图网络学习算法——从GraphSAGE,GAT到H-GCN
- GraphSAGE
论文:InductiveRepresentationLearningonLargeGraphs
作者:WilliamL.Hamilton, RexYing, JureLeskovec
来源:NIPS 2017
Motivation:
图网络内节点表达的学习,已在多项任务中被证明了其实用性,如传统的Deepwalk、semi-GCN等方法。但是,目前大多数已存在的方法,在训练过程中都仅仅考虑当前的节点,学习目标也是直接生成当前节点的embedding,而对未知的节点,并不能起到泛化的作用。也就是说,目前的大部分方法,都是transductive式学习。
为了解决对未知节点的泛化问题,本文提出了GraphSAGE的方法,它采用的是inductive的学习模式,在GCN基础上,通过训练聚合邻居节点的函数,使得GCN扩展成inductive学习的任务,对未知节点起到泛化作用。
Method:
该方法的核心为如何聚合邻居节点的特征信息。

1)首先对目标节点进行随机邻居采样,其目的是降低计算的复杂度。
2)然后根据前向传播,生成目标节点的embedding,(以深度K=2为例):先聚合2跳的邻居特征,来生成1跳邻居的embedding;再聚合1跳邻居的特征,生成目标节点的embedding。具体过程为:针对目标节点v,聚合与节点v相连的邻居(k-1)层embedding,得到第k层邻居聚合特征;该特征与v节点的k-1层embedding 拼接,作为全连接网络的输入,进而去实现下游的预测任务。
3)聚合函数部分,本文介绍了3种不同的聚合方法,包括:平均聚合,LSTM聚合以及pooling聚合:
a.平均聚合:先对邻居embedding中每个维度取平均,然后与目标节点embedding拼接后进行非线性转换。
改进版的平均聚合是采用GCN的卷积层方法,直接对目标节点和所有邻居embedding中每个维度取平均,后再非线性转换。

b. LSTM聚合:由于LSTM不符合“排序不变量”的性质,需要先对邻居随机排序,然后将随机的邻居序列embedding 作为LSTM输入。
c. Pooling聚合:先对每个邻居节点k-1层embedding进行非线性转换,再按维度应用 max/mean pooling,捕获邻居集上在某方面的突出的/综合的表现,以此表示目标节点的邻居聚合embedding。
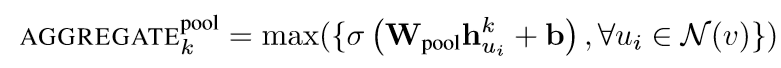
4) 损失函数部分,分别有基于图的无监督的损失函数,以及有监督的损失函数。
a. 无监督:节点u与邻居节点v的embedding相似,而与“没有交集”的节点vn(随机负采样得到)不相似。

b. 有监督:节点分类任务常用的交叉熵。
其他思考:
1) 该方法在聚合邻居特征过程中,聚合函数相当于对每个邻居节点采用了相同的贡献度,但不同的邻居节点可能具有不同的重要性程度,可采用Attention机制来学习这一贡献度(下一篇的GAT就是这个意思)。
2) 本文仅采用了K=2的深度,即仅仅聚合了二跳邻居节点的信息,不能更好的把握全局的信息,这也是后面可以深入思考与改进的一个点。
2. GAT
论文:GRAPH ATTENTION NETWORKS
作者:PetarVeliˇckovi´, GuillemCucurull, ArantxaCasanova, AdrianaRomero, PietroLi` , YoshuaBengio
来源:ICLR 2018
Motivation:
如上一篇的思考1)中提到的,在聚合邻居节点过程中,将其都视作相同的贡献度有些粗糙与不合理,因此本文引入注意力机制到图神经网络中,每一层学习节点的每个邻居对其生成新的特征的贡献度,按照贡献度大小对邻居特征进行聚合,以此来生成新的聚合特征,供下游任务使用。
Method:
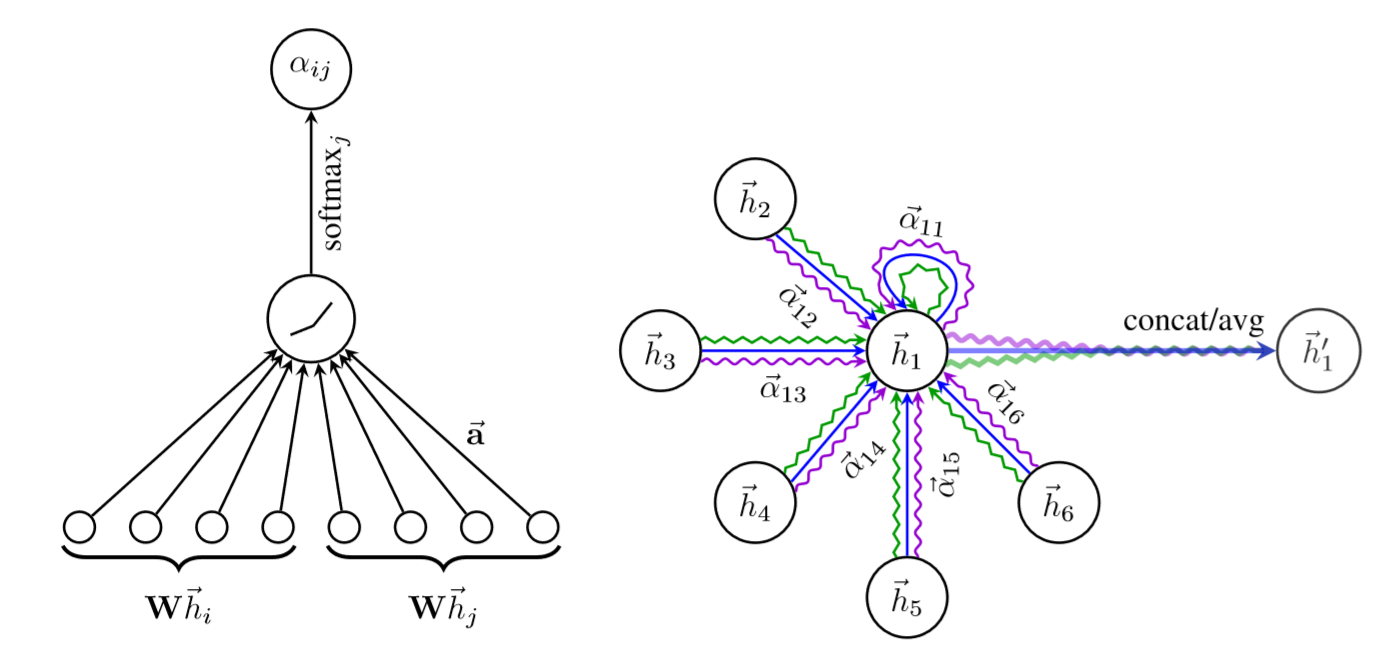
1) 输入为目标节点i的特征hi,与其邻居节点j的特征hj。
2) 首先对个节点特征与共享权重矩阵W相乘,做线性变换,得到Whi,Whj(这里做线性变换类似深度神经网络的思想,得到更强大的表达)。
3) 将两个线性变换后的向量做拼接,并与共享的attention参数相乘,得到节点j对节点i的贡献性程度。
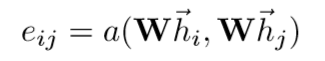
4) 针对所有的邻居节点j,利用softmax进行归一化,得到每个邻居节点j对i的贡献性权重。

本文中实际应用中,采用LeakyRelu对节点向量进行非线性激活,最终的贡献性权重为:
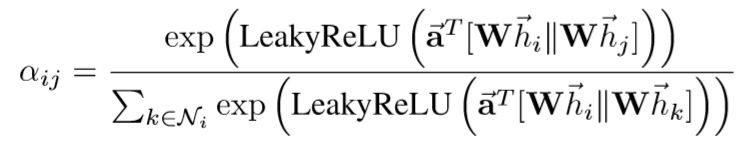
5) 生成加权求和的聚合邻居特征:

6) 为了稳定self-attention的处理过程,采用multi-level的attention,即K个attention机制重复进行,最后再进行拼接或取平均操作(最后一层网络),得到最终的聚合邻居特征。
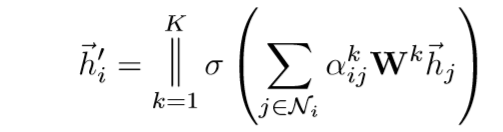
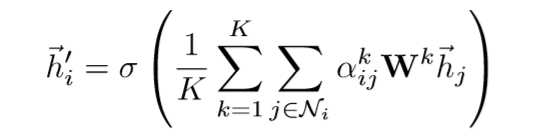
其他感悟:
1) Multi-level的attention部分,在对K个表达的处理上,除了简单的拼接,或取平均,是否可尝试更细腻的方法,比如对K个表达再利用一个attention来学习其权重,或取max-pooling,得到每个level的attention中最强的表达,做最终的表达。
2) 本文在做attention时只考虑了一跳邻居节点,后面是否可以把2跳及更高阶更全局的信息引进来。
3. H-GCN
论文:Semi-supervised Node Classification via Hierarchical Graph Convolutional Networks
作者:FenyuHu, YanqiaoZhu, ShuWu, LiangWang and TieniuTan
来源:IJCAI 2019
Motivation:
GCN的相关方法尽管在网络挖掘任务中取得了巨大成功,但大多数基于邻居聚合特征的方法,通常层数都比较浅,且缺乏graph pooling的机制,使得其很难获得充足的网络的全局信息。因此,为了扩大卷积层的感受野,本文提出了深度层次的GCN网络来机型semi-supervised的节点分类任务。(由于超点对应了原始图的局部结构,对超节点组成的超图进行卷积,也就获得了更大的感受野)
Related Work:GCN,GAT以及GraphSAGE方法,其特点在上文中均有提到,但这些方法通常层数很浅,难以获得充分的全局信息;一些Graph上的层次化表达的学习方法,利用coarsening层来得到更小量级的图,再利用无监督的方法如Deepwalk来学习节点的表达,随后利用refining层来还原原始节点的表达。但是,这种方法不能够利用节点的属性信息,且分开步骤的模式不能够端到端地进行节点分类任务。
还有一些Graph Reduction的方法,将原始Graph通过重新组合为超图的方式实现reduction,但这些方法同尝用于无监督的场景,例如社区发现。对于semi-supervised的节点分类任务,这些方法不能学习其中复杂的节点属性信息以及结构特征。
Method:
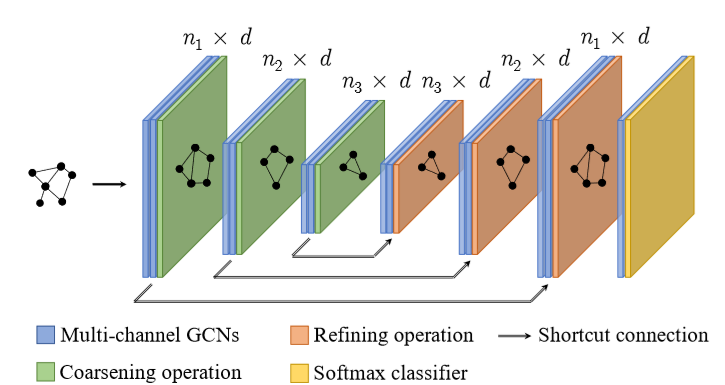
整体的H-GCN是一个end-to-end的对称的网络结构,左侧部分,在每次GCN操作后,使用Coarsening方法把结构相似的节点合并成超节点,因此可以逐层减小图的规模。对应地,右侧在每次GCN操作后将超节点进行还原,即可得到每个原始节点的表达。同时,我们在对称的神经网络层之间加了shortcut连接,从而可以更好地训练。
Coarsening layer:
1) 输入为原始图Gi以及节点表达Hi,输出为合并后的超图Gi+1,和对应的超节点表达Hi+1.
2) 计算GCN的output Gi:
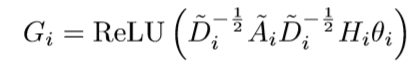
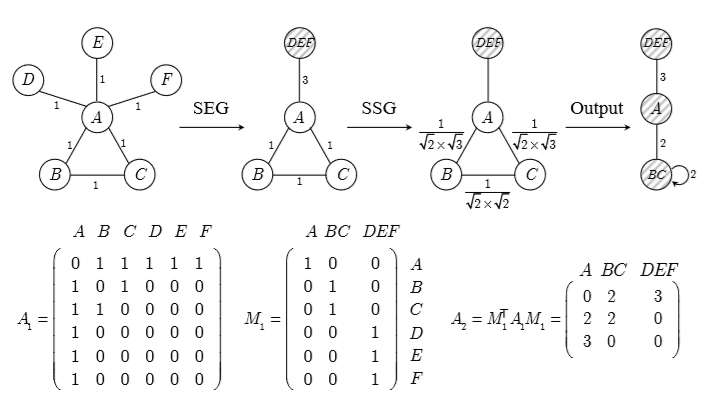
3) 合并节点成超图:利用SEG与SSG两种方式对原节点进行合并。对于每个unmarked 节点vj, 以及其邻居节点vk,计算SSG,将具有最大SSG的k与j进行合并。重复该步骤,知道所有节点均被marked位置。
4) 更新新节点与边的权重。
5) 构建组合矩阵Mi:
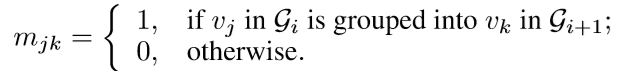
6) 计算新的节点表达Hi+1:

7) 计算新的图表达Gi+1:
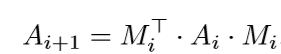
8) 继续迭代。
Refining layer:利用与之对称的组合矩阵Ml-i, 以及加入Gl-i作为shortcut,得到Hi:
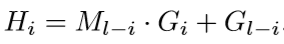
引入节点权重矩阵对Hi进行补充,对该矩阵进行对应节点的embedding_lookup来得到节点的权重向量Si,将其与Hi拼接,来作为下一层GCN的输入。
同时,引入多信道的GCN来在不同的子空间下挖掘特征,将c个不同信道得到的表达进行加权求和,得到最终的Gi,该权重作为一个参数来学习。
输出层部分,将最终表达输出到softmax层,进行相应的多分类任务。
其他感悟:
该方法是否可以用到NLP领域的常见问题中,比如问答系统中,对多组多轮对话建图,其中仅有少量对话是有标注的,基于此方法,半监督地学习其他对话的意图。
或者与知识图谱结合,在信息抽取任务中(具体的应用场景还需再进一步思考)。