MLR——基于attention的LR
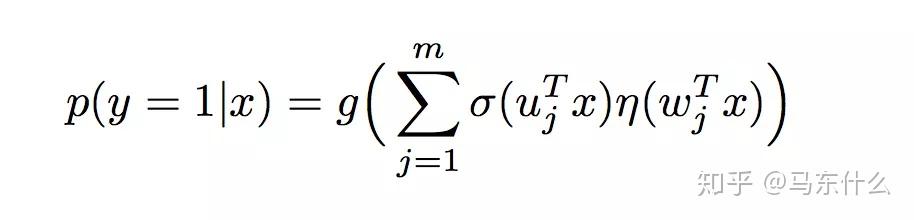
MLR的表达式,其中g(x)=x,u是聚类参数,决定了空间的划分,w是分类参数,决定空间内的预测。这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。
MLR的初衷设计是非常直观的,以风控为例,假设我们有一批坏用户,这些坏用户都是预期超过某个期限被系统判定为坏客户的人,其中可能有一部分是专业的欺诈分子(不还钱),有一部分是忘记还款,有一部分是职业老赖(可能还,但是周期长),这些用户的特征分布可能是不同的,例如像这样:
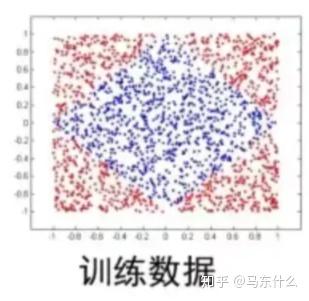
显然四个角的用户的特征情况不同,如果单纯使用lr无法拟合这种非线性的分类边界,
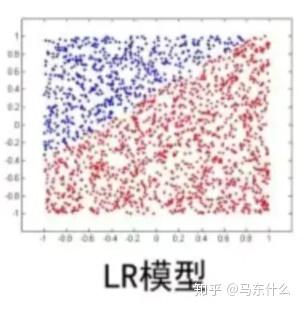
这个时候,使用mlr就可以实现很好的拟合效果,

在实际中,MLR算法常用的形式如下,使用softmax作为分片函数:
实际上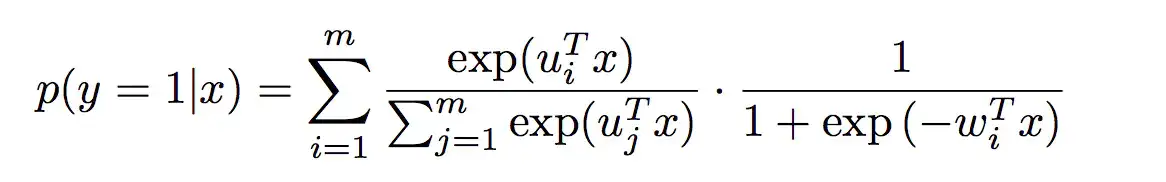
上式如果m=1,就退化成了普通的逻辑回归的形式,这是一个很有意思的地方,假设空间存在非线性的分界面难以直接使用线性模型来拟合分界面,那么我们就使用多个带权重的线性模型来拟合非线性的分界面,类似这样:
假设我们的分界面是这样的,用单个线性模型无法拟合,但是通过多个线性模型的叠加就可以拟合出来了。实际上就是带权的多个lr的叠加,只不过这里的权重系数不是人为定义而是模型学出来的。
下面看看tf的代码实现,可惜没找到keras的,否则会更好理解:
from:
https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-MLR-Demoimport tensorflow as tf
import time
from sklearn.metrics import roc_auc_score
from data import get_data
import pandas as pd
x = tf.placeholder(tf.float32,shape=[None,108])
y = tf.placeholder(tf.float32,shape=[None])
m = 2
learning_rate = 0.3
u = tf.Variable(tf.random_normal([108,m],0.0,0.5),name='u')
w = tf.Variable(tf.random_normal([108,m],0.0,0.5),name='w')
U = tf.matmul(x,u)
p1 = tf.nn.softmax(U)
W = tf.matmul(x,w)
p2 = tf.nn.sigmoid(W)
pred = tf.reduce_sum(tf.multiply(p1,p2),1)
cost1=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=pred, labels=y))
cost=tf.add_n([cost1])
train_op = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
train_x,train_y,test_x,test_y = get_data()
time_s=time.time()
result = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(0