大数据Spark企业级实战 PDF电子书下载 带书签目录 完整版.pdf
Graph的部分抄的《快刀初试:Spark GraphX在淘宝的实践》

Akka:Actor
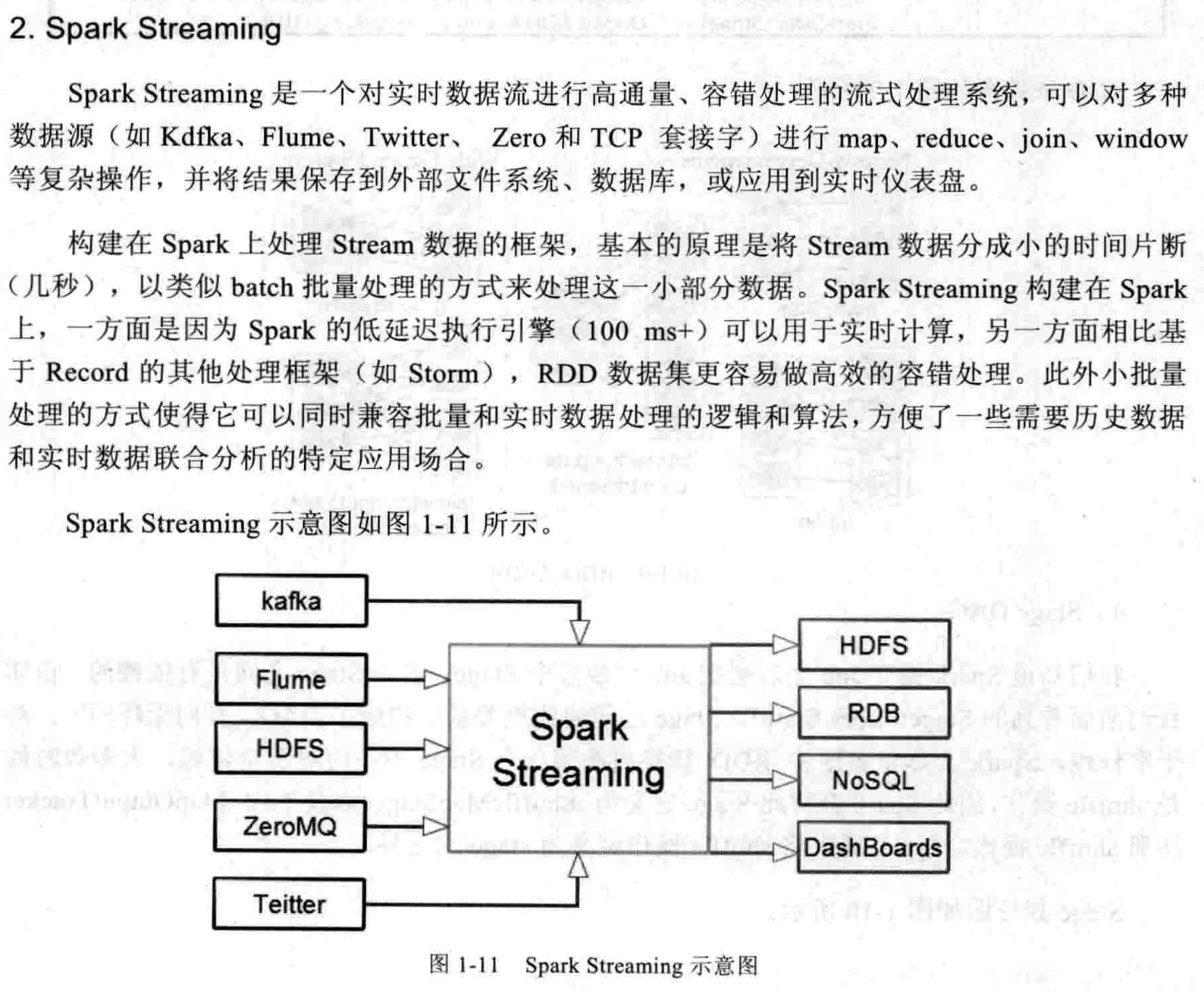
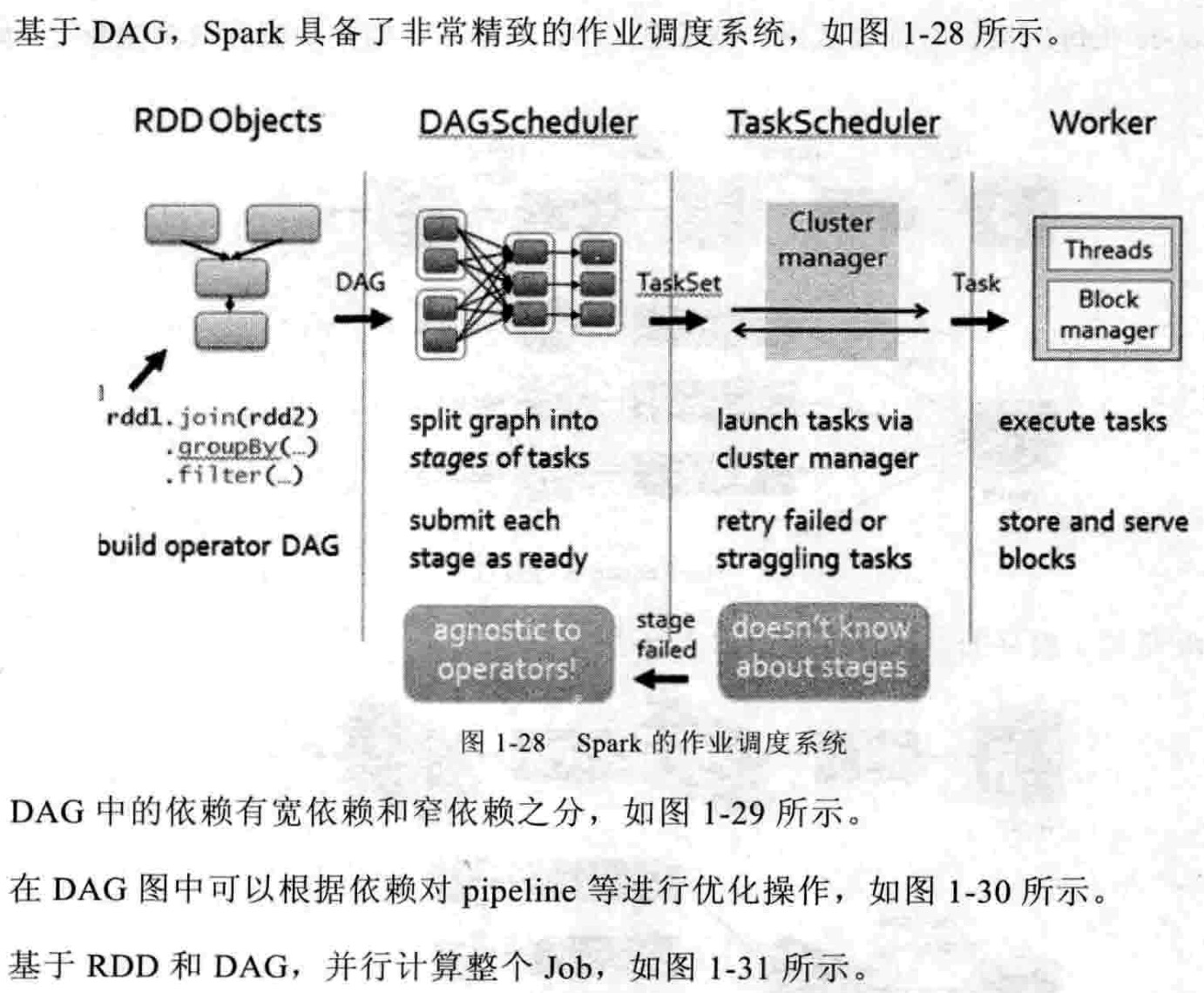
Spark 为何如此之快?
- RDD统一抽象;
- 基于内存的迭代计算;
- DAG;
- 出色的容错机制;






https://endymecy.gitbooks.io/spark-graphx-source-analysis/content/vertex-cut.html
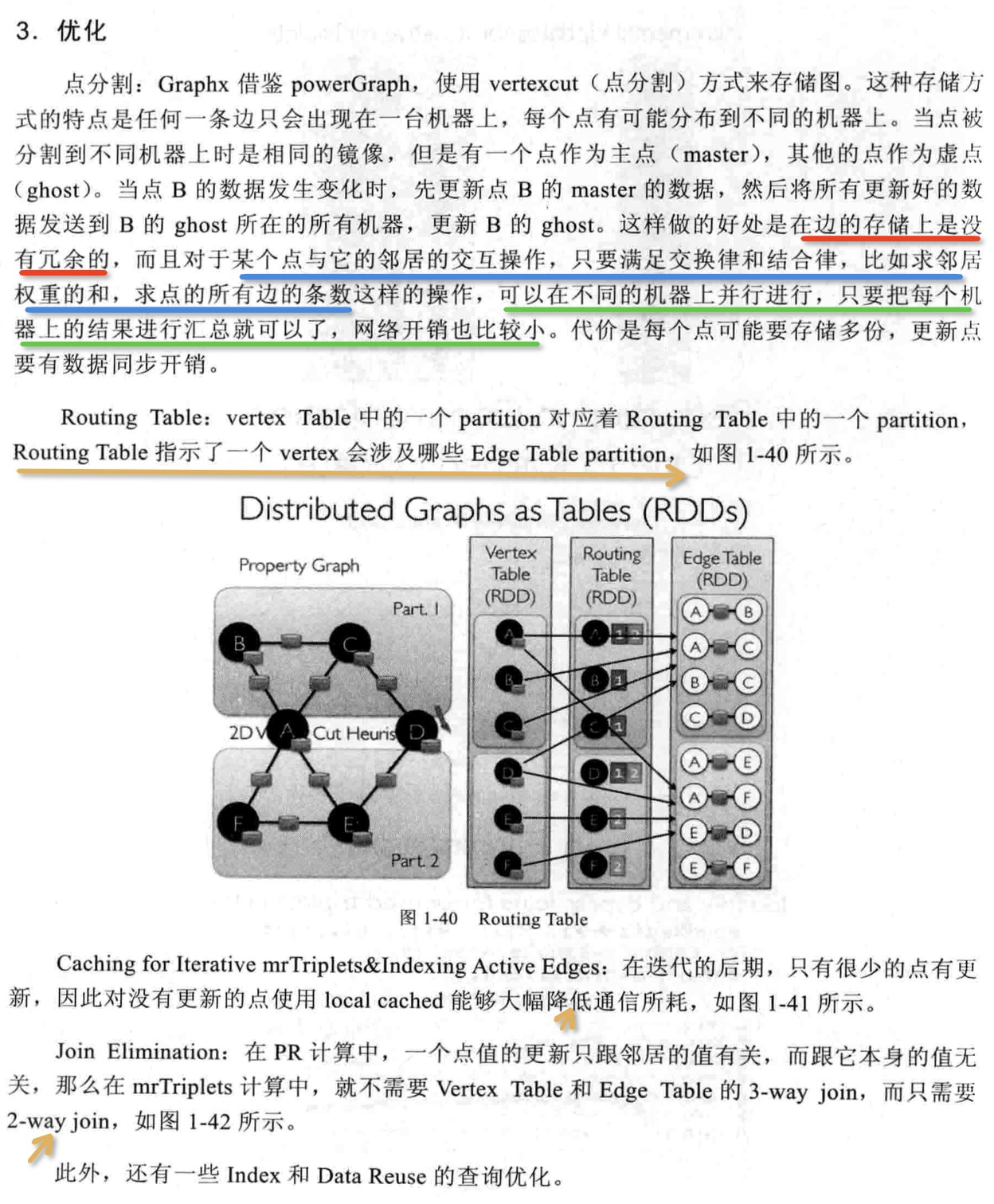
点分割存储 在第一章分布式图系统中,我们介绍了图存储的两种方式:点分割存储和边分割存储。 1 RandomVertexCut 这个方法比较简单,通过取源顶点和目标顶点 2 CanonicalRandomVertexCut 这种分割方法和前一种方法没有本质的不同。不同的是,哈希值的产生带有确定的方向(即两个顶点中较小 3 EdgePartition1D 这种方法仅仅根据源顶点 4 EdgePartition2D 这种分割方法同时使用到了源顶点 当分区数不能完全开方时,采用下面的方法。这个方法的最后一列允许拥有不同的行数。 下面举个例子来说明该方法。假设我们有一个拥有12个顶点的图,要把它切分到9台机器。我们可以用下面的稀疏矩阵来表示: 上面的例子中 在上面的例子中, 5 参考文献【1】spark源码 |
|
| https://www.cnblogs.com/shishanyuan/p/4747793.html | |
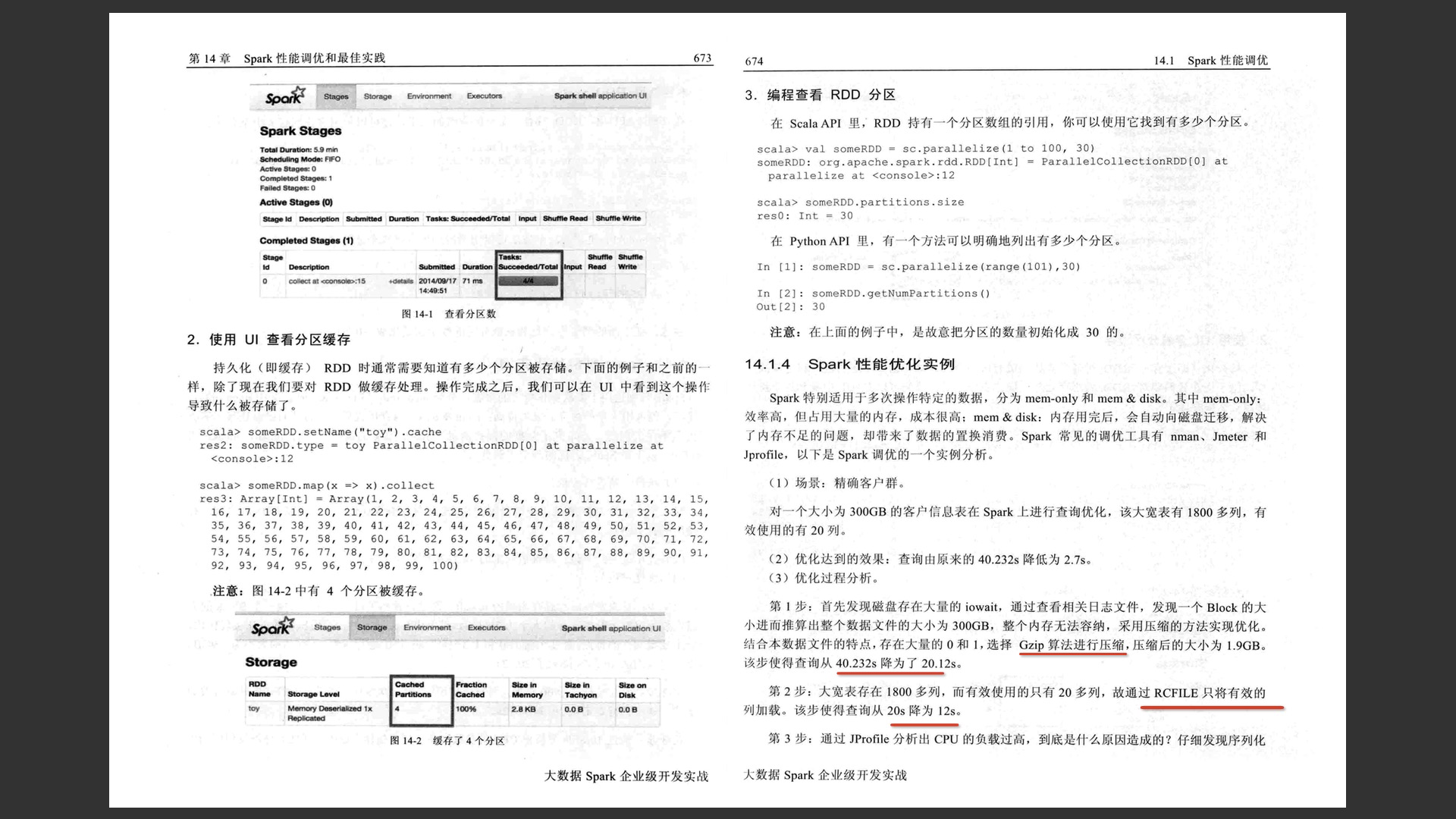
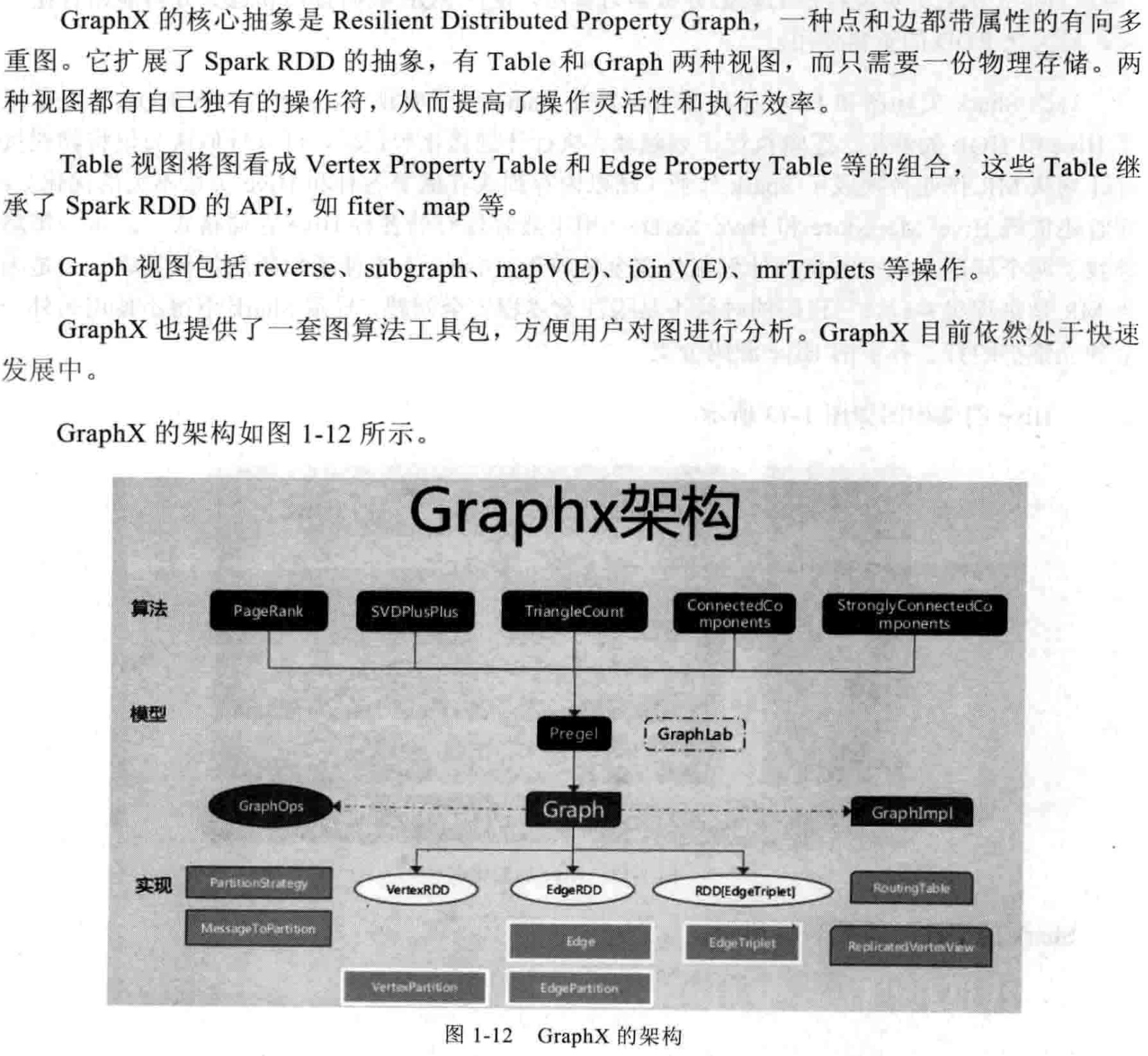
2.2.2.2 邻边聚合mrTriplets(mapReduceTriplets)是GraphX中最核心的一个接口。Pregel也基于它而来,所以对它的优化能很大程度上影响整个GraphX的性能。mrTriplets运算符的简化定义是: 它的计算过程为:map,应用于每一个Triplet上,生成一个或者多个消息,消息以Triplet关联的两个顶点中的任意一个或两个为目标顶点;reduce,应用于每一个Vertex上,将发送给每一个顶点的消息合并起来。 mrTriplets最后返回的是一个VertexRDD[A],包含每一个顶点聚合之后的消息(类型为A),没有接收到消息的顶点不会包含在返回的VertexRDD中。 在最近的版本中,GraphX针对它进行了一些优化,对于Pregel以及所有上层算法工具包的性能都有重大影响。主要包括以下几点。 1. Caching for Iterative mrTriplets & Incremental Updates for Iterative mrTriplets:在很多图分析算法中,不同点的收敛速度变化很大。在迭代后期,只有很少的点会有更新。因此,对于没有更新的点,下一次mrTriplets计算时EdgeRDD无需更新相应点值的本地缓存,大幅降低了通信开销。 2.Indexing Active Edges:没有更新的顶点在下一轮迭代时不需要向邻居重新发送消息。因此,mrTriplets遍历边时,如果一条边的邻居点值在上一轮迭代时没有更新,则直接跳过,避免了大量无用的计算和通信。 3.Join Elimination:Triplet是由一条边和其两个邻居点组成的三元组,操作Triplet的map函数常常只需访问其两个邻居点值中的一个。例如,在PageRank计算中,一个点值的更新只与其源顶点的值有关,而与其所指向的目的顶点的值无关。那么在mrTriplets计算中,就不需要VertexRDD和EdgeRDD的3-way join,而只需要2-way join。 所有这些优化使GraphX的性能逐渐逼近GraphLab。虽然还有一定差距,但一体化的流水线服务和丰富的编程接口,可以弥补性能的微小差距。 2.2.2.3 进化的Pregel模式GraphX中的Pregel接口,并不严格遵循Pregel模式,它是一个参考GAS改进的Pregel模式。定义如下:
这种基于mrTrilets方法的Pregel模式,与标准Pregel的最大区别是,它的第2段参数体接收的是3个函数参数,而不接收messageList。它不会在单个顶点上进行消息遍历,而是将顶点的多个Ghost副本收到的消息聚合后,发送给Master副本,再使用vprog函数来更新点值。消息的接收和发送都被自动并行化处理,无需担心超级节点的问题。 常见的代码模板如下所示:
可以看到,GraphX设计这个模式的用意。它综合了Pregel和GAS两者的优点,即接口相对简单,又保证性能,可以应对点分割的图存储模式,胜任符合幂律分布的自然图的大型计算。另外,值得注意的是,官方的Pregel版本是最简单的一个版本。对于复杂的业务场景,根据这个版本扩展一个定制的Pregel是很常见的做法。 |



3 triplets 在 同样,也可以通过下面图解的形式来表示它的含义: 
4 参考文献【1】spark源码 |
|
|
|