最前沿:深度解读Soft Actor-Critic 算法
1 前言
机器人学习Robot Learning正在快速的发展,其中深度强化学习deep reinforcement learning(DRL),特别是面向连续控制continous control的DRL算法起着重要的作用。在这一领域中,目前可以说有三类行之有效的modle free DRL算法:
- TRPO,PPO
- DDPG及其拓展(D4PG,TD3等)
- Soft Q-Learning, Soft Actor-Critic
PPO算法是目前最主流的DRL算法,同时面向离散控制和连续控制,在OpenAI Five上取得了巨大成功。但是PPO是一种on-policy的算法,也就是PPO面临着严重的sample inefficiency,需要巨量的采样才能学习,这对于真实的机器人训练来说,是无法接受的。
DDPG及其拓展则是DeepMind开发的面向连续控制的off policy算法,相对PPO 更sample efficient。DDPG训练的是一种确定性策略deterministic policy,即每一个state下都只考虑最优的一个动作。DDPG的拓展版D4PG从paper中的结果看取得了非常好的效果,但是并没有开源,目前github上也没有人能够完全复现Deepmind的效果。
Soft Actor-Critic (SAC)是面向Maximum Entropy Reinforcement learning 开发的一种off policy算法,和DDPG相比,Soft Actor-Critic使用的是随机策略stochastic policy,相比确定性策略具有一定的优势(具体后面分析)。Soft Actor-Critic在公开的benchmark中取得了非常好的效果,并且能直接应用到真实机器人上。最关键的是,Soft Actor-Critic是完全开源的,因此,深入理解Soft Actor-Critic 算法具有非常重要的意义,也是本篇blog的目的。
Soft Actor-Critic算法相关链接:
Paper:
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Reinforcement Learning with Deep Energy-Based Policies (Soft Q-Learning)
Codes:
下面我们来详细解读一下SAC的算法及其具体实现。本文的阅读需要有基本的DRL算法基础知识。
2 为什么研究 Maximum Entropy Reinforcement Learning?
对于一般的DRL,学习目标很直接,就是学习一个policy使得累加的reward期望值最大:
(1)
而最大熵RL,除了上面的基本目标,还要求policy的每一次输出的action 熵entropy最大:
(2)
这样做的基本目的是什么呢?让策略随机化,即输出的每一个action的概率尽可能分散,而不是集中在一个action上。不了解entropy的同学可以看这里:wiki-信息熵
我们知道DDPG训练得到的是一个deterministic policy确定性策略,也就是说这个策略对于一种状态state只考虑一个最优的动作。所以,stochastic policy相对deterministic policy有什么优势呢?
Stochastic policy随机策略在实际机器人控制上往往是更好的做法。比如我们让机器人抓取一个水杯,机器人是有无数条路径去实现这个过程的,而并不是只有唯一的一种做法。因此,我们就需要drl算法能够给出一个随机策略,在每一个state上都能输出每一种action的概率,比如有3个action都是最优的,概率一样都最大,那么我们就可以从这些action中随机选择一个做出action输出。最大熵maximum entropy的核心思想就是不遗落到任意一个有用的action,有用的trajectory。对比DDPG的deterministic policy的做法,看到一个好的就捡起来,差一点的就不要了,而最大熵是都要捡起来,都要考虑。
基于最大熵的RL算法有什么优势?
以前用deterministic policy的算法,我们找到了一条最优路径,学习过程也就结束了。现在,我们还要求熵最大,就意味着神经网络需要去explore探索所有可能的最优路径,这可以产生以下多种优势:
1)学到policy可以作为更复杂具体任务的初始化。因为通过最大熵,policy不仅仅学到一种解决任务的方法,而是所有all。因此这样的policy就更有利于去学习新的任务。比如我们一开始是学走,然后之后要学朝某一个特定方向走。
2)更强的exploration能力,这是显而易见的,能够更容易的在多模态reward (multimodal reward)下找到更好的模式。比如既要求机器人走的好,又要求机器人节约能源
3)更robust鲁棒,更强的generalization。因为要从不同的方式来探索各种最优的可能性,也因此面对干扰的时候能够更容易做出调整。(干扰会是神经网络学习过程中看到的一种state,既然已经探索到了,学到了就可以更好的做出反应,继续获取高reward)
既然最大熵RL算法这么好,我们当然应该研究它了。而实际上,在之前的DRL算法A3C中,我们其实已经用了一下最大熵:

在训练policy的时候,A3C加了entropy项,作为一个regularizer,让policy更随机。不过A3C这么做主要是为了更好做exploration,整体的训练目标依然只考虑reward。这和Soft Actor-Critic的设定还是不一样的,Soft Actor-Critic是真正最大熵DRL算法。
3 Maximum Entropy Reinforcement Learning的Bellman方程
我们先回顾一下dynamic programming中Bellman backup equation,参考http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/MDP.pdf
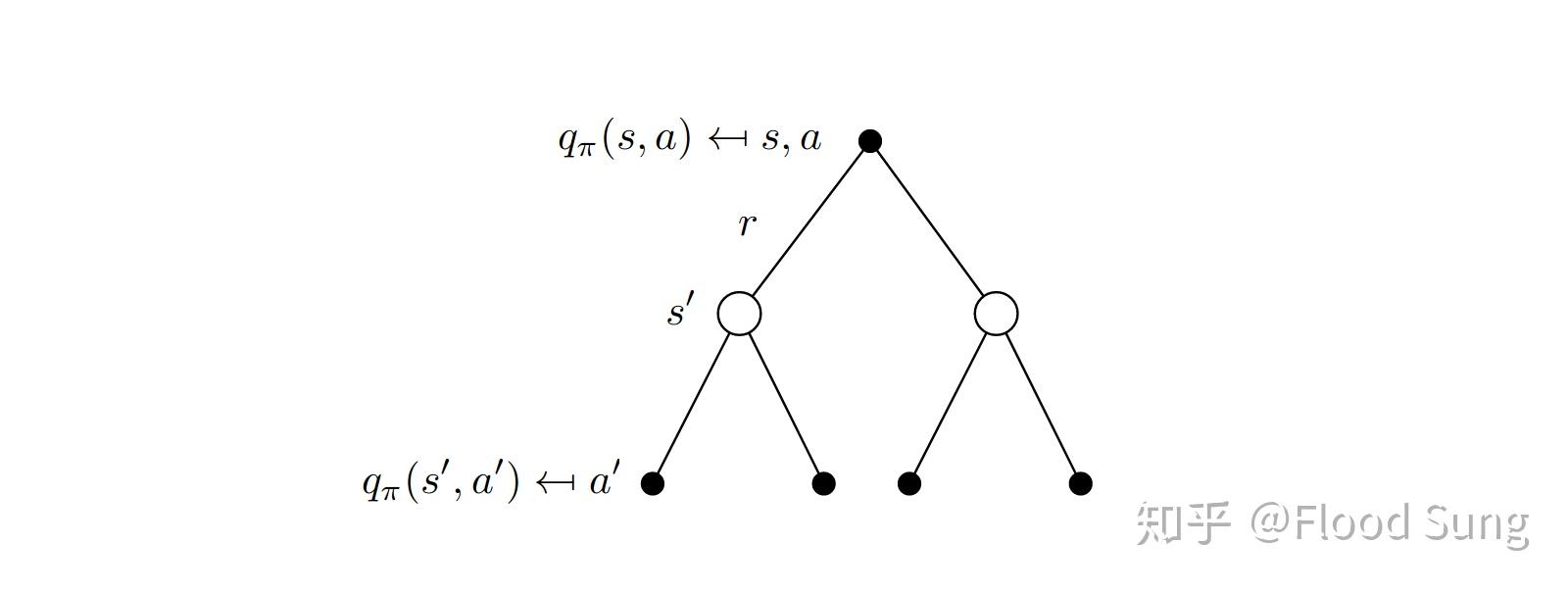
(3)
那么对于最大熵(MaxEnt)的目标,其实可以把熵也作为reward的一部分,我们在计算q值时(记住q是累加reward的期望,传统rl的目标等价于让q最大),就需要计算每一个state的熵entropy (entropy的公式如下图所示):

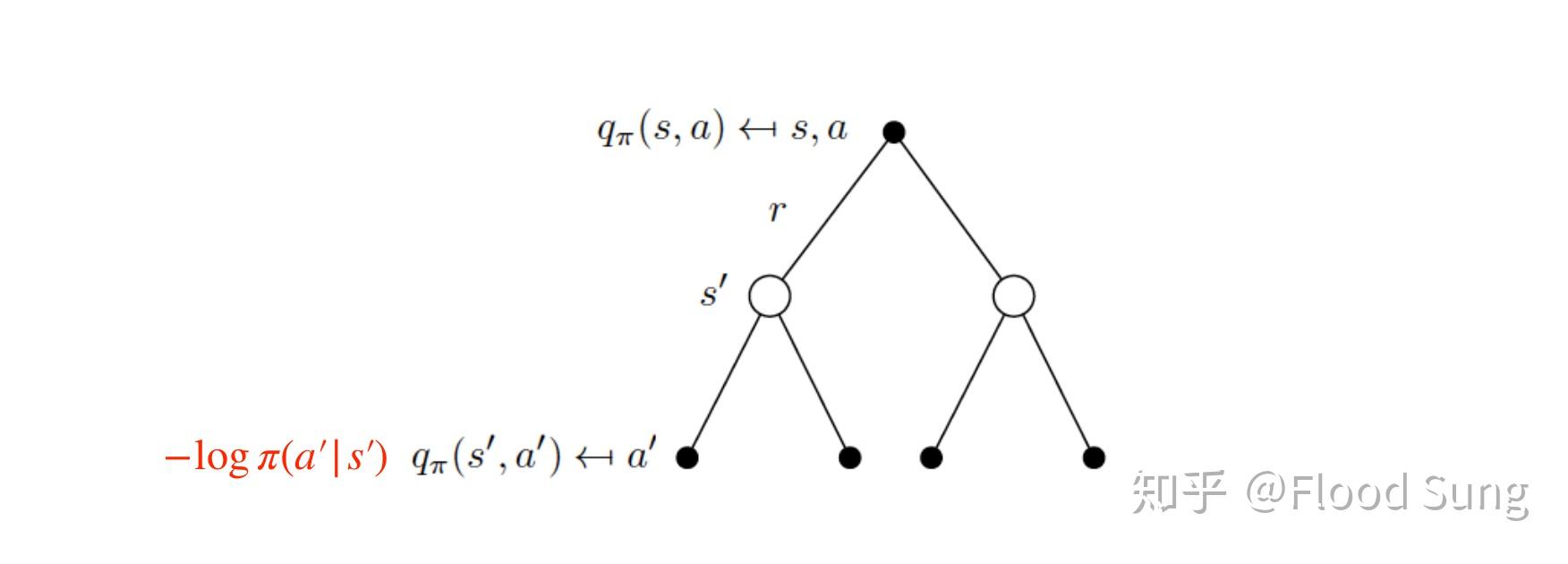
因此我们就可以得到Soft Bellman Backup equation (Entropy项额外乘上 系数:
(4)
Recall一下Dynamic Programming Backup:
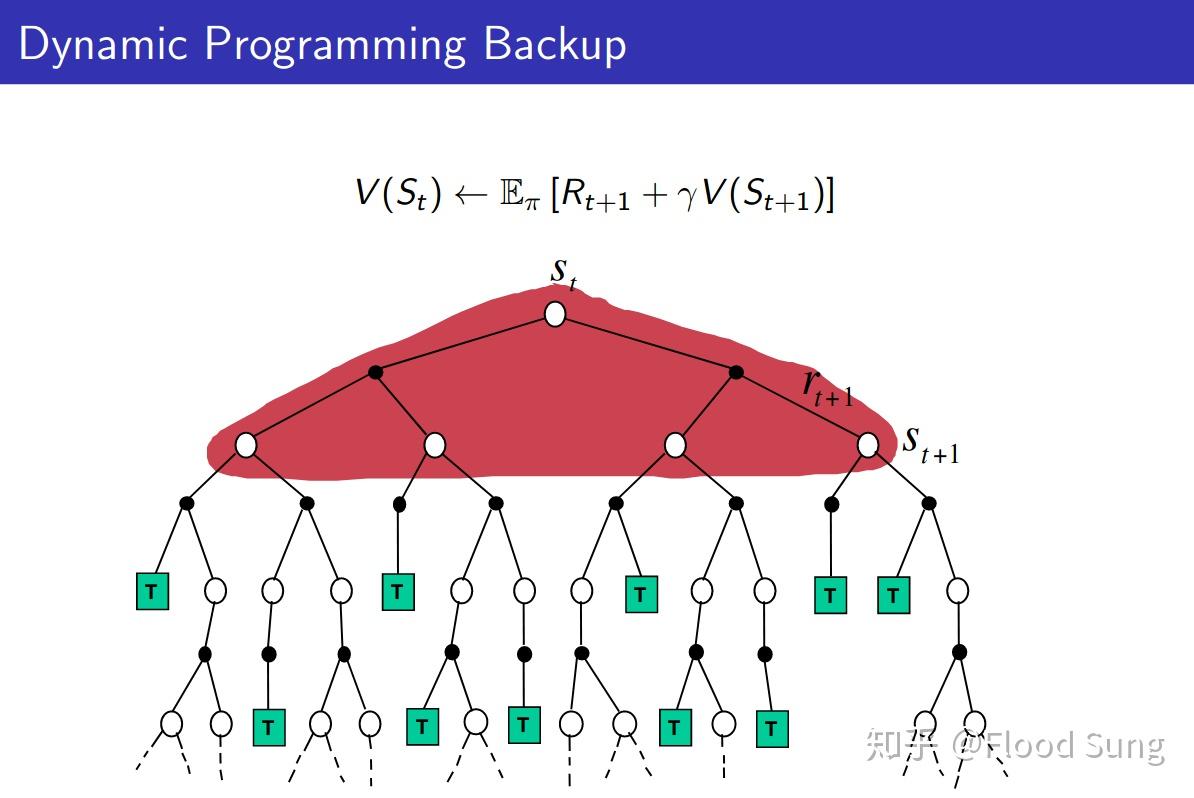
对应Q值的公式是
(5)
根据公式(4),我们可以得到Soft Bellman Backup的 更新公式:
(6)
上面公式(6)是直接使用dynamic programming,将entropy嵌入计算得到的结果。我们可以反过来先直接把entropy作为reward的一部分:
(7)
我们将(7)带入到公式(5):
(8)
可以得到一样的结果。
与此同时,我们知道:
(9)
因此,我们有:
(10)
至此我们理清楚了SAC paper原文中的公式(2)和(3):

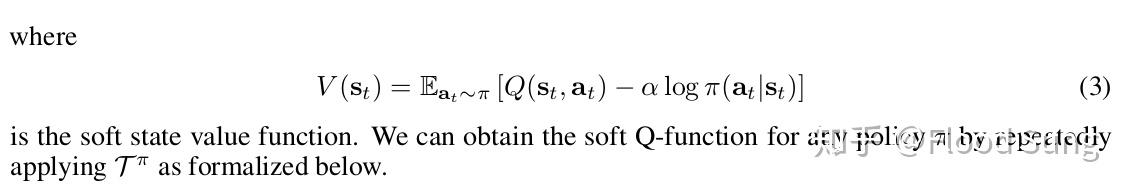
并且(7)的做法直接证明了Lemma 1 Soft Policy Evaluation (这个lemma为下一部分的soft policy iteration提供支撑):

但是,我们注意到上面的整个推导过程都是围绕maximum entropy,和soft 好像没有什么直接关系。所以,
为什么称为soft?哪里soft了?以及为什么soft Q function能够实现maximum entropy?
理解清楚这个问题是理解明白soft q-learning及sac的关键!
SAC这篇paper直接跳过了soft Q-function的定义问题,因此,要搞清楚上面的问题,我们从Soft Q-Learning的paper来寻找答案。
参考Learning Diverse Skills via Maximum Entropy Deep Reinforcement Learning
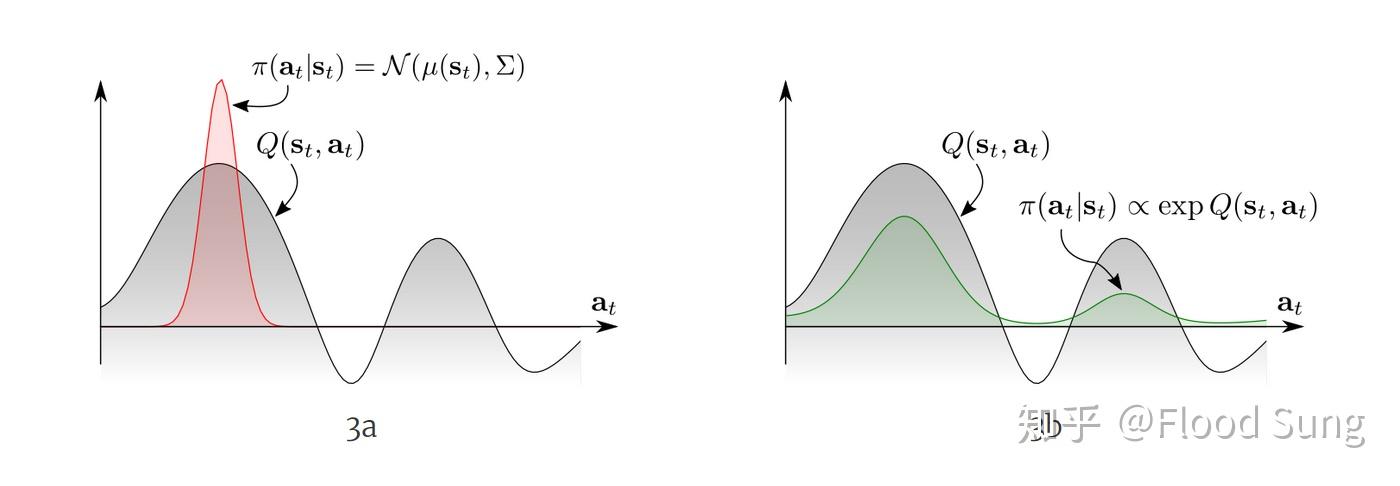
上面的曲线很明显的说明了stochastic policy的重要性,面对多模的(multimodal)的Q function,传统的RL只能收敛到一个选择(左图),而更优的办法是右图,让policy也直接符合Q的分布。这里,最直接的一种办法就是定义这样的energy-based policy:
(11)
其中 是能量函数,上面的形式就是Boltzmann Distribution 玻尔兹曼分布 。下图的
 https://deepgenerativemodels.github.io/assets/slides/cs236_lecture13.pdf
https://deepgenerativemodels.github.io/assets/slides/cs236_lecture13.pdf
为了连接soft Q function,我们可以设定
(12)
因此,我们有
(13)
这样的policy能够为每一个action赋值一个特定的概率符合Q值的分布,也就满足了stochastic policy的需求。
下面我们要发现(13)的形式正好就是最大熵RL的optimal policy最优策略的形式,而这实现了soft q function和maximum entropy的连接。
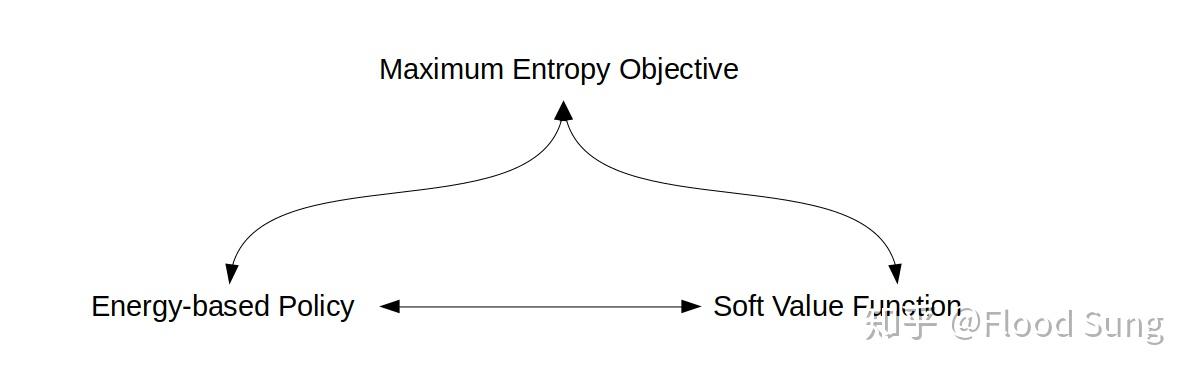
实际上我们理解Soft Q-Learning及Soft Actor Critic,要清楚上图三者的关系。在Soft Q-Learning那篇paper中,他是从Soft Value Function的定义出发去连接Energy-Based Policy 和Maximum Entropy Objective的关系。而在本blog中,我们从Maximum Entropy Objective出发,来连接其他两部分。
前面我们已经推导得到了公式(10),那么根据公式(10),我们可以直接推导得到policy的形式:
(14)
(14)符合了(13), 可以看做是对应的log partition function. 由此,就连接了Maximum Entropy Objective和Energy Based Policy的关系。
下面我们要连接Soft Value Function。从(14)的 已经很明显了:
(15)
因此,我们可以定义 :
(16)
这和soft 有什么关系呢?(16)其实是LogSumExp的积分形式,就是smooth maximum/soft maximum (软的最大)。参考https://en.wikipedia.org/wiki/LogSumExp
所以就可以定义
(17)
因此我们也就可以根据公式(9)定义soft的Q-function:
(18)
所以,为什么称为soft是从这里来的。
这里有一个常见的疑问就是这里的soft max和我们常见的softmax好像不一样啊。是的,我们在神经网络中常用的activation function softmax 实际上是soft argmax,根据一堆logits找到对应的软的最大值对应的index。具体参看:https://en.wikipedia.org/wiki/Softmax_function
上面的推导还只是面向policy的value和Q,我们下面要说明optimal policy也必然是energy-based policy的形式。
这一部分的证明依靠 Policy improvement theorem:
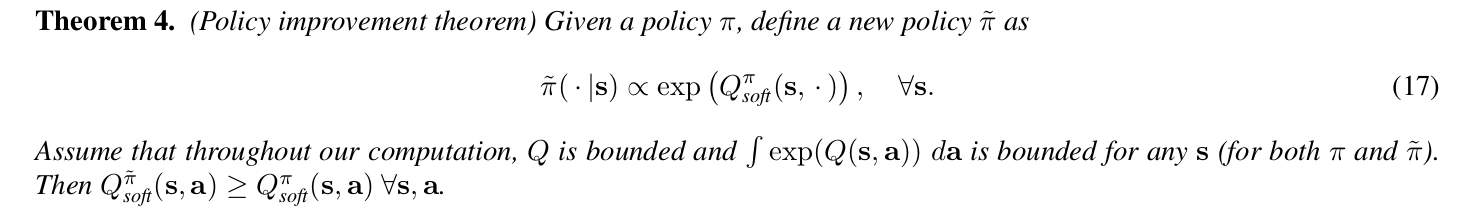
具体证明过程见soft q-learning原文的A.1。
有了Theorem 4,

我们就可以看到optimal policy必然是energy based policy,也因此,我们有了soft q learning paper中最开始的定义:
(19)
4 Policy Iteration
理清楚了上面的基本定义和联系,我们就可以研究怎么更新policy了,也就是policy iteration。
回顾一下一般的Policy Iteration:
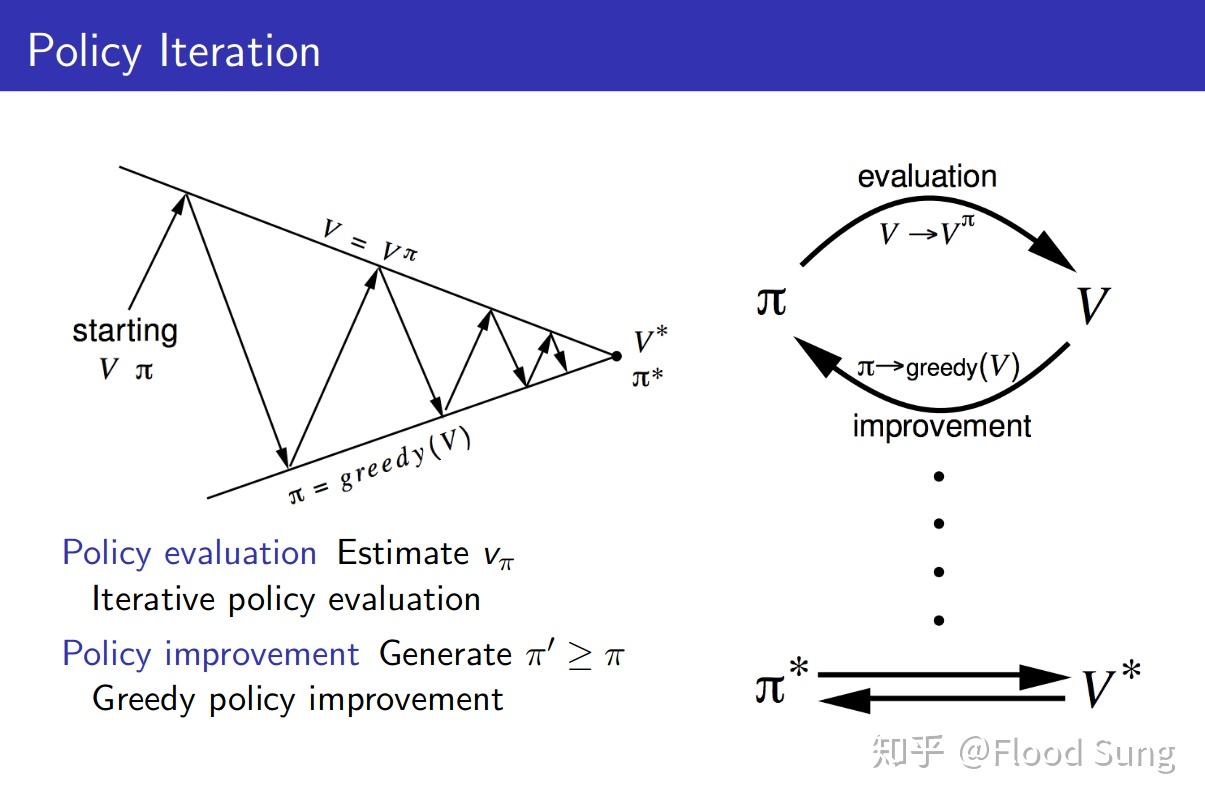
在两步中进行循环迭代(我们直接使用Q值来说明):
- Policy evaluation:固定policy,使用Bellman方程更新Q值直到收敛:
(20)
2. Policy improvement: 更新policy:
(21)
基于同样的方法,我们有Soft Policy Iteration:
- Soft policy evaluation:固定policy,使用Bellman方程更新Q值直到收敛:
(22)
2. Soft policy improvement: 更新policy:
(23)
(22)基于上一部分说的Lemma 1 Soft Policy Evaluation, 可收敛。
(23)则基于上一部分的Theorem 4 Policy Improvement Theorem。只是这里的做法不是直接赋值,而是通过KL divergence来趋近 。在SAC的paper原文中,我们可以看到这么做的原因是为了限制policy在一定范围的policies
中从而tractable,policy的分布可以是高斯分布。

同样的,作者也专门证明了采用KL divergence的方法一样能够保证policy improvement,也就是Lemma 2:
最后,就是证明上面的Soft Policy Iteration过程能保证policy收敛到最优,即Theorem 1:

由此,基本的理论建设也就结束了,下面进入Soft Actor-Critic的算法设计。
5 Soft Actor-Critic
SAC算法的构建首先是神经网络化,我们用神经网络来表示Q和Policy: 和
。Q网络比较简单,几层的MLP最后输出一个单值表示Q就可以了,Policy网络需要输出一个分布,一般是输出一个Gaussian 包含mean和covariance。下面就是构建神经网络的更新公式。
对于Q网络的更新,我们根据(10)可以得到:
(24)
这里和DDPG一样,构造了一个target soft Q 网络带参数 ,这个参数通过exponentially moving average Q网络的参数
得到。(ps:在第一个版本的SAC中,他们单独定义了V网络进行更新,说是更稳定,到新版的SAC中,由于自动更新temperature
就直接使用Q网络更新)
对于Policy 网络参数的更新,就是最小化KL divergence:
(25)
这里的action我们采用reparameterization trick来得到,即
(26)
f函数输出平均值和方差,然后 是noise,从标准正态分布采样。使用这个trick,整个过程就是完全可微的(loss 乘以
并去掉不影响梯度的常量log partition function
:
(27)
这样基本的Soft Actor-Critic的更新方法也就得到了。
6 Temperature Hyperparameter Auto-Adjustment
前面的SAC中,我们只是人为给定一个固定的temperature 作为entropy的权重,但实际上由于reward的不断变化,采用固定的temperature并不合理,会让整个训练不稳定,因此,有必要能够自动调节这个temperature。当policy探索到新的区域时,最优的action还不清楚,应该调到temperature 去探索更多的空间。当某一个区域已经探索得差不多,最优的action基本确定了,那么这个temperature就可以减小。
这里,SAC的作者构造了一个带约束的优化问题,让平均的entropy权重是有限制的,但是在不同的state下entropy的权重是可变的,即
(28)
对于这部分内容,Policy Gradient Algorithms 这个openai小姐姐的blog介绍得极其清楚,大家可以参考,最后得到temerature的loss:
(29)
由此,我们可以得到完整的Soft Actor-Critic算法:

为了更快速稳定的训练,作者引入了两个Q网络,然后每次选择Q值小的一个作为target Q值。更新Q,Policy及 使用上文的(24)(27)(29)三个公式。
7 神经网络结构
虽然上面把算法流程确定了,但是如何构造policy的神经网络还是比较复杂的。下图是带V网络的神经网络结构图:
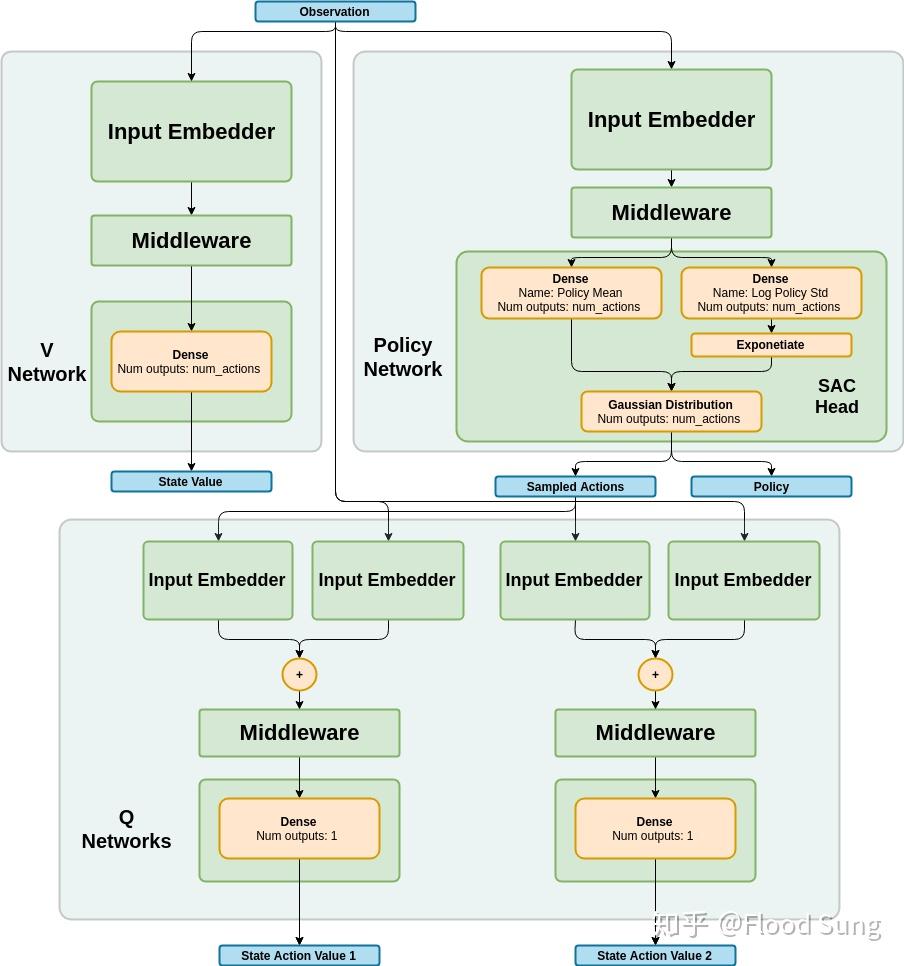 https://nervanasystems.github.io/coach/components/agents/policy_optimization/sac.html
https://nervanasystems.github.io/coach/components/agents/policy_optimization/sac.html
我们主要来探究一下Policy网络的设计。
见上图右上角的Policy网络,前面的input embedder和Middleware不用说,就是几层的MLP。然后,接下来神经网络分成两个分支,分别输出平均值mean 和log 标准差 log std 。然后使用exp得到std。
(30)
正常输出这样的高斯分布作为action 的分布distribution是OK的,但是在实际中,这个action需要限定在一定范围内。因此,这里作者使用了squashing function tanh,将action限制在(-1,1)之间,即
(31)
这里和上文的公式(26)对应,多了一个tanh。
那么这会导致分布的变化,从而影响log likelihood的计算,而这是我们计算SAC的loss必须的。作者在paper中给出了计算方法如下:
(32)
其中 是
的第i个元素。这里的
是没有加限制时的likelihood function也就是高斯分布的likelihood function似然函数。高斯分布的log likelihood直接使用pytorch的Normal class就可以获得。
8 其他细节
1)SAC里的target entropy 设计为
(33)
即-动作数量。
2)SACpaper里完全没有说明的训练时的episode设置。SAC设置为每一个episode采样1000次然后训练1000次。
3)在代码中SAC使用 log alpha作为更新的参数,而不是直接使用alpha如公式(25),这和输出log std是一样的,使用log有很大的正负范围,更方便网络输出。否则alpha或者std都是正值。
4)SAC有一个很大的问题,它的policy的目的是趋近于玻尔兹曼分布,但是实际实现的时候,为了能够tractable,选择了输出一个高斯,也就是让高斯趋近于玻尔兹曼分布。这意味着SAC本质上还是unimodal的算法,而不是soft q-learning的multi-modal。这使得SAC的创新性打了很大的折扣。但是算法效果确实还是不错的。
9 小结
本文从理论到具体实现层面剖析了Soft Actor-Critic这一目前极强的DRL算法,基本上理解了本文的分析,对于代码的实现也就可以了然一胸了。
由于本人水平有限,前面的理论分析恐有错误,望批评指正!
最后,欢迎有志于实现决策智能及机器人革命的朋友加入 启元世界!
联系方式:hr@inspirai.com