




React Flux:
|
Flux将一个应用分成四个部分。
- View: 视图层
- Action(动作):视图层发出的消息(比如mouseClick)
- Dispatcher(派发器):用来接收Actions、执行回调函数
- Store(数据层):用来存放应用的状态,一旦发生变动,就提醒Views要更新页面
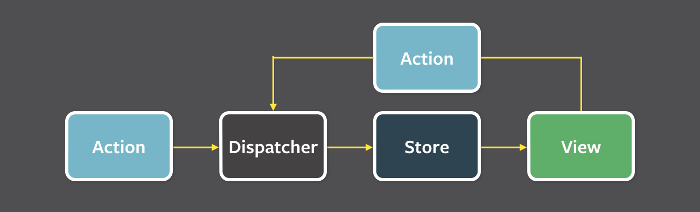
Flux 的最大特点,就是数据的"单向流动"。
- 用户访问 View
- View 发出用户的 Action
- Dispatcher 收到 Action,要求 Store 进行相应的更新
- Store 更新后,发出一个"change"事件
- View 收到"change"事件后,更新页面
上面过程中,数据总是"单向流动",任何相邻的部分都不会发生数据的"双向流动"。这保证了流程的清晰。
|
|
| |
|




React 动画库:react-motion
http://cexoso.github.io/cexoso/2017/10/08/read-react-motion/
spring 弹簧:
Fspring由劲度系数产生的力,Fdamper由阻尼产生的力。a为加速度,此处直接定义为两个力的和(假定质量为1了呗)。接着用积分的方法(假定了时间无穷小,其实一个时间片为1/60秒),算出新的速度和新的位置。并且如果速度和位置差在精度内就将速度置为0来结束运动。最后返回带有新位置和速度的tuple。
|
缓动函数
|
|
|
https://zhuanlan.zhihu.com/p/20458251
用这种方法有着显而易见的问题:
-
写 n 张页面页面渲染效率十分低下。
-
每次重新设置 body.innerHTML,性能太低了。
我们来逐个解决上述问题。
-
每一帧的界面都遵循一定的规律,相似性很高,中间必然有很多重复劳动。既然是重复劳动,我们可以放心的交给计算机去完成。写一个渲染函数,只需要向这个函数描述一下当前页面的信息,这个函数就能把页面给渲染出来。
-
可以用局部更新的方式来取代块更新,其中 React 的 Virtual DOM 更新方便地解决了这个问题。
我们再以一个左右切换的 toggle 动画为例,写一个渲染函数:
const render = x => `
<div class="toggle-slider">
<div class="toggle-box" style="transform: translate3d(${x}, 0, 0)">
</div>
`
有了这个函数之后,只需要告诉它 x 的当前值,新的页面就开始自动绘制了。由于 toggle 的运动规律,x 的值也不用手动依次给出,我们仍然可以写一个自动计算 x 的函数。这个自动计算 x 的函数,或者说计算页面状态的函数,就是缓动函数。
上述章节使用 setTimeout 来模拟时间的逝去,然而浏览器为动画过程提供了一个更为专注的 API -requestAnimationFrame。
raf 使用起来就像 setTimeout 一样,但有以下优点:
-
所有注册到 raf 中的回调,浏览器会统一管理, 在适当的时候一同执行所有回调。
-
当页面不可见,例如当前标签页被切换,隐藏在后面的时候,为了减少终端的损耗,raf 就会暂停。(如果像 jQuery 那样, 使用 setTimeout 实现动画,此时页面就会进行没有意义的重绘)。
raf 的这个特性,还可以利用在实时模块中,让标签页隐藏时停止发请求。
在开始使用 raf 前,我们需要一个 raf 的 polyfill ,比如 chrisdickinson/raf
然后,我们尝试用 React 和 raf 来重构一次 Toggle 动画。在数据上,用中介者模式实现一个简单的单向数据流:
动画是源自现实世界的,人类早已习惯了一个变速运动的物理环境,这样的一个匀速动画会让人相对感觉不适。
而从动画体验的角度来说,不同的缓动函数会带给用户不同的缓动体验。缓动体验一般为: 匀速缓动 < 变速缓动 < 物理缓动。
其中,spring 是最经典也是最常用的物理缓动。React Motion 就使用了这种物理缓动 —— 弹簧( spring )。
React Motion 缓动原理剖析
React Motion 使动画看起来像一个弹簧那样(一个有空气阻力的弹簧,如果没有空气阻力,弹簧就会不停地做简谐运动了)。大家可以尝试使用 React Motion 的spring-parameters-chooser,配置一个合适的劲度系数和空气阻力。弹簧动画可以使网站增添一些俏皮的元素,让用户体验起来更加舒畅!
下面就让我们进入主题,开始解读 React Motion 的缓动过程。
先模拟弹簧的物理规律,实现弹簧动画。
CSS 动画与 JS 动画
总的来说,使用 CSS 动画,能够得到更好的性能和更快的开发效率,然而 CSS 虽然更方便,但也必然有其做为 DSL 的局限性。例如:
1. 缓动函数单一(只有 cubic-bezier )
2. CSS 动画并不支持所有属性。例如 svg path 的 d 属性。
3. translate,rotate,skew 等都属于一个属性 —— transform。所以这些属性只能共用同一个缓动函数。(假如,我们想要动画的轨迹是一条贝塞尔曲线,可以通过给 translateX 和 translateY 这两个属性加两个不同的 cubic-bezier 缓动函数来实现,因此这就只能使用 JS 动画了)
(值得一提的是,CSS3 transition 的实现也使用了 raf 的机制,当标签页被切换时, transition 动画也会暂停,大家不妨试一试)
而 JS 动画刚好弥补了 CSS 动画的这些不足。
React 通过设置 state 让界面迅速发生变化,但动画的哲学告诉我们,变化要慢,得用一个逐渐变化的过程来过渡,从而帮助用户理解页面。
而界面的变化无非是 DOM 节点(或组件)的增与减和 DOM 节点(或组件)属性的变化。React 的 TransitionGroup 帮助我们便捷地识别 React 中的那些增加或删除的组件,从而让我们可以专注于更加简单的属性变化的动画。
|
|
|
https://threejs.org/examples/#webgl_animation_cloth
超多示例:
|
|
|
就三个公式:
F=ma
F拉=kl-F阻
a=(v1-v2)/(t1-t2)
哈哈哈~是不是笑了……高中的吗牛一定律,拉力公式,还有加速度~
React motion 库核心就是处理一个数值,目标元素做弹性运动!
佩服的是92的chenglou代码写的条理相当清楚,这个库值得读源码
|
|


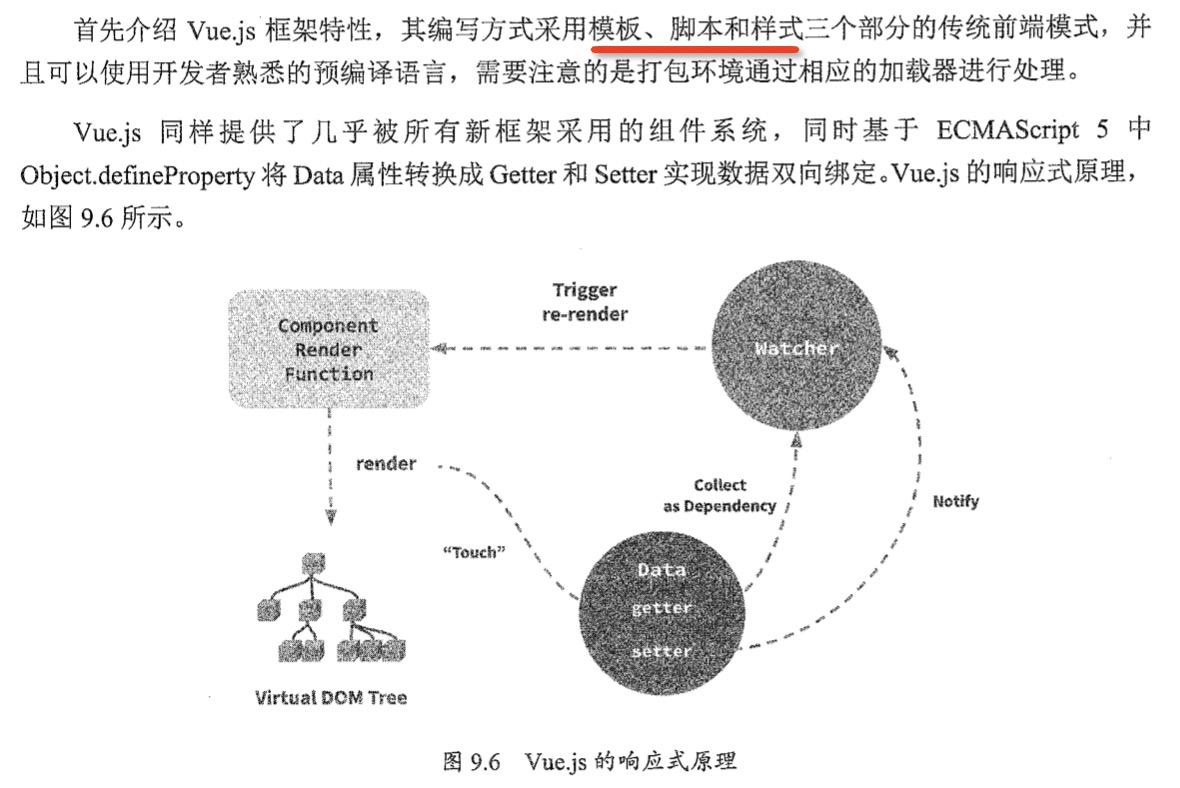
Vue的核心开发理念在于让开发者尽量避免对于DOM的直接操作,而采用直接操作数据;
基于数据的观察计算和绑定这些工作则由框架完成,Vue.js 对这些操作进行了大量的优化,2.0还引入了 Virtual DOM 来提高对DOM操作的性能

父子组件通信的方式:
vue的父子组件间通信可以总结成一句话:
父组件通过 prop 给子组件下发数据,子组件通过$emit触发事件给父组件发送消息,即 prop 向下传递,事件向上传递。
几种通信方式无外乎以下几种:
Prop(常用)$emit (组件封装用的较多).sync语法糖 (较少)$attrs & $listeners (组件封装用的较多)provide & inject (高阶组件/组件库用的较多)slot-scope & v-slot (vue@2.6.0+)新增scopedSlots 属性- 其他方式通信
作者:gongph 链接:https://juejin.im/post/5bd18c72e51d455e3f6e4334 来源:掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
|
|
|
$attrs 和 $listeners 属性像两个收纳箱,一个负责收纳属性,一个负责收纳事件,都是以对象的形式来保存数据
.sync 修饰符
这个家伙在 vue@1.x 的时候曾作为双向绑定功能存在,即子组件可以修改父组件中的值。因为它违反了单向数据流的设计理念,所以在 vue@2.0 的时候被干掉了。但是在 vue@2.3.0+ 以上版本又重新引入了这个 .sync 修饰符。但是这次它只是作为一个编译时的语法糖存在。它会被扩展为一个自动更新父组件属性的 v-on 监听器。说白了就是让我们手动进行更新父组件中的值了,从而使数据改动来源更加的明显。下面引入自官方的一段话:
在有些情况下,我们可能需要对一个 prop 进行“双向绑定”。不幸的是,真正的双向绑定会带来维护上的问题,因为子组件可以修改父组件,且在父组件和子组件都没有明显的改动来源。
5. provide & inject
他俩是对CP, 感觉挺神秘的。来看下官方对 provide / inject 的描述:
provide 和 inject 主要为高阶插件/组件库提供用例。并不推荐直接用于应用程序代码中。并且这对选项需要一起使用,以允许一个祖先组件向其所有子孙后代注入一个依赖,不论组件层次有多深,并在起上下游关系成立的时间里始终生效。
看完描述有点懵懵懂懂!一句话总结就是:小时候你老爸什么东西都先帮你存着等你长大该娶媳妇儿了你要房子给你买要车给你买只要他有的尽量都会满足你。
|
|
9.4 单页应用SPA


优点:
1、分离前后端关注点,前端负责界面显示,后端负责数据存储和计算,各司其职,不会把前后端的逻辑混杂在一起;
2、减轻服务器压力,服务器只用出数据就可以,不用管展示逻辑和页面合成,吞吐能力会提高几倍;
3、同一套后端程序代码,不用修改就可以用于Web界面、手机、平板等多种客户端;
缺点:
1、SEO问题,现在可以通过Prerender等技术解决一部分;
2、前进、后退、地址栏等,需要程序进行管理;
3、书签,需要程序来提供支持;
作者:clia
链接:https://www.zhihu.com/question/20792064/answer/22784862
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【大拿分享】单页应用(Single Page Application)的搜索引擎优化
发布日期:2015-03-11
单页应用并不是一个全新发明的技术,而是随着互联网的发展,越来越受web开发者欢迎,单页应用的体验可以模拟原生应用,一次开发,多端兼容,效果酷炫,节省成本。然而,由于单页应用基本全部使用JS,受制于SEO效果,目前国内使用单页应页技术的网站还是少之又少。在已知使用单页应用的站点中,携程旅行的SEO效果一直不错,那么今天,我们请携程旅行SEO技术负责人安琦老师为我们分享了单页应用SEO解决四大方案,其中第四套是目前携程旅行采用的技术方案,监控数据表明效果符合预期:
一、单页应用?此SPA不是彼SPA…
我们所说的“单页应用”都为Single Page Application的直译,基本市面上“单页面应用”、“One Page Application”、“SPA”及某些语境下的“webapp ” 都是指这一类移动站点。
那么典型的SPA是什么样子?我们用手机看看这条URL,http://cc-ng-z.azurewebsites.net/,可以衍生想象一下乘以N倍的:切换页面无需加载的效果,HTML和JS无法比拟的动画,以及对原生APP的追求……
*案例采用了angularJS这个鼎鼎大名的框架
二,高科技永远连累我们干苦力的
为什么这么写,因为SPA对SEO损伤很大,非常大。
优点当然毋庸置疑:效果酷炫,我在视觉和产品面前无从反驳;性能高速度快,全JS嘛当然快,我在运维和产品面前无言以对;运算分散,异步加载,又省硬件又省流量,我在开发和产品面前彻底投降;JS前后端,一个人干一个站的活儿——关于这一点,我在老板、HR和产品面前哭的像一个孩子。总之,在各路人马的一番碾压后,我手里的网站改版了,一个SPA诞生了。
问题接踵而来:我发现所有页面都变成了全JS生成;所有URL中参数前面都被#分割;第三方统计系统无法再正常工作;PC和移动的适配正则全部失效了;所有人都高兴了,只有你,做SEO的、做网站优化的,欲哭无泪。
实际上我观察下来,只要使用了SPA架构的站点或多或少收到伤害,当看到有些大站点没做处理,只有可能搜索对于他们是个微不足道的渠道,比如锤子手机官网甚至不可思议地在PC站点上使用了类似架构,我相信他们的索引是有点问题的。这让我想到知乎上一个问题,说AMAZON的URL那么乱(当时)是因为他们不注重SEO吗?答案是不是,是他们更注重tracking。同理,SPA带来的优点胜过SEO,我被PK掉了。
三,求人不如求己
在SPA项目面前,我发现我被放在了所有人的对立面,无法抗拒这种时髦架构的上线,当然不得不说效果确实比WAP即视感的站点高端和好用太多,不要螳臂当车逆历史车轮而动。既然反抗也很痛,那么享受吧!我知道,我还和搜索引擎在一起;老板要的是解决方案,当然回滚这种方案会让我先滚。

让我们看看一个典型的SPA网站架构,和传统的服务端生成内容不同,在传统的网站,当你发起请求的时候,页面的组装是在服务器上完成的,反馈给浏览器的是已经完成组装的HTML内容;而之于SPA,服务端负责了数据和素材的存储,页面的逻辑执行和组装是在浏览器上通过Javascript完成和呈现的,这也就意味着,SPA不需要请求→接受、请求→接受、请求→接受、请求→接受这样玩了。完全凭借本地数据,即可完成基本的页面请求和访问。
基于此,当某人需要像APP那样切换页面但不刷新,并要在此基础上做文章时,#(井号)这个奇葩的符号粉墨登场,完成了“又要本地传输数据又不需要刷新页面”这个奇葩需求的历史任务,给单页应用的可抓取性重重一击。整个SPA的网站,URL不可抓取,页面内容不可抓取,糟透了。
解决思路倒也简单,围绕全JS和URL可用解决问题。
【方案一:尽人皆知的Google抓取AJAX方案】
如何让搜索引擎抓取AJAX内容?
A proposal for making AJAX crawlable
Google给了官方指导,并在Twitter上做了个最大的case,但后来T家放弃了,我想更多是T战略上的放弃。腾讯的ISUX博客上也曾经推广过这种方式,居然是在2014年,如下文:单页应用的SEO浅谈
总的来说,这种方案可以兼容Google,如果资源实在有限,有着能抓多少是多少的心态,可以试试。主要不幸的是,5年前Google已和我们再见了
【方案二:再做一个服务端生成内容的镜像网站】
说实话,量级不大的网站并且极度依赖搜索引擎这个渠道的情况下,这不失为一种方案,第一,蜘蛛绝对可抓取;第二,URL规则的完全可控(要知道现在流行的路由方式,在配置URL规则上相对于URLrewrite是有天生缺陷的);第三,SPA模式URL衍生的所有问题不再是问题。
但是面临的问题也令我望而却步:我要说服team再维护一个一模一样的网站,不是做完了事,是维护,这意味着修Bug要有资源修,改版要有资源改(能说服自己搜索进来然后点两下看到的网站不一样吗?)、所有相关功能的测试、发布、常规测试,都要耦合在一起,当站点大到一定程度,流程前所未有地臃肿,推进无休止的争吵,所有烦恼包围着我,让我想静静。我预计自己会累垮,即使搞定了所有的资源,网站优化人员自身也将面临着非常繁重的工作,两个网站怎么融合,适配跳转怎么设定,是否需要主动判断蜘蛛展现不同的内容,内链入口怎么放,都是耦合,且是硬耦合,网站大了页面多了,越做耦合越多,以后一碰就是坑。
【方案三:HTML5 history 中的PushState】
还好,开发大大们总是不少奇巧淫技,这是个很”经典”的用法,配合<noscript>这个擦边球标签,既能实现URL的自定义,又能实现还算有效果的内容抓取。蜘蛛、浏览器,两方应对,给蜘蛛不带井号能抓取的URL,给浏览器访问非井号URL时中间做转换,这样的话每张页面都有了可抓取的URL,且依然使用着高逼格的SPA架构。内链可以做了,Sitemap可以做了,适配也轻松了。
但实际上,蜘蛛在这种页面上还是盲的,所有内容要仰仗于noscript这个标签里塞的数据,以及搜索引擎对这个标签的支持程度。

做到这一步,单就需求而言,搜索引擎的抓取从HTML规范讲完成了,但这种方式没有任何搜索承认过支持,包括最核心的那个对于noscript标签的支持。
【方案四:用更高效的方式完成两套页面】
再回到那个简单的架构图,SPA这种架构,渲染是在客户端(浏览器)完成的,大致流程如下:

蜘蛛无法执行JS,相应的页面内容无从抓取,弊端还是那个弊端。但我们知道,传统的服务端生成页面,response里已经是服务器渲染组装好的HTML代码,浏览器只负责正确地展现,蜘蛛负责正确的解析,所以,我们需要给蜘蛛渲染完成的HTML,那么你的框架需要兼容如下流程的功能。

我们看到,当访问为SEO所需页面的时候,数据传输到了SEO 服务器完成渲染和组装然后吐给浏览器和蜘蛛,那么蜘蛛拿到的即是完全可见且融合了SPA的页面——landing页都是蜘蛛可见的,接下去用户的点击都是SPA的页面。
需要注意的是,如果你是用URL来区分SPA架构与否,那么内链及入口要全部使用SEO URL,只为用户暴露SPA的链接,JS在这里阴差阳错地成为了优势,那些SPA的链接将比较难被抓取的。
其实可以不使用URL来区分,延伸想想。这样一个流程,也无多少高精尖元素,其实只是“依照条件”增加了一个服务端自动渲染的步骤,在架构方案上再细细夯实,可以实现一套代码两处运行、SEO页面可单独自定义功能、、同一张landing人和蜘蛛没有跳转,没有区别对待、全栈工程师的大量使用、SEO页面永远保持最新版等等省时省力的需求功能。
总之,如果你和我一样,有文章前面部分的抱怨,SPA架构势在必行,两套页面改版不能同步,单独多做一套可抓取页面没有太多资源投入,与此同时还是想以比较保守的方式给蜘蛛展现网站的内容,那么这个思路可以考虑,然后为自己量身定做。
关于单页应用的网站优化,在实践中我所经历过的这些吧。优化不是按部就班,作为从业人员要审时度势地采取不同方案,以结果为导向,上不了线,再好的优化也是个方案。
相关内容讨论请移步【学院同学汇】《单页应用(Single Page Application)的搜索引擎优化》讨论帖
|
|
| |
|
