
从Google Visor到Microsoft NNI再到Advisor调参服务接口发展史
介绍
从规则编程到机器学习,从人工调参到AutoML(meta-machine learning),一直是整个行业发展的趋势。目前各种黑盒优化算法、增强学习算法也越来越得到工业界接受,最著名的当属来自DeepMind的AlphaGo和AlphaZero。我们都知道AlphaZero用了基于梦特卡索树搜索的增强学习架构来实现自我提升,但一个模型有数以千计的超参数需要调优,其背后就是基于大规模的GPU训练集群以及启发式的贝叶斯优化算法。BayesianOptimization是目前最流行的黑盒优化算法,也就是说适用于任何函数、模型或者框架,相比与RL需要样本量小很多,基于联合高斯分布的前提数理上保证收敛,除此之外还有Grid search、Random search、TPE、PSO、SMAC等主流调参算法。
调参算法是成熟而公开的,但不是所有开发者都需要掌握其实现,例如BayesianOptimization的实现就需要包含了Gaussian process的计算以及Acquisition function的选择,就像大家都在用sgd/adam/adagrad/ftrl优化器也可以不了解其更新逻辑。因此各种实现黑盒优化算法的调参类库以及调参服务应用而生,这里主要区分Library以及Service因为其使用接口区别很大,本文就将以Google Vizier、Microsoft NNI和Advisor为例介绍这些调参框架的设计和实现。
下面列举其他非常不错、值得参考的开源调参框架:
- Distributed Asynchronous Hyperparameter Optimization in Python hyperopt/hyperopt
- A fully decentralized hyperparameter optimization framework AIworx-Labs/chocolate
- Hyperparameter Optimization for Keras Models autonomio/talos
- AutoML library for building modular, reusable, strongly typed machine learning workflows on Spark salesforce/TransmogrifAI
- hyperparameter_hunter HunterMcGushion/hyperparameter_hunter
- Milano is a tool for automating hyper-parameters search for your models on a backend of your choice https://github.com/NVIDIA/Milano
- Repository for hyperparameter tuning kubeflow/katib
- AMLA: an AutoML frAmework for Neural Networks CiscoAI/amla
- Ray Tune https://ray.readthedocs.io/en/latest/tune.html
Google Vizier
我最早接触自动调参是从Google CloudML的功能列表中了解到的,直到看到Vizier的论文全文才了解到其背后的实现,论文地址 https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf 。简单来说,Google CloudML提供了一个云端训练模型和自动调参的功能,用户把Python代码上传上去,定义一个HyperparameterSpec,云平台就会使用调参算法并行训练并且选择效果最优的超参组合和模型,幕后功臣则是Google内部的Vizier服务。在Google内部,Vizier不仅提供调参服务给Google Cloud的服务,面向跟底层还提供了批量获取推荐超参、批量更新模型结果、更新和调试调参算法以及Web控制台等功能,因此内部Vizier服务才展示了最完整的调参服务概况。
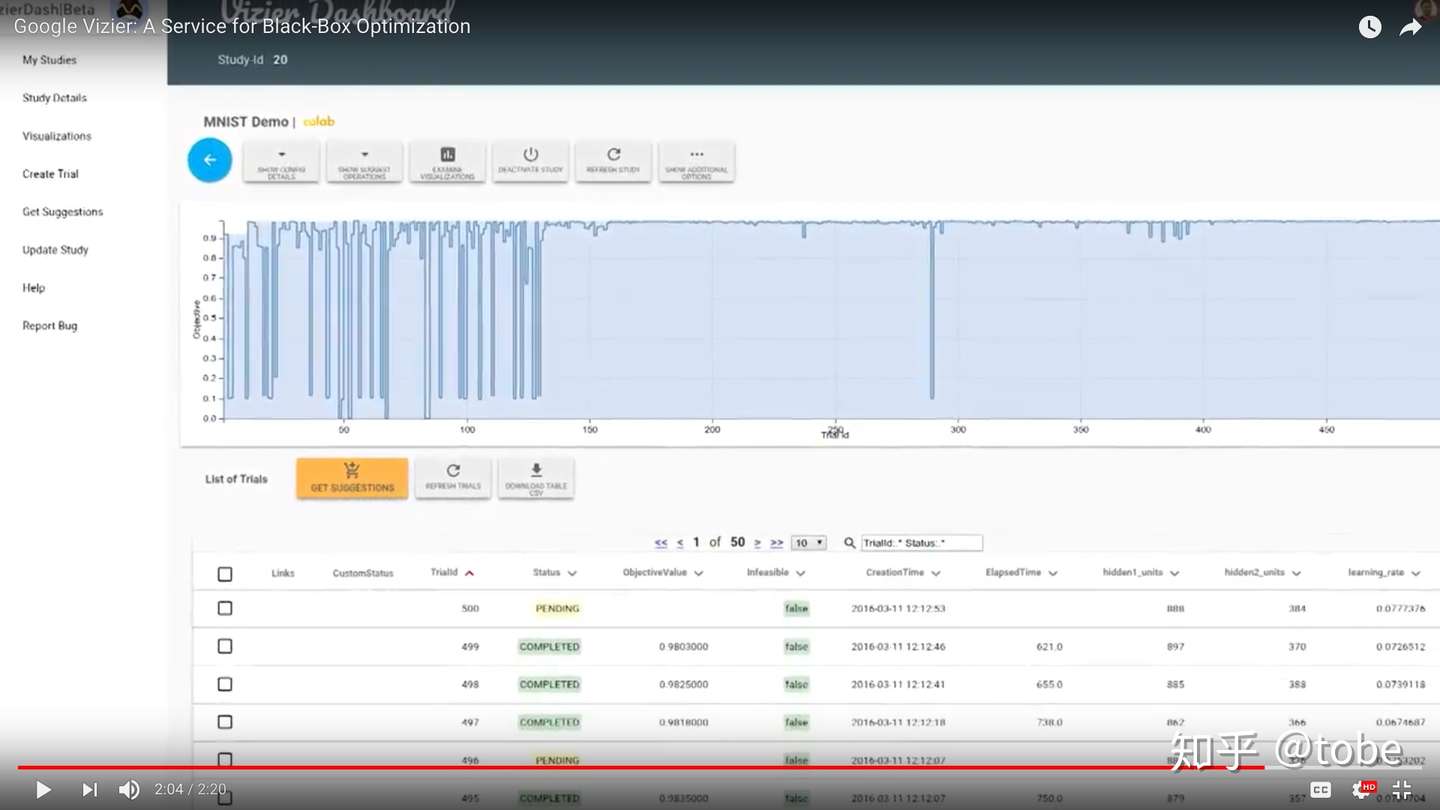
从前面提到的分类方式来讲,Google Vizier属于Service,也就是说所有的算法和逻辑实现都在后端,客户端只能通过API或SDK来访问服务。这样做的好处非常多,例如后端有新算法的更新不需要去升级使用者代码,后端实现高可用比客户端维护状态更安全,后端算法计算不需要占用模型训练者资源,当然还有最重要的一个原因,就是后端服务可以收数据。作为业界最领先的用增强学习和迁移学习来下围棋和为机房省电的企业,Google用自动调参服务的数据来调优自动调参服务当然就在情理之中了,如果机器学习就是基于数据的meta-learning,那么调超参的服务就是meta-meta-learning,那么“调”调超参服务的这个服务就是meta-meta-meta-learning了。实际上Google Vizier也做不到所有超参或者超参的超参都由机器来学习调整,但他们确实从历史调参数据中用迁移学习解决了算法冷启动问题,目前即使是贝叶斯优化也存在冷启动问题,也就是说有一定量样本后才可以开始启发式地调优,如果没有样本数据只能先Random search几把才用贝叶斯优化,Google Vizier论文则提到通过对搜索空间的变换可以复用历史推荐样本,感兴趣可以一起探讨下细节。
当然,看似美好的接口设计也存在不足,最大的问题就是难用,或者说需要改代码才能用。这是所有调参框架都要面对的问题之一,因为框架需要保证用户的模型用上了推荐的超参数,而且需要收集用户模型的指标以便于后续超参的推荐,因此用户代码至少需要加两个接口getParameters()和outputMetrics()。前面提到Google CloudML只需要定义一个HyperparameterSpec就可以了,实际上你的模型代码也要改,首先是通过tf.FLAGS或者argparse等参数的方式获取Vizier提供的超参,然后使用TensorBoard event file或者Estimator add metrics把模型的指标回报给Vizier。使用Google CloudML的话只要按照 https://cloud.google.com/ml-engine/docs/tensorflow/using-hyperparameter-tuning 这个文档的规范编码就可以了,但开发者更多时候要在本地调试代码而且也不一定非要用TensorFlow来建模,这样Google CloudML就很难支持了。
当然Google Vizier在内部提供了更底层的API,例如可以CRUD各种资源,如Study、Trial、Metrics等,甚至可以在Algorithm Playground中添加自己实现的黑盒调优算法。由于Google Vizier没有开源,具体的API接口不得而知,但从我们实现的开源版Vizier发现,提供Study/Trial/Metrics接口其实并不易用,而且对用户代码侵入较大,易用性远不如基于Library的hyperopt、chocolate等框架好用。
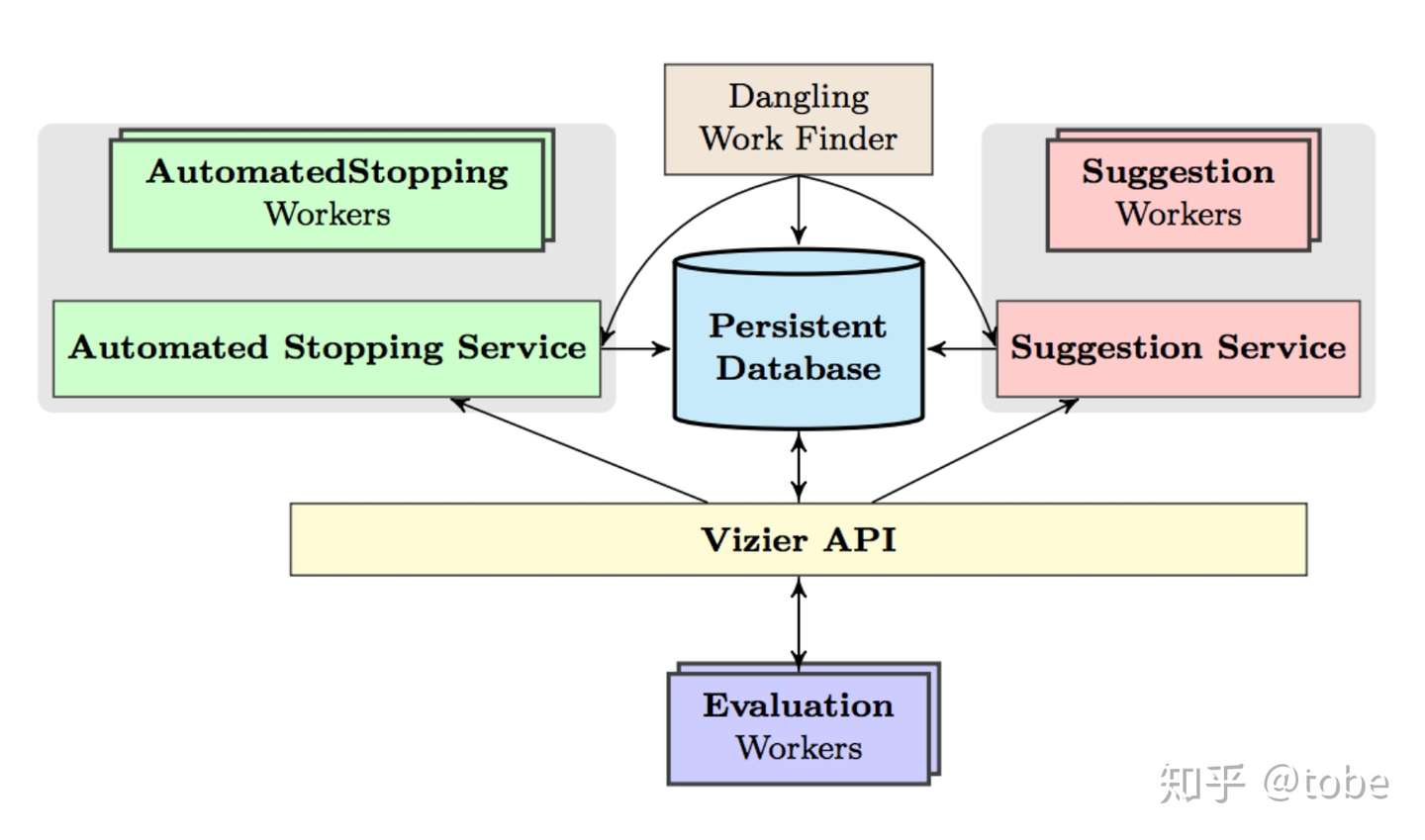
上图是Google Vizier的整体架构,看图其实也基本了解其实现了,有定义调参服务的接口API,包括Search sapce的格式规范和支持的类型,还有数据库进行数据持久化,两边是可扩展、可插拔的Suggestion算法和Early stopping算法。通过对API的封装实现了一个HyperTune subsystem,也就是Google CloudML产品中的自动调参功能。
Microsoft NNI
说完Google的调参服务,我们来看看业界另一大标杆巨硬公司的产品,NNI(Neural Network Intelligence)是Microsoft近期开源的调参工具包,项目地址 Microsoft/nni 。从名字和官方教程可以看出,NNI相比于Vizier其实是一个Library,也就是说算法是运行在客户端本地的,当然NNI也提供了远程运行训练任务的功能,运行NNI的机器相当于算法控制器。
NNI与Hyperopt类似(实际上NNI内置的TPE算法就是用的hyperopt),使用体验上要比Vizier好不少,同样地用户需要定义Search space和修改代码来获取参数、导出Metrics结果,但提供了一个运行配置,可以像本地命令行一样执行模型训练代码,不论用户使用TensorFlow还是CNTK等任意框架,下面是官方提供的使用流程图。

如果深入看NNI源码,本体是Python实现的命令行工具,和大部分调参Library实现类似,亮点是可以集成其他类库的调参算法,因此借此可以介绍下一般通用调参框架的架构实现。
首先,所有调参服务都有自定义的Search space格式规范,为什么不能有统一的规范让所有框架去实现?是因为不同框架实现的处理方式有区别,例如Google Vizier支持了INTEGER、DOUBLE、DISCRETE、CATEGORICAL这几种类型描述,而Microsoft NNI因为兼容hyperopt算法,开源类库chocolate也有相似的定义,支持的都是类似hyperopt.hp.uniform()、hyperopt.hp.choice()的超参描述。虽然框架不同,但Search space基本都可以用JSON来表达,对于Service类型调参框架因为只能通过API请求,因此必须是标准的JSON数据,不能包含Python SDK函数,而Library类型调参框架可以像Hyperopt用函数来表示,也可以像NNI用标准JSON数据格式来表示。如果我们去取所有框架搜索空间类型的子集,理论上所有框架的算法都可以互通互用,在后面要提到的Advisor调参服务上,我们也是参考NNI实现了对Hyperopt的TPE、Random search、Simulate anneal算法以及Chocolate的Quasi random search、Random search、Grid search、Bayes search、CMAES、MOCMAES算法集成。
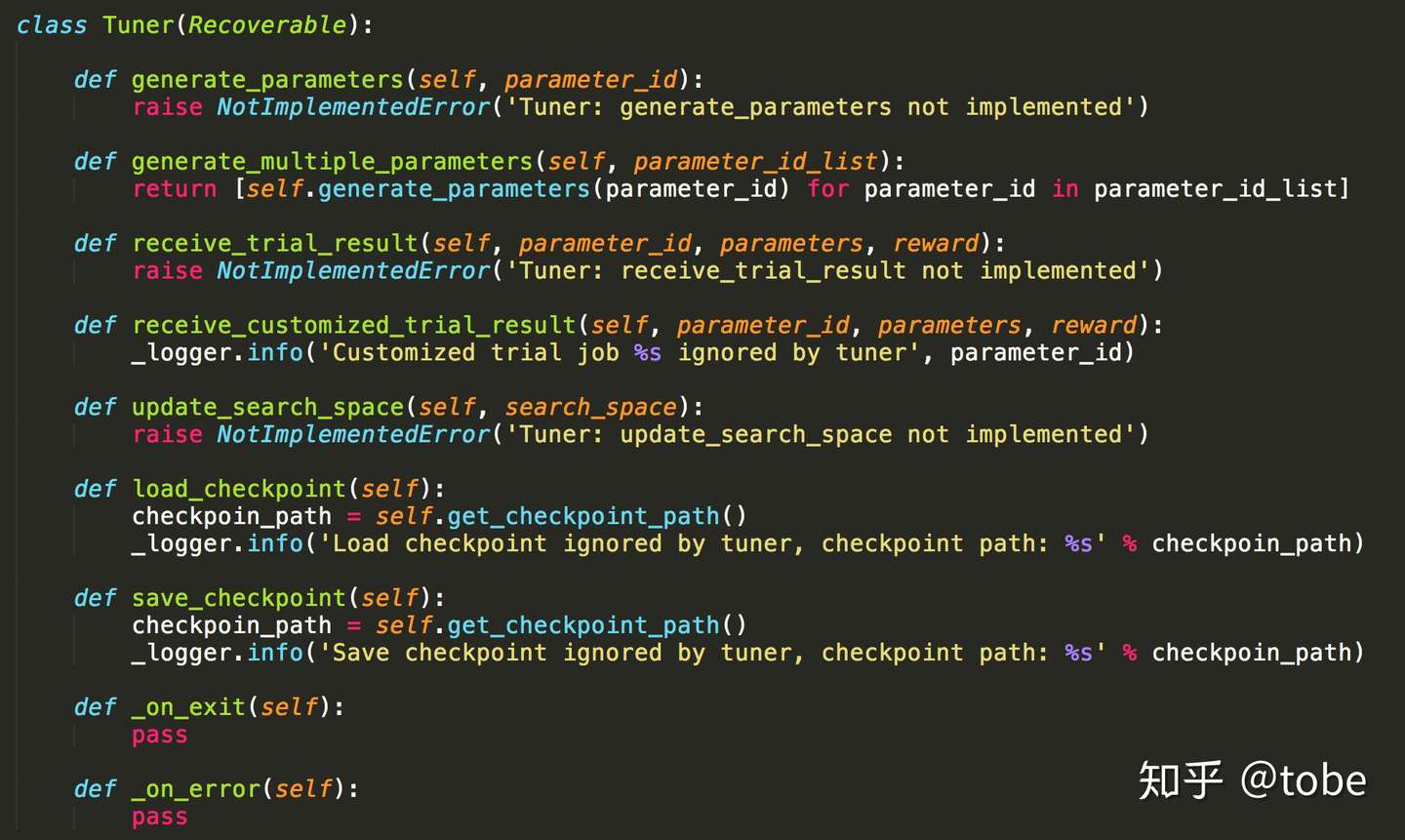
第二步就是调参算法的实现,在NNI中除了前面提到的Hyperopt TPE算法,底层实现了Evolution tuner也就是进化算法。对于这类算法的实现,主要是要实现一个generate_parameters()接口,当然好的算法需要根据历史的训练数据来“启发式”推荐参数,因此NNI也提供一个receive_trial_result()接口,算法可以根据用户模型的结果动态更新调参算法本身的参数。下面是Microsoft NNI各种调参算法实现的基类接口。
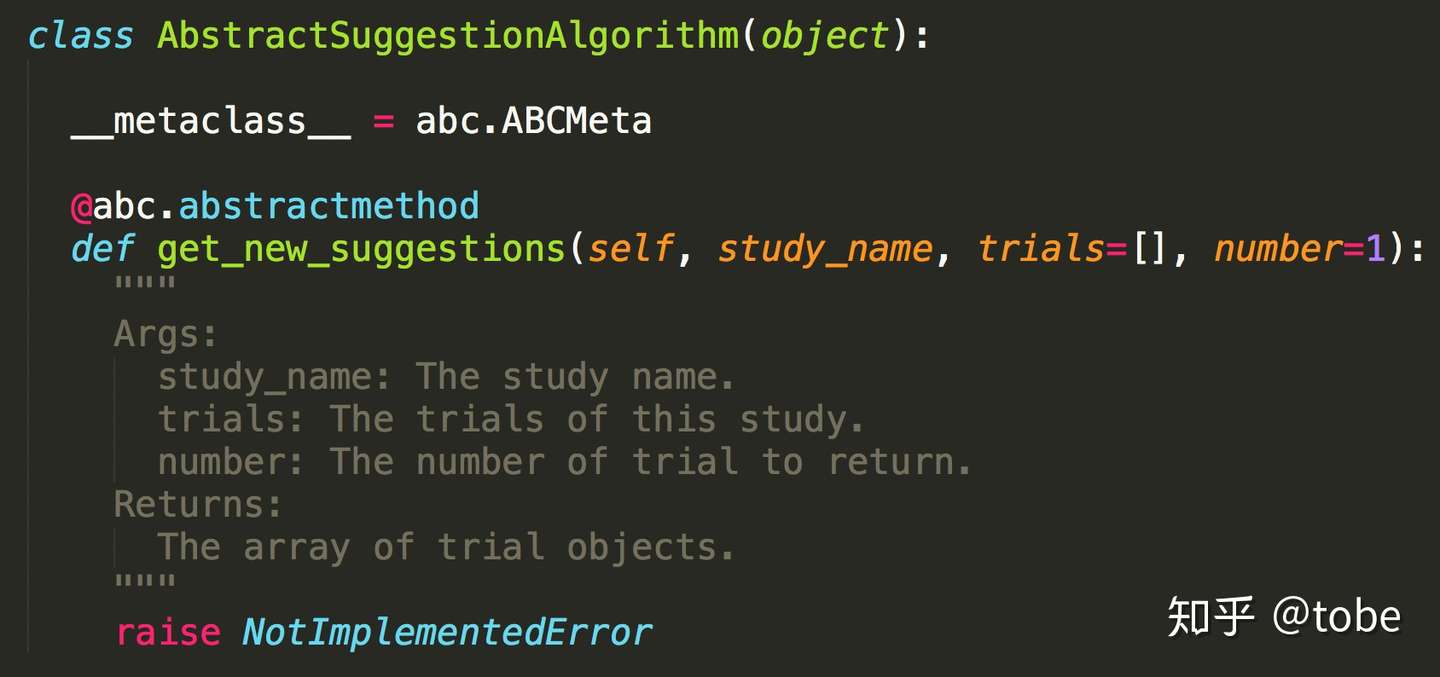
在Advisor项目中,我们的算法定义就更加简洁了,当然从极致的性能角度考虑,Library类型框架可以把调参对象放在内存中维护,生成超参不需要重新加载历史结果因此效率更高,不过调参服务性能不会是调参瓶颈因此一般可以不考虑。
最后就是定义调参的API和SDK,这也是直接影响使用者体验和应用场景的关键。前面提到Google Vizier目前只能在Google CloudML中使用,因此只能优化TensorFlow模型的超参,而NNI提供了pynni的Python SDK,因此只要是Python应用都可以使用,也就是几乎所有的机器学习建模脚本(CNTK、TensorFlow、PyTroch、MXNet等等)都可以应用。而且相比于纯SDK的接入方式,NNI还提供一个命令行工具nnictl,用户可以写一个配置文件,然后使用nnictl来启动训练和调参任务,而且通过拓展NNI的TrainingServicePlatform,目前支持把任务运行在local和remote,实现上也不复杂使用了TypeScript的ssh库,当然未来很容易可以拓展让任务运行在Kubernetes、Mesos、Yarn等分布式平台上。除了NNI这类使用方式,还有更机制的调参框架集成,例如针对Scikit-learn封装Hyperopt而成的hyperopt-sklearn,只要简单替换Scikit-learn中的Estimator对象就可以实现全自动的多任务调参过程,这种封装在已经实现了调参核心算法和逻辑的框架上就非常好实现了。
Advisor
看完Google Vizier和Microsoft NNI服务的架构,其实最想重点介绍的是Advisor,一个基于Vizier论文实现的调参服务,同时也集成了NNI的接口使用特点,当然还有最流行的BayesianOptimization等算法实现,开源地址 tobegit3hub/advisor 。

如果想了解Advisor的架构特点和领域抽象,可以直接参考Vizier论文,因为里面定义的Study、Trial、TrialMetrics都与Vizier一致(好的抽象很重要!),甚至Search space的配置也保持与Vizier兼容,而选择Service的实现方式有助于未来迁移学习的算法实现。在Vizier的架构基础上,我们可以摆脱对TensorFlow的绑定,提供无侵入的使用体验。前面提到使用所有调参框架都必须修改代码调用getParameters()和outputMetrics()接口,所谓“无侵入”只能通过约定的方式实现,参考Google CloudML我们可以把超参作为命令行参数传入,这样与用户在本地命令行调试模型的体验一致,而回报模型指标只需要用户在stdout最后一行打印Metrics即可,这比NNI必须依赖SDK来获取参数和回报指标跟进一步。
下面是使用Scikit-learn进行MNIST模型训练的一个例子,这个代码逻辑可以由开发者在命令行通过调参来观察模型效果进而选择最优的超参,同样也可以直接使用Advisor进行自动的分布式的调参。
import argparse
from sklearn import datasets, svm, metrics
parser = argparse.ArgumentParser()
parser.add_argument("-gamma", type=float, default=0.001)
parser.add_argument("-C", type=float, default=0.5)
parser.add_argument("-kernel", type=str, default="sigmoid")
parser.add_argument("-coef0", type=float, default=0.1)
args = parser.parse_args()
def main():
digits = datasets.load_digits()
images_and_labels = list(zip(digits.images, digits.target))
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
classifier = svm.SVC(
gamma=args.gamma, C=args.C, kernel=args.kernel, coef0=args.coef0)
classifier.fit(data[:n_samples // 2], digits.target[:n_samples // 2])
expected = digits.target[n_samples // 2:]
predicted = classifier.predict(data[n_samples // 2:])
accuracy = metrics.accuracy_score(expected, predicted)
print(accuracy)
if __name__ == "__main__":
main()对于Adhoc的Python函数,在我们不知道函数是否可导或者有极值的情况下,我们也可以用Advisor来计算(算力越大效果越好),不同场景也可以选用BO、RS、GS、TPE、PSO等对应的调参算法,是真正的黑盒优化,甚至是不同编程语言实现的机器学习框架也原生支持。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-x", type=float, default=0.0)
args = parser.parse_args()
def main():
# Read parameters
x = args.x
# Compute or learning
y = x * x - 2 * x + 1
print("Formula: {}, input: {}, output: {}".format("y = x * x - 2 * x + 1", x, y))
# Output the metrics
print(y)
if __name__ == "__main__":
main()这里介绍下使用Advisor的调参全流程,安装是很简单的可以使用“pip install advisor-clients”,启动Server服务端方式有多种,使用内置的脚本、Docker容器、docker-compose或者是Kubernetes集群。
advisor_admin server start
docker run -d -p 8000:8000 tobegit3hub/advisor
docker-compose up -d
kubectl create -f ./kubernetes_advisor.yaml
然后编写你的模型训练代码,由于“无侵入”的约定用户不需要再引入任务与模型无关的代码,例如不需要"import advsior_client",直接用前面的Scikit-learn代码以及原生Python脚本即可。到目前为止我们还没有定义Search space,实际上这是调参应用所必须定义的,也就是创建Vizier中的Stduy或者是NNI中的Experiment,这个我们参考NNI用法提供了JSON配置文件,用户可以在文件中指定Search space、调优算法、启动目录、启动脚本等系列参数。
{
"name": "demo",
"algorithm": "BayesianOptimization",
"trialNumber": 10,
"concurrency": 1,
"path": "./advisor_client/examples/python_function/",
"command": "./min_function.py",
"search_space": {
"goal": "MINIMIZE",
"randomInitTrials": 3,
"params": [
{
"parameterName": "x",
"type": "DOUBLE",
"minValue": -10.0,
"maxValue": 10.0,
"scalingType": "LINEAR"
}
]
}
}最后命令行运行即可,启动后可以看到终端打印的调试信息以及推荐的参数,使用BayesianOptimization设置可以看到样本越多推荐的结果越接近最优解,当然这个配置Aquisition function的expolration和exploitation来控制,这里就不赘叙了。
advisor run -f ./advisor_client/examples/python_function/config.json
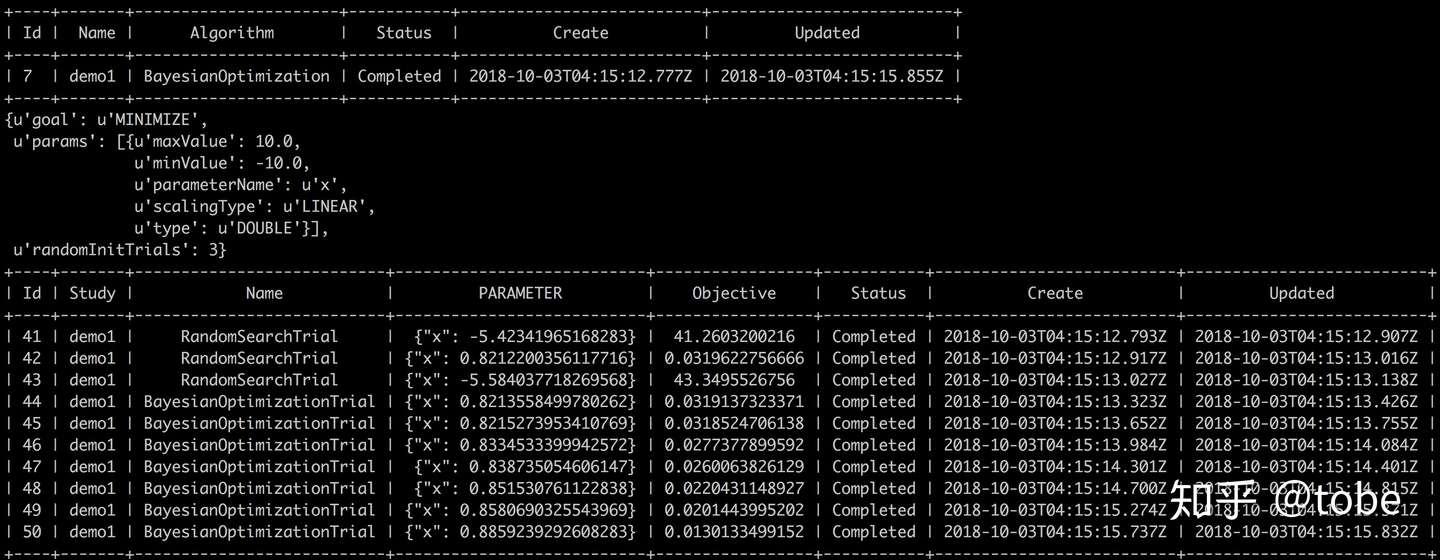
考虑到用户还有其他方式训练模型的可能,Advisor API和SDK还有批量导入Trial、TrialMetrics等功能,这样就可以集成不用Advisor训练的历史结果提高贝叶斯优化效果,而不需要像hyperopt那样手动插入数据到SQLite(后续单开文章介绍hyperopt的源码和集成TPE算法的方法)。算法拓展也非常容易,除了可以使用已经集成的八种算法,只要编写一个Python文件实现get_new_suggestions(self, study_name, trials=[], number=1)接口即加入自己的算法,所有算法实现都有对应的单元测试,感兴趣可以阅读源码了解 tobegit3hub/advisor 。未来考虑提供TensorFlow/Keras/Scikit-learn/XGBoost Estimator的wrapper,为Kaggle比赛的自动调参提供极致的体验。
总结
最后总结一下,目前自动调参服务正所谓百花齐放,Microsoft、Nvidia、Salesforce都有对应的开源产品,而Spark、Ray和Kubernetes也有高度集成的功能模块,但所有调参框架都存在接口格式不统一,代码侵入性较大的问题。
希望通过本文大家可以了解业界主流的黑合优化框架的架构设计和实现原理,对比Google Vizier、Microsoft NNI以及Advisor的接口设计进程,实现代码“无侵入”的调参服务,同时也欢迎大家来使用和改进Advisor,任何Issue和PR都是非常有价值的。最近(2018年10月1日)我们就收到3个来自不同地区的Pull-request,开发者分别来自法国雷恩、巴西圣保罗以及瑞士,虽然都是小改动但也是十分appreciated的。
黑盒优化作为AutoML、NAS的基础,meta-learning中的meta,相信未来必然有更广的应用场景!
1 人已赞赏

文章被以下专栏收录
推荐阅读
像Google一样构建机器学习系统 - 开发你的机器学习工作流
按照上篇文章搭建了一套Kubeflow Pipelines之后,我们一起小试牛刀,用一个真实的案例,学习如何开发一套基于Kubeflow Pipelines的机器学习工作流。准备工作机器学习工作流是一个任务驱动的…
归一化激活层的进化:谷歌Quoc Le等人利用AutoML 技术发现新型ML模块
最近,谷歌大脑团队和 DeepMind 合作发布了一篇论文,利用 AutoML 技术实现了归一化激活层的进化,找出了 BatchNorm-ReLU 的替代方案 EvoNorms,在 ImageNet 上获得 77.8% 的准确率,超越 B…
2018年ML/AI重大进展有哪些?LeCun推荐了这篇回答

9 条评论
棒~!
在kaggle的kernal里的用法是参考这个对吧?https://github.com/tobegit3hub/advisor/blob/master/examples/scikitlearn/scikitlearn_util.py
是的,可以直接裸用Advisor API,也可以写json文件用advisor run,模型代码是一样的。
这么厉害的吗?请问可以调节xgb、lgb、catboost吗
advisor 貌似只支持python2
advisor能支持python3吗?
你好,请教一个问题,windows下,advisor工具启动advisor_admin server start时,出错SyntaxError: invalid syntax,请教下怎么回事
如果出现的是except subprocess.CalledProcessError, e:这句的语法错误的话, 把逗号那里改成as就可以。
大佬,windows下运行,Run the command: docker ps |grep 'tobegit3hub/advisor',这个怎么办