neighbors = np.random.choice(neighbors, self.max_degree, replace=False)
elif len(neighbors) < self.max_degree:
neighbors = np.random.choice(neighbors, self.max_degree, replace=True)
adj[self.id2idx[nodeid], :] = neighbors
return adj, degclass UniformNeighborSampler(Layer):
"""
Uniformly samples neighbors.
Assumes that adj lists are padded with random re-sampling
"""
def __init__(self, adj_info, **kwargs):
super(UniformNeighborSampler, self).__init__(**kwargs)
self.adj_info = adj_info
def _call(self, inputs):
ids, num_samples = inputs
adj_lists = tf.nn.embedding_lookup(self.adj_info, ids)
adj_lists = tf.transpose(tf.random_shuffle(tf.transpose(adj_lists)))
adj_lists = tf.slice(adj_lists, [0,0], [-1, num_samples])
return adj_lists可以看出:在构建邻接表时,对度数小于max_degree的点采用了有重复采样,而对于度数超过max_degree的点采用了无重复采样。
接下来,在真正为每个batch内的目标点选取receptive field点时,其代码在model.py中,如下:
def sample(self, inputs, layer_infos, batch_size=None):
""" Sample neighbors to be the supportive fields for multi-layer convolutions.
Args:
inputs: batch inputs
batch_size: the number of inputs (different for batch inputs and negative samples).
"""
if batch_size is None:
batch_size = self.batch_size
samples = [inputs]
# size of convolution support at each layer per node
support_size = 1
support_sizes = [support_size]
for k in range(len(layer_infos)):
t = len(layer_infos) - k - 1
support_size *= layer_infos[t].num_samples
sampler = layer_infos[t].neigh_sampler
node = sampler((samples[k], layer_infos[t].num_samples))
samples.append(tf.reshape(node, [support_size * batch_size,]))
support_sizes.append(support_size)
return samples, support_sizes这里采样的过程与BFS过程相似,首先找到一个目标节点,之后是该节点的一阶邻居节点,再之后是所有一阶节点的一阶节点。参见该issue。
资源列表
Paper: https://arxiv.org/abs/1706.02216
Code: https://github.com/williamleif/GraphSAGE
Project page: http://snap.stanford.edu/graphsage
Inductive 表示学习 on Large Graphs
Inductive Representation Learning on Large Graphs
摘要
大的图结构中,低维的节点的embedding,被证明在很多任务十分有效,
然而,现在大多的做法,在训练embedding的时候 需要所有节点都在图结构中出现,
即之前的做法本质是transductive的 不能泛化到之前未见的节点,
所以我们提出GraphSAGE,一个inductive模型 可以使用 比如文本属性信息的节点特征 来产生之前未见节点的embedding,
不再训练所有节点的每个embedding,我们训练一个函数,通过从节点的邻节点采样和收集特征来产生embedding
在节点分类等任务超越业界最佳
一,引言
把图结构embedding成向量表示,再输入下一个神经网络,进行节点分类等任务,是大家的做法,
然而,之前的做法,是针对一个固定的图结构,但现实需要快速产生未见节点的embedding,或者产生一个全新图结构的所有节点embedding,
我们利用节点特征,(如文本属性,节点属性,节点等级)来训练一个embedding函数 以泛化到没见的节点
我们训练一组aggregator函数来从一个节点的邻节点aggregate特征信息,每个aggregator函数从不同的hops或搜索深度aggregate信息,
二,相关工作
三,GraphSAGE
三,1,Embedding生成
假设现在模型已经训练好,也就是假设已经训练好K个aggregator函数,
表示节点v在步骤k的embedding向量表示

三,2,损失函数
两两节点u和v的embedding向量表示z的无监督的损失函数:
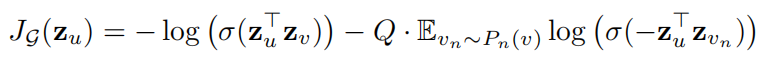
三,3,Aggregator结构
Mean aggregator:
表示节点v在步骤k的embedding向量表示
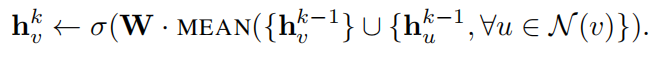
LSTM aggregator:
Pooling aggregator:
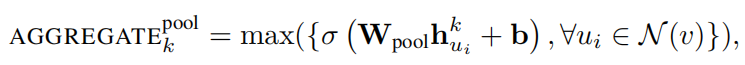
四,实验
节点分类结果: