作者 | 阚长城
编辑 | 张慧芳
题图 | 站酷海阔
人类几千年的文明催生了城市的发展,计算机与复杂科学带给我们新的资源——大数据。罗马非一日建成,人力和时间成本极大,但试想一下,如果有了大数据,罗马的建成能够缩短多少天呢?如今,城市里藏了大量数据,那么它们到底是什么?又该如何被开采与利用?大数据如何辅助商业选址?
11月29日的数据侠实验室,百度地图资深研发工程师阚长城为大家介绍了如何开发和利用时空地理大数据,并结合百度慧眼的商业案例,解释了大数据在商业选址中的应用。本文是其演讲实录。
大家好,我今天的分享主要是以下三个方面:
- 地理时空大数据的介绍
- 基于时空大数据和人工智能技术在城市规划方面所做案例
- 基于时空大数据的商业选址案例
▍地理时空大数据
交通流量、气象信息、地理信息、手机信号均是时空数据。时空数据具有时间和空间属性,时间属性主要是指时间的变与不变;空间属性一方面是指空间的位置,另一方面是指空间的层次和距离。
现实世界中超过80%的数据都与地理位置有关,数据量非常大。时空数据来自众多数据源,且数据多样、异构。
定位数据
移动互联网时代定位是基础服务。外卖、打车、购物,甚至视频等APP都需要通过定位提供相应服务。比如说墨迹天气会根据位置显示天气;视频根据位置去推荐一些相关视频。
定位类型多样,包括卫星、基站、Wifi以及地磁等。基于卫星的定位,典型的是GPS定位,其优点是精度高,缺点是被高楼遮挡或处于室内时,定位精度较差。所以手机APP一般不直接使用GPS定位,而是使用综合的网络定位。

百度地图基于这些定位能力,开发综合的网络定位服务,通过SDK为开发者提供定位服务。定位及高精度定位技术难度大,门槛相对也较高。
主要从三个层面提供定位服务:
- APP层面:通过SDK对外提供定位服务
- 设备层面:提供系统级别定位
- 芯片层面
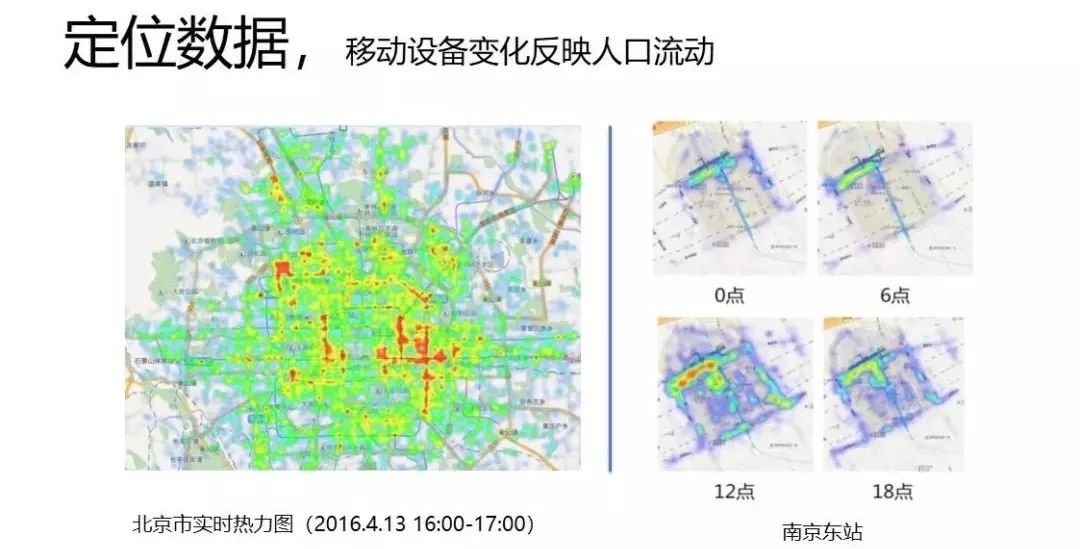
短期的定位可以反映人流的聚集和热力。如左图是北京某个时间的热力图,可以清晰区分人流量多少的区域,右图是南京东站一天的热力变化,可以看到从0点开始有人聚集,12点人最多,下午人又变少,定位数据可以非常直观地反映人流量的变化。
出行OD
基于用户每天900亿次的定位轨迹数据,可以挖掘其出行OD,针对长距离的跨城出行,我们做了百度迁徙,对应下图左边第一个图,中间的图是郑州和周边地区的出行OD,右边图是青岛某个交通小区的出行OD。

人口常驻
基于用户的长期位置和POI(兴趣点,Point of Interest)等相关数据,挖掘全国超过13亿的常驻人口数据。
用户画像
从人的自然属性、社会属性等不同方面360度刻画产出超过万级的标签。
POI数据
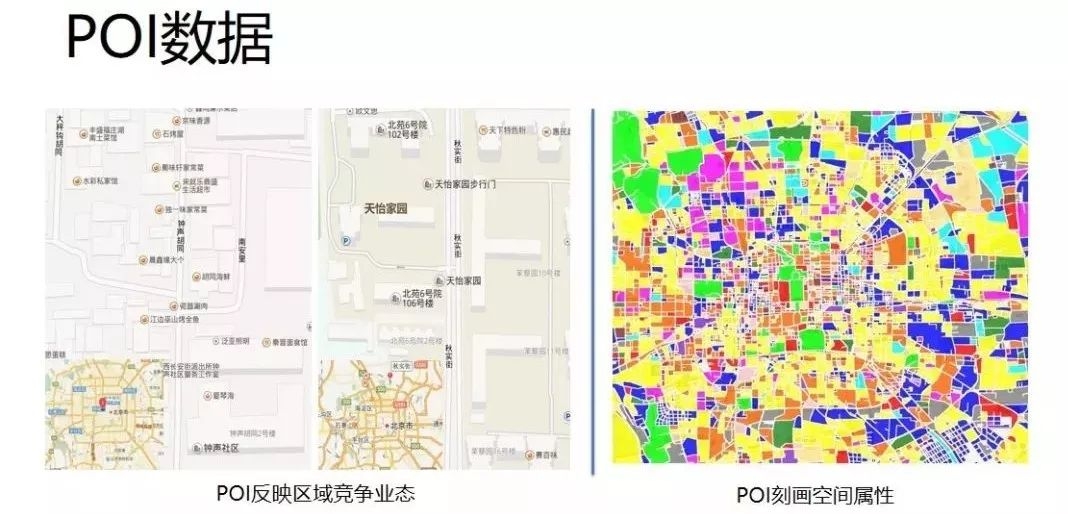
POI能够反映一个区域的经济发展水平和活力等。比如,下图中左边是北京二环和五环区域内餐饮类的POI,对比发现:二环的POI明显高于五环,说明POI的分布可以反映区域的竞争业态,右边四利用POI和人的活动模式挖掘的功能区,POI很大程度上可以刻画空间承载的功能。
路况大数据
路况可以清晰地反映路网的运行状态,比如在什么时间哪里最堵。路况数据的挖掘是基于公众数据、行业数据、卡口流量视频等利用AI技术挖掘得到。路况目前已经覆盖全国400多个城市,市内和城际道路覆盖超过99%。
▍时空大数据的应用
城市地理理解
首先,基于地图时空大数据,从不同的空间粒度进行建模,产出不同空间层次上的地理特征。空间层次依次从宏观到中观再到微观。
- 宏观层面:基于百度迁徙和常驻人口流动数据识别城市群,评价城市重要性。
- 中观层面:基于定位数据,对城市副中心发展绩效进行评估,同时基于全景图对街道品质进行评价。
- 微观层面:基于地块粒度,进行城市功能区的发现。
功能区的挖掘动机和挑战
城市规划周期一般在5到10年左右,规划之前往往需要了解现状、规划后的效果、如何跟踪等问题,传统手段时间较长,效率不高。基于百度地图POI、人口以及人的活动数据进行城市用地功能的识别,可以在短时间内识别全国各个城市的用地功能。
地理空间中的POI可以反映一个区域承载的功能,如反映某区域承载的是科研教育功能,不同的功能区人的活动模式也有差异,比如说下图,在工作日人们一般九点离家,下午五六点回家,POI和人的活动模式存在潜在语义信息。

但在挖掘过程中也存在很大的挑战:
- 模型方面,整体来说样本数据少、获取困难,分类问题转化为无监督模型;
- 特征方面,存在差异。对于POI类别不均衡的问题,比如餐饮类POI较多,而景区内POI较少;同类POI重要性不同,比如上图中黄焖鸡和全聚德属于同一区域,但是其重要性有很大不同。
在特征设计上,首先,利用路网数据将城市切分成一个个地块,然后以地块为单位进行特征提取,利用tf-idf计算不同类POI重要性,如可以降低餐饮类POI的重要性,然后提升景区类POI的重要性。 对于同类POI重要性不一致的问题,可以利用POI在地图上搜索热度解决。这样每个区域就对应一个各类POI重要性的向量。
其次,活动模式特征设计,将人的一次出行定义为出发目的地以及出发到达时间,区域间的联系及时间就构成文档中的单词。
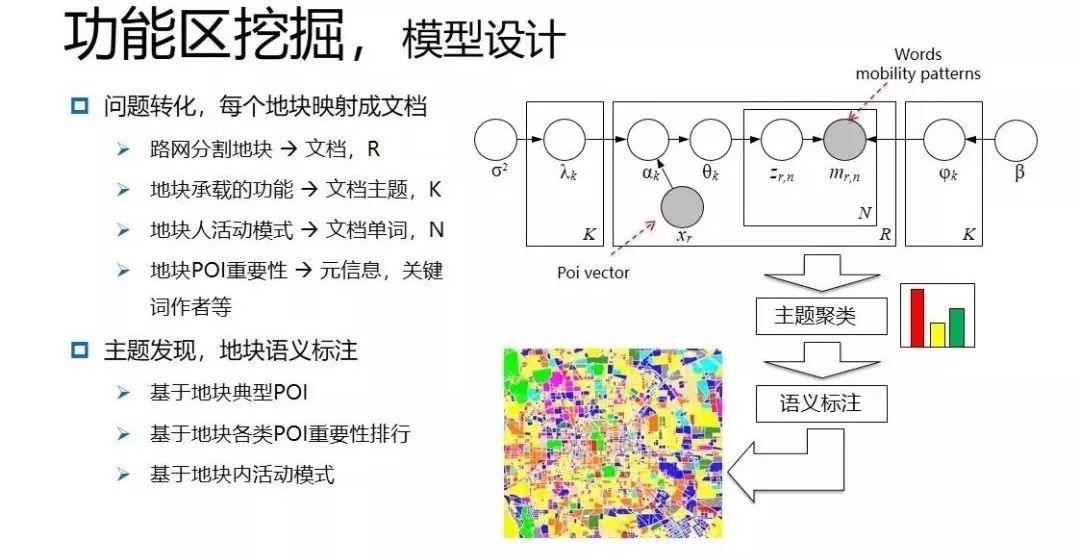
在模型设计上,第一,问题转化。
将区域类比成文档,区域承载的功能就类比成了文档的主题,活动模式就类比成了单词,然后区域POI重要性转化为文档元信息。
第二,主题发现,地块语义标注。
基于地块的Poi vector和活动模式,利用改进的LDA算法进行区域功能发现,然后进行主题聚类,基于地块各类POI重要性排行进行语义标注,最后得到最终挖掘结果图。
通过评估应用发现,第一,实际调研,其准确率为87%。
第二,专家知识。对宁波市进行功能区发现,并与宁波规划院一些专家确认其准确率较高,结果超过85%。
第三,规划现状。对比规划现状,发现符合预期。
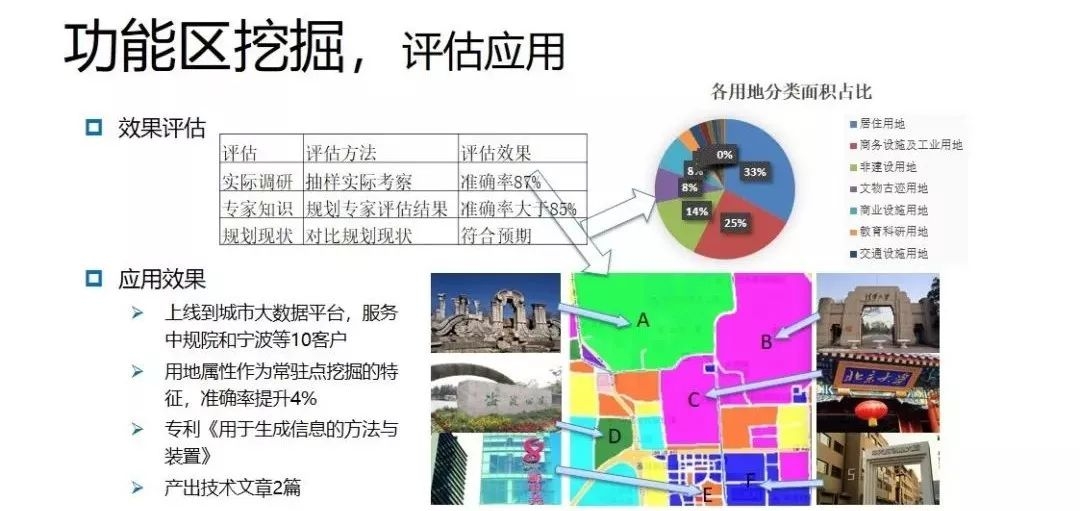
下图右上角统计了每种类型的功能区各类POI的占比,发现居住、商业、商务用地对应的POI类别前三名一致:均为公司、住宅和商业。说明居住、商业以及商务这三类POI相关性较强,土地混合利用的情况较为突出。
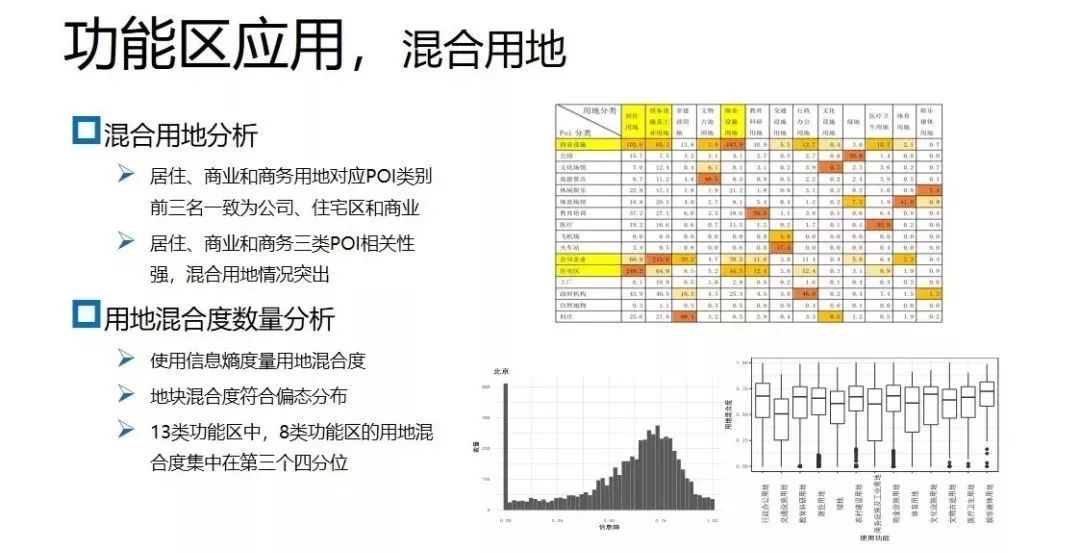
在评价土地混合度上,可以使用信息熵度量用地混合度。上图左下角是地块信息熵的分布,从图上可以看出,北京市中心城区的用地混合度成偏态分布。
由此说明,土地利用混合度有规律可循,进而可以对土地利用混合度进行建模。

在用地混合度空间分布上表现为:
- 用地混合度向外逐渐呈衰减趋势,大致呈同心圈层形态
- 用地混合度的空间分布呈现单中心结构
- 距离城市中心越远,用地混合度越低
在用地混合度建模上表现为:
- 发现用地混合度和距离的关系,符合幂指数衰减模型
- 对幂指数两边取对数,得到线性回归模型
- 对地块的混合度和地块离中心距离进行线性回归分析,发现城郊用地混合度波动较大,这是由于城郊存在副中心城市和卫星城镇,整体上呈组团式布局,使用地混合度的空间布局不均匀导致
如下图所示,通过segnet/unet全卷积神经网络,将图片分割成路面、天空、树木、建筑等十余个类别,再通过地理模型和机器学习算法挖掘街景的特征及其空间分布规律。

首先使用算法对全景图进行语义分割,上图是语义分割的结果,显示出每类要素的占比,然后利用热点识别算法进行整体的意向提取,利用非监督的聚类算法对街道特征分析。结果分析如下:

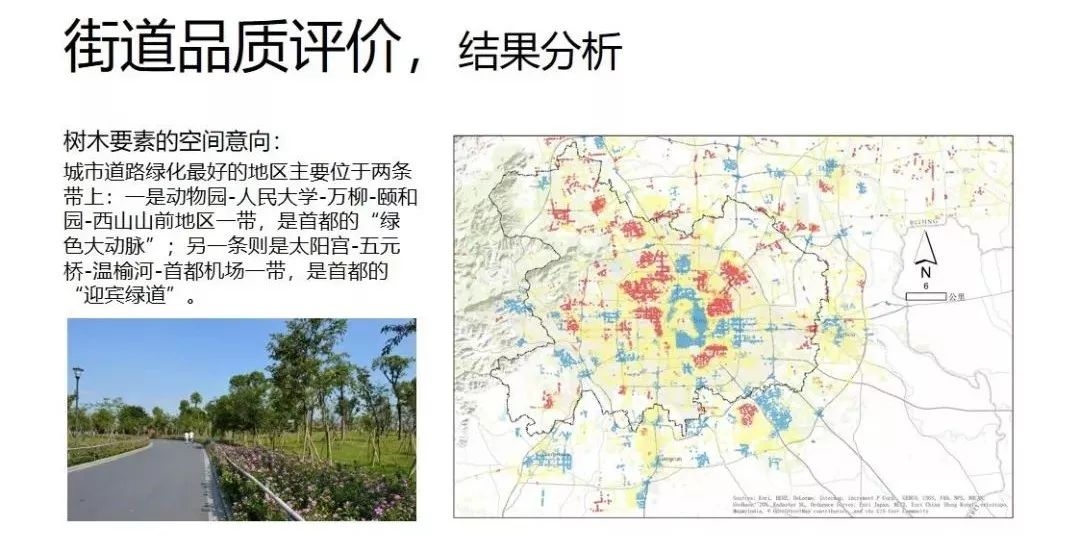
通过聚类分析根据每条道路上各类景观要素的占比进行聚类,将道路分为:
- 交通主导型
- 建筑密集型
- 景观空旷型
- 要素均衡型
- 绿化优良型
- 绿树成荫型

城市群的发现首先需要对人口迁徙数据进行分析,发现人口迁徙呈现不均衡现象,且胡焕庸线以西的人口迁徙规模和密度明显低于以东地区。
其中通过对各省份的迁徙数据分析发现,各省份的人口吞吐量极不均衡;既有广东、江苏、河北等人口流动大省,也有福建、甘肃、宁夏等迁徙规模较小的省份;空间上邻近的省份,短期人口的流动强度相对比较大;迁徙规模的大小既与该省份的人口基数相关,与该省份的空间区位、经济建设水平、区域发展态势等均有关联。
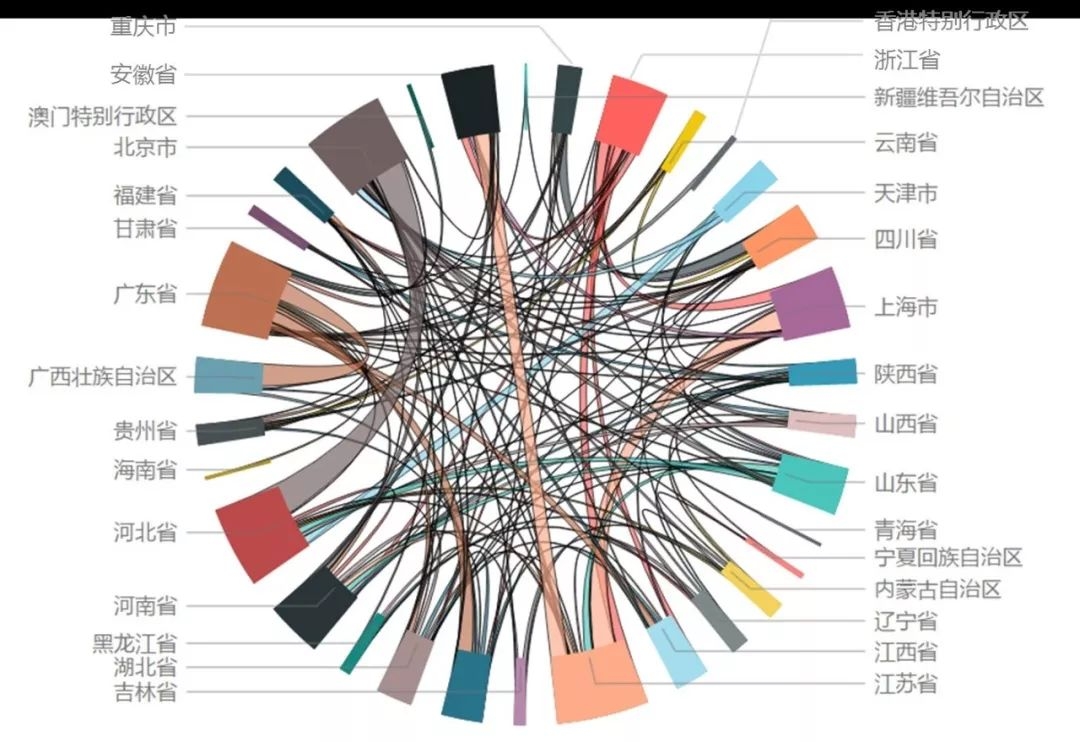
另外,关于城市群划定原则有以下几点:
- 城市间的联系强度足够大
- 城市群内各城市须在空间上邻近
- 城市群内各城市不一定在空间上直接接壤
在进行城市群挖掘时,能够基于人口迁徙数据,利用k壳分解算法进行挖掘。
基于人口迁徙和常驻人口流动数据,利用PageRank算法挖掘。结果显示:北京、上海、广州、深圳和成都是短期人口流动中的关键节点;东部沿海地区上短期人口流动呈现“带状均衡”模式;中西部地区的短期人口流动呈现“节点带动”模式。
城市人口理解
城市人口理解,基于地图出行位置大数据,挖掘人口在不同时间跨度下的个体和群体特征。针对人口瞬时流动我们做了人流量预测,针对人们的短期出行我们做了通勤和市内OD挖掘、跨城迁徙挖掘,基于人的长期位置信息我们做了常驻人口挖掘。
在人流量预测上,我们知道每隔几年都会发生一些踩踏事故,如果能提前知道热门区域的人流量,就可以避免踩踏等类似事情的发生,同时人流量预测在公共安全和交通管理领域都是非常重要的。但是预测人流量也存在着问题和挑战:特征表达方面,时间和空间特性、异常因素方面挑战,比如天气、节假日等原因;模型方面,传统时序模型很难对时空特性和异常建模。

在模型设计上,对于人流量的预测可以将其转化为图像领域的问题来解决。
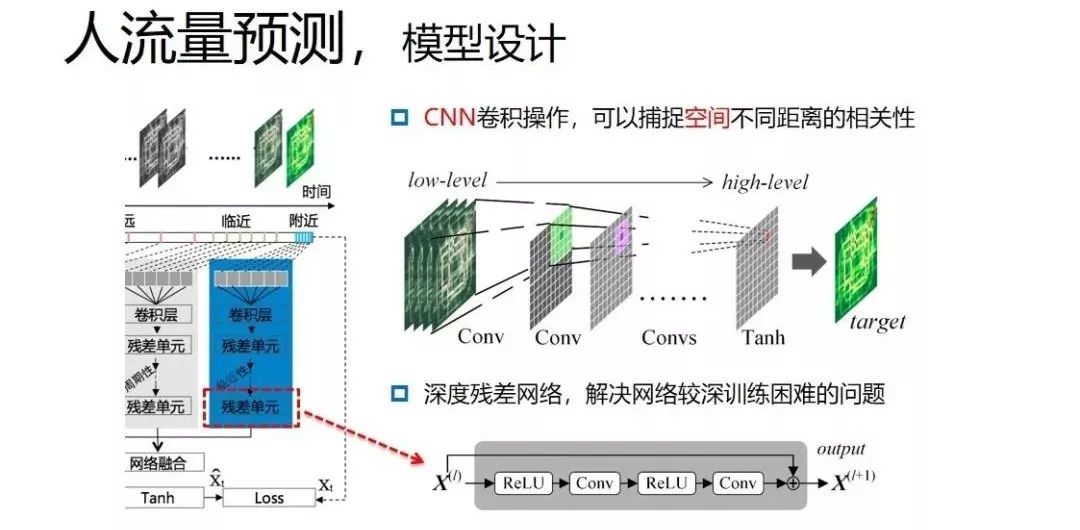
在解决时间特性、异常因素上时,基于2017年定位轨迹、地理属性和异常因素特征进行建模,将城市划分成网格,将定位数据投影到网格,计算每个网格的流入和流出人数,同时考虑POI热度,也就是将城市就转化成了一张图。网格就相当于图片中的像素,网格的流入和流出就相当于图片中的通道。人流量空间的相关性就相当于图片中像素之间的关系,多个时刻的数据对应多张图。如下图所示:
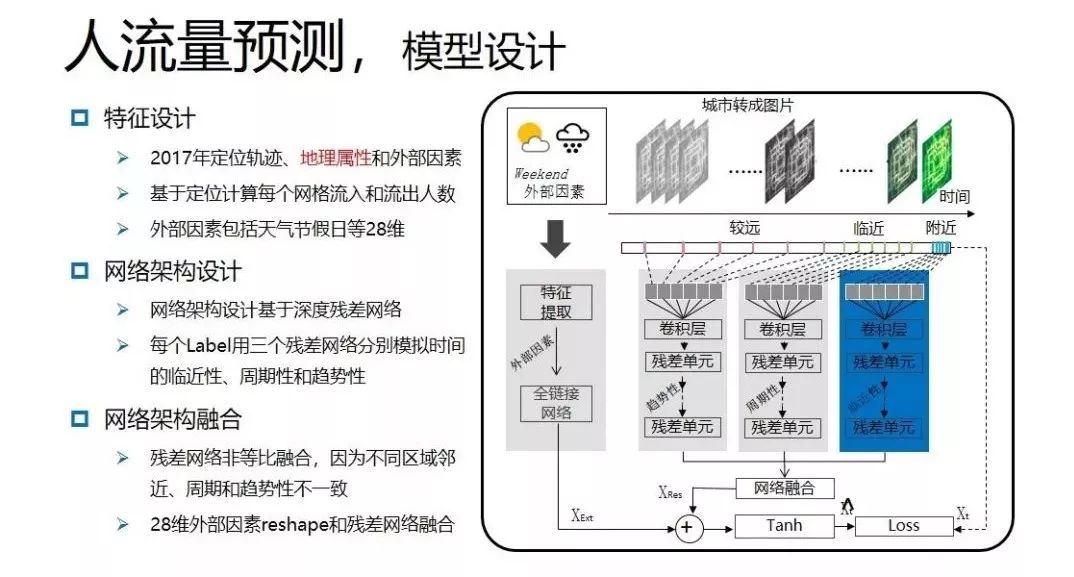
在将最近几张图的数据,放在上图中残差网络模型中,模拟时间的临近性,同时将对应时间的人流量置于中间的网络模型中模拟时间的周期性,最后进行网络融合,再和外部因素进行融合,就得到了整个网络架构。
另外,在解决空间相关性时,使用CNN卷积操作,可以捕捉空间不同距离的相关性。通过多层卷积捕捉较远区域的相关性问题,并引入深度残差网络,解决网络较深训练困难的问题。
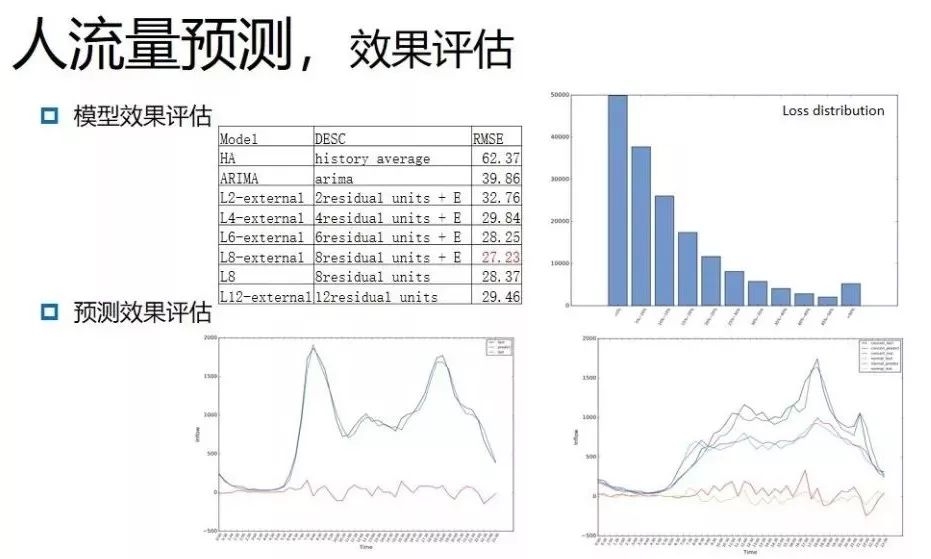
如下图所示,在损失分布上,损失在15%以内的网格超过了85%;在预测效果评估上,通过对规律性区域如回龙观地铁站人流量的进行预测,同时对突发场景如今年林俊杰演唱会人流量预测,发现模型的预测精度极高。
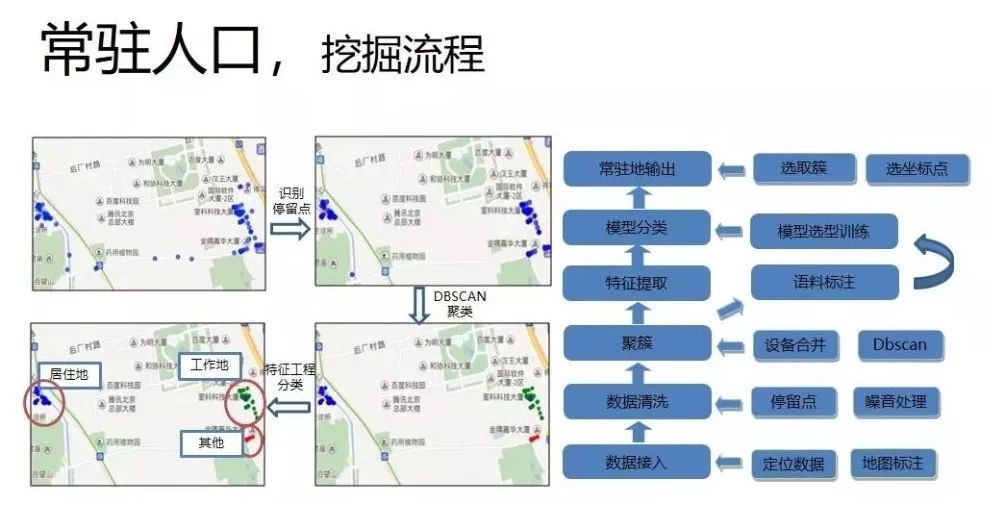
关于常驻人口,传统的全国人口普查,成本大,更新周期长;基于基站定位数据计算,仅依赖时间属性,数据存在badcase,比如互联网公司存在加班和三班制人员倒班现象;居住区也会有退休人员等。
下面是常驻点挖掘流程:
首先,地图标注用户六个月的定位数据;
其次,基于定位数据识别停留点,去掉路上其他地方噪点。
第三,利用DBSCAN空间聚类算法得到簇;
第四,对簇进行特征提取,利用机器学习分类的算法挖掘,得到用户居住地、工作地以及常去地等信息。
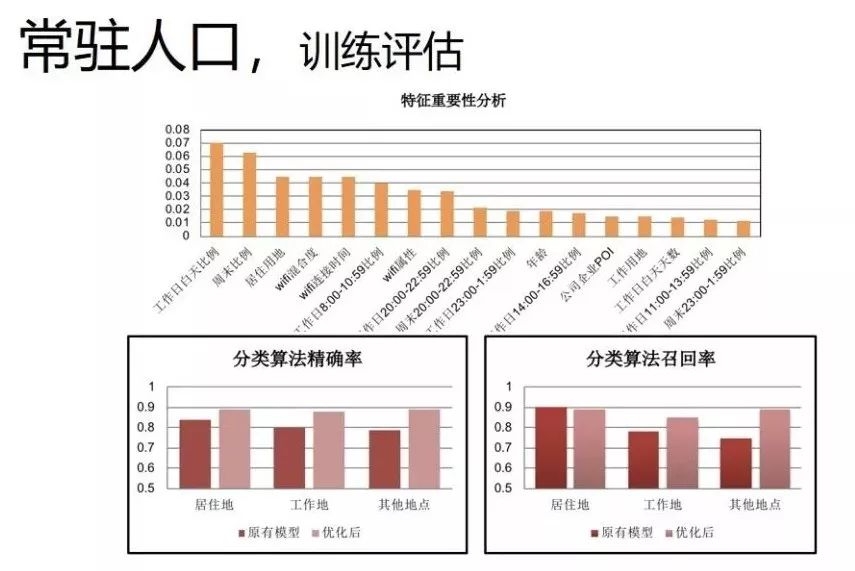
结果显示,其分类算法的准确和召回均约为90%。
以下图为例,青岛人口数据校核结果显示其人口误差率小于5%,天津人口数据校核显示,其相关系数约为0.85,通勤距离相差4%。
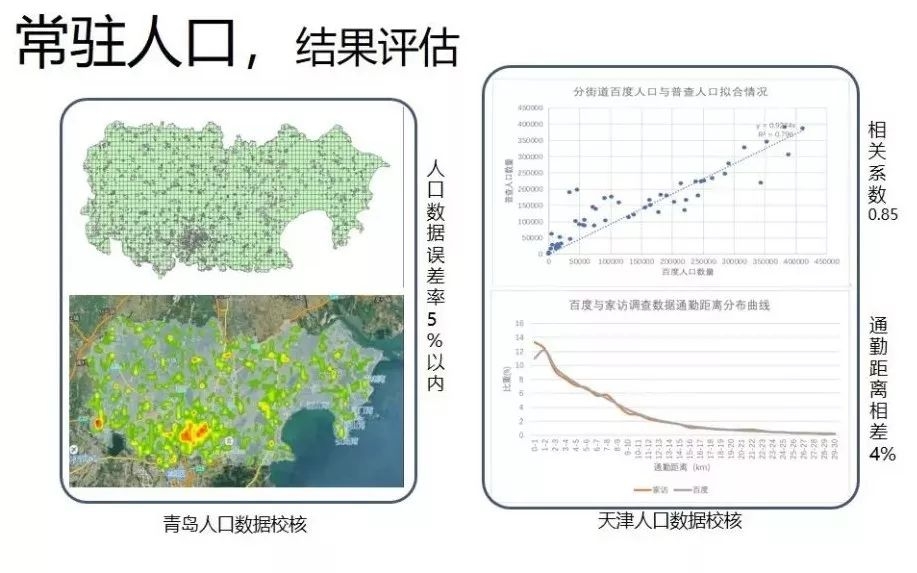
有了人口以及人的家和公司数据,再结合用户画像数据,我们就可以评估学校、医院等公共设施的配置,公园绿地的使用效率,任意区域的职住平衡和出行通勤等。
通勤是交通规划里的非常重要内容,通勤OD和方式和早晚高峰的拥堵是息息相关的。下面是通勤挖掘的流程:

上图左下角图显示,骑行和步行主要偏短距离的出行,公交和地铁主要偏中长距离的出行,说明通勤距离对用户通勤方式的选择非常重要。
最后,通过不同的算法,从整体准确召回率和各通勤方式精确召回率两个方面评估,发现精确率均在85%左右。
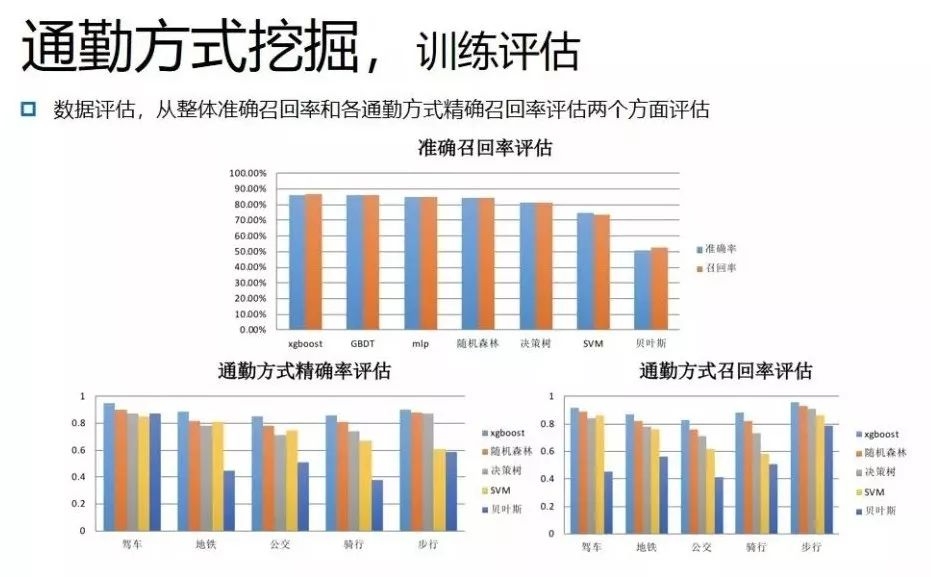
下面看一下各种通勤方式和土地混合度、地铁站点分布、路网密度之间的关系。
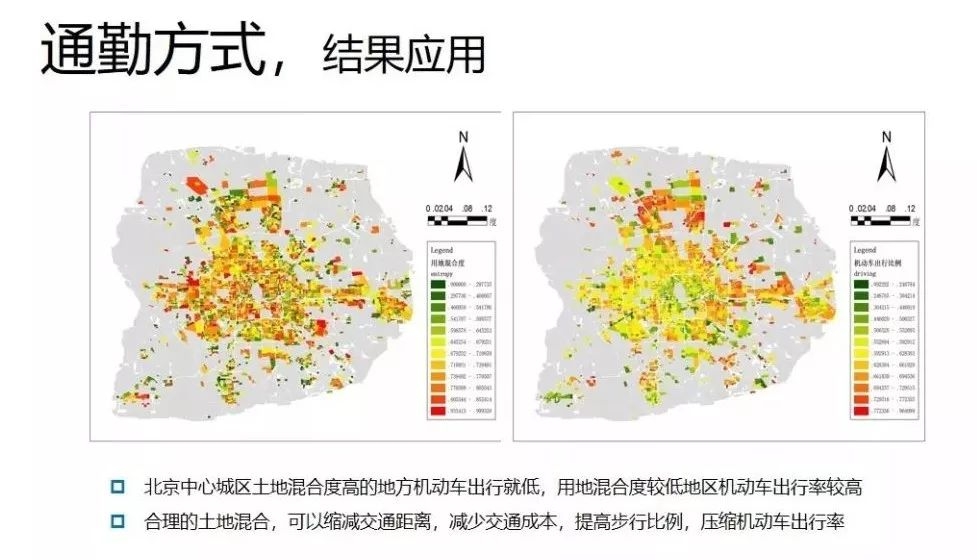
(图片说明:通勤方式和土地混合度的关系)
左图指用地混合度的空间分布情况,颜色越红表示用地混合度越高;右图是机动车通勤空间分布,越红代表该空间中人采用机动车通勤比例越高。从图中可以看出,北京中心城区土地混合度高的地方机动车出行就低,用地混合度较低地区机动车出行率较高。

(图片说明:通勤方式和地铁站点分布的关系,地铁站点密度越高的地区,地铁出行比例越高,地铁对机动车交通的压缩明显。)
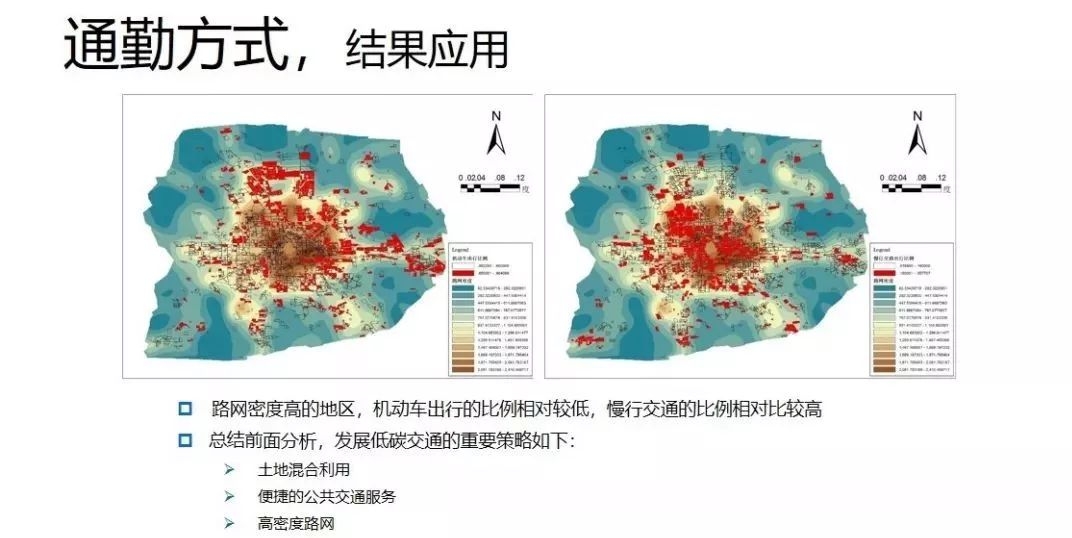
(图片说明:通勤方式和路网密度之间的关系,路网密度高的地区,机动车出行的比例相对较低,慢行交通的比例相对比较高。)
基于全网用户家和公司坐标以及通勤方式数据,可挖掘每个用户的通勤距离和时间。
下图所示,通勤距离,平均意义上,城市居民通勤距离人群占比分布呈现长尾型,即随着通勤距离的增加,对应的人群占比相应减小;近80%的城市居民平均单程通勤距离都在10km以内。

通勤时间,平均意义上,城市居民通勤时间人群占比分布呈现长尾型,即随着通勤时间的增加,对应的人群占比相应减小;接近80%的城市居民的平均单程通勤时间都在50min以内。

▍商业选址案例
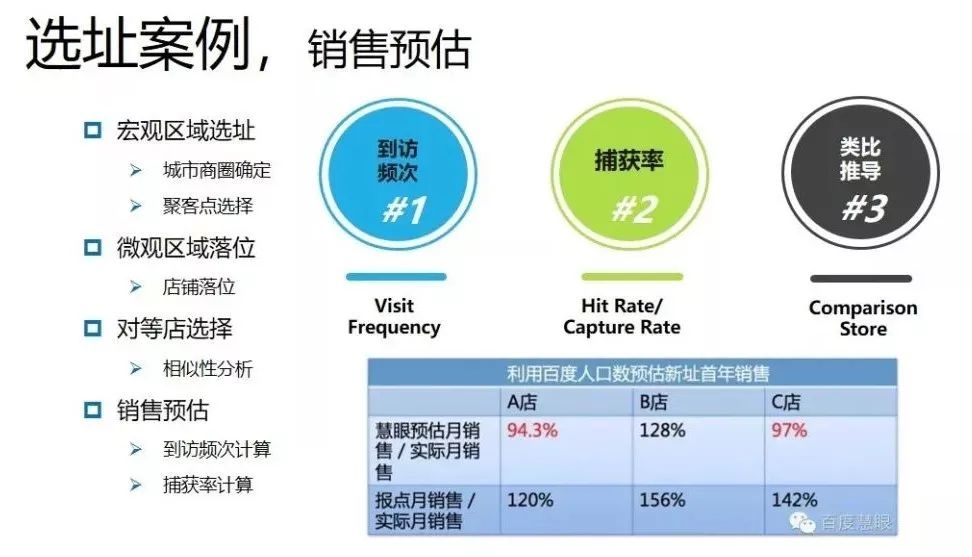
商业选址流程
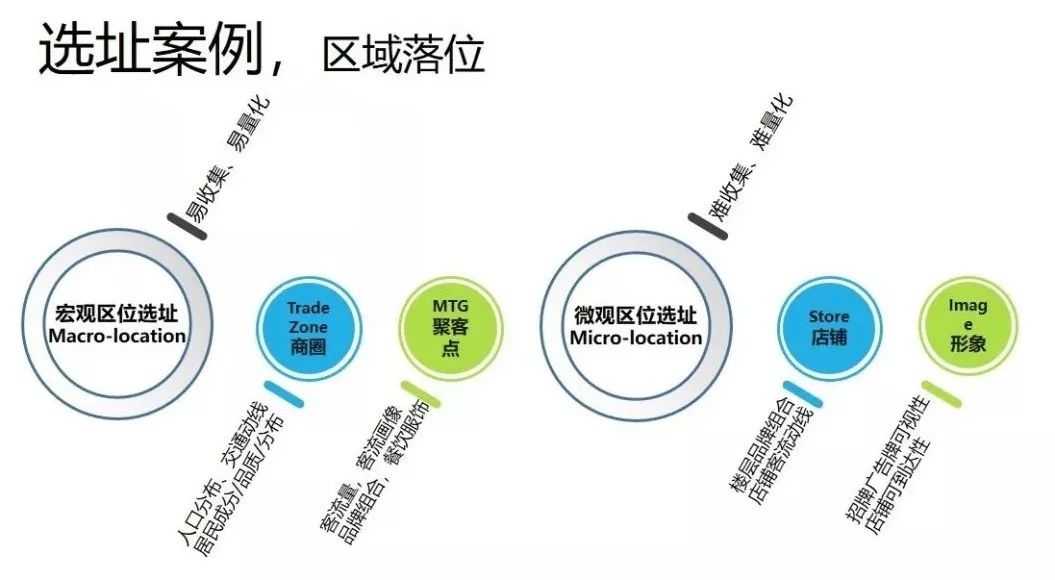
首先,宏观区位选址,包括商圈和聚客点的确定,可使用人口分布、交通动线以及居民的成分、品质、分布等数据进行选址。
其次,微观区位选址,主要指店铺具体落位,可通过楼层品牌组合以及店铺客流动线进行选址。
第三,对等店选择,主要使用相似性来选择对等店。
销售评估
根据对等店的到访频次和捕获率进行销售额预估。
注:以上内容根据嘉宾阚长城在数据侠线上实验室的演讲实录整理。图片来自其现场PPT,已经本人审阅。点击“阅读原文”,获取作者直播回放。
期待更多数据侠干货分享、话题讨论、福利发放?在公众号DT数据侠(ID:DTdatahero)后台回复“数据社群”,可申请加入DT数据社群。
▍加入数据侠
本文数据侠阚长城,百度地图资深研发工程师,主要从事机器学习、深度学习、时空大数据行业应用等领域,先后获得大数据行业应用相关专利6项。