级联多对抗的 LAPGAN(一)原理分析
本文介绍的 LAPGAN【1】是 NIPS2015 上的一篇文章(NIPS 现在改名为 NeurIPS),LAPGAN 通过级联的生成对抗网络 GAN 实现从粗略到精细的图像生成功能。LAPGAN 获得的视觉效果在当时十分惊艳,其多个 GAN(Generative Adversarial Networks)网络级联的思想更是对后面的研究产生了极大的影响,其生成的图像视觉效果如下:

下文将从拉普拉斯金字塔原理开始,逐步展开其级联对抗网络的讨论,并分析其采样和训练过程等。
一、高斯金字塔与拉普拉斯金字塔
关于高斯与拉普拉斯金字塔【2】的具体知识可以看我前面的文章:高斯金字塔与拉普拉斯金字塔的原理与 python 构建。
在分析之前首先约定符号所表示的含义:
(1)d(·) 表示下采样,即 down 首字母;I 表示图像,即 image 首字母;u(·) 表示上采样,即 up 首字母;
(2)j 表示图像 I 的长宽均为 j;
所以,对于一张长宽为 j 的图像,下采样 d(I) 得到的尺寸为(j/2,j/2),上采样 u(I) 得到的图像尺寸为 (2j, 2j)。
通过对图像 I0=(j, j) 连续的进行 K 次下采样 d(·) 操作,可以获得尺寸为 I1=(j/2, j/2)、I2=(j/4, j/4).....(j/2**K, j/2**K) 的一系列图像:
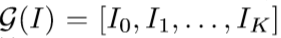
上式中 G(I) 表示图像 I 的高斯金字塔。当 K=5 时,可以获得下面的 6 层高斯金字塔:

拉普拉斯金字塔的构建需要使用高斯金字塔,计算方式如下:
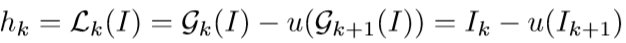
上式中 k 表示第 k 级,Lk(I) 表示第 k 级的拉普拉斯金字塔,上式看起来很复杂,实际上想要表达的是拉普拉斯金字塔的第 k 层 Lk(I)=Ik-u(Ik+1),也就是拉普拉斯金字塔第 k 层等于高斯金字塔第 k 层减去高斯金字塔第 k+1 层的上采样。所以,拉普拉斯金字塔表示用高斯金字塔第 k+1 层重建第 k 层所需的差值,可视化如下:

可以看出,重建差值的视觉效果一般都是类似图像的轮廓结构图。
二、Laplacian Generative Adversarial Networks(LAPGAN)
LAPGAN 将条件生成对抗网络 CGAN 集成到它的拉普拉斯金字塔结构中,符号约定如下:
(1)G0、G1......Gk 表示 k 个卷积网络(即生成器 Generator);
(2)z 表示噪声数据,符合某种分布,如高斯分布;
下式表示高斯金字塔的重建过程:
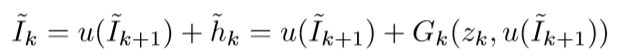
高斯金字塔的第 k 层重建需要用它的第 k+1 层上采样 (即 u(Ik+1)) 加上拉普拉斯金字塔第 k 层(即 hk),其中 hk 是第 k 个生成器 Gk 通过 zk 和 u(Ik+1)生成的。其中 Ik+1 初始值为 0,最高级的 Gk 仅仅使用噪声矢量 z 作为输入生成 Ik,因为它没有上一级:
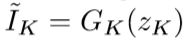
除了最高级以外,其余的生成器 G0、G1......Gk-1 都采用上一级的上采样 u(Ik) 和噪声 zk 作为联合输入,其中上采样 u(Ik) 就是 “条件变量”。
三、网络结构与训练过程
下面以 K=3 即 4 层结构为例,包含 4 个生成器 G0、G1、G2 和 G3。LAPGAN 采用了随机训练的策略:在每次迭代中,随机的选择使用 Gk 生成 hk 或者使用标准拉普拉斯金字塔构建流程(第一节中构建方式)获取 hk。
下面是采样流程,整体功能是通过右下角的噪声 z3 生成最左边的 I0~ 图像:
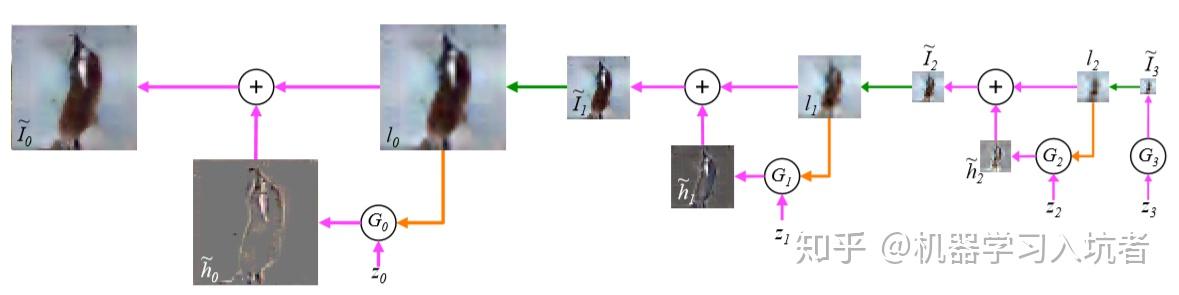
自右向左分析:
(1)首先是 z3 单独输入 G3 生成图像 I3,然后对 I3 上采样获得图像 L2,L2 即条件变量;
(2)L2 和 z2 联合输入到 G2 中,生成差异图像 h2(即拉普拉斯金字塔 h2 层),随后 h2 和 L2 相加获得 I2(即高斯金字塔 I2 层);
(3)上述过程再次重复两次,就能得到最终的高分辨率图像 I0。
下面是训练过程:
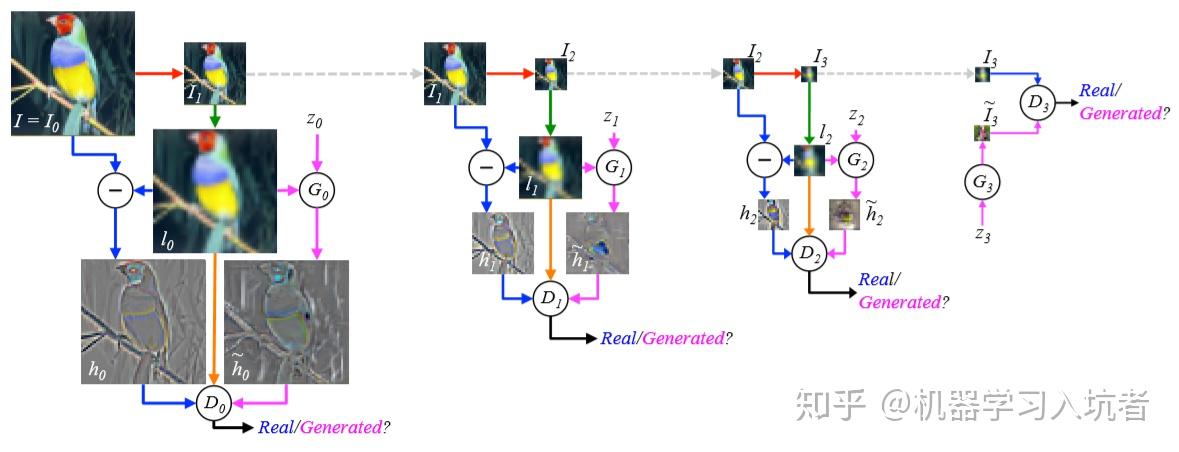
自右向左分析:
(1)从左上方开始,I=I0 是原始 64x64 图像,通过模糊和下采样获得 I1(红色箭头);
(2)对 I1 上采样得到 I0 的低通版本 L0(I0 右下方的模糊图像),此过程为绿色箭头;
(3)对于 L0,以等概率的情况创建真实 h0(为蓝色箭头)或者生成的 h0~=G(z0,L0)(为粉红色箭头),L0 总是和真实 h0 与生成的 h0~ 同时送入判别器 D0 中进行真假判别。
所以生成器 G0 的学习目的是生成的图像 h0~ 尽可能接近 h0,通过对后面的网络重复这个过程,就完成了各个网络的独立训练。
四、视觉结果
LAPGAN 在 CIFAR10、STL10 和 LSUN 三个数据集上进行了实验,从实验的视觉结果中可以看出它具有很强的数据分布俘获能力,生成的样本质量较高。其生成的 airplane 图像如下:

可以看出 LAPGAN 生成的图像多样,效果也达到了可以接受的范围。作者进行了人类视觉评估的调查,将网络生成的图片和真实的图片给参数调查的人员,让他们判断所看到的图像是真实的还是伪造的,得到了下面的分类曲线:
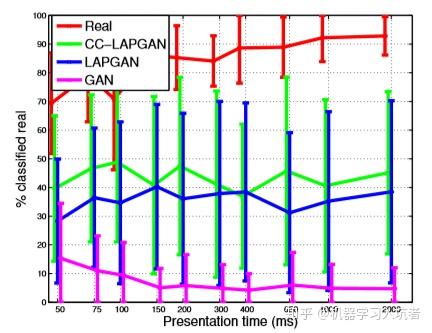
上图中红色的表示真实的图像,人类对它判断为 real 的准确率达到了 90% 左右;蓝色曲线表示人类将 LAPGAN 生成的图片误认为真的可能性,可以看出人类以 40% 左右的概率认为他所看到的图像是真实的,而不是伪造的,这说明 LAPGAN 生成的图像已经达到了以假乱真的地步。
参考文献:
【1】Denton E L, Chintala S, Fergus R. Deep generative image models using a laplacian pyramid of adversarial networks[C]//Advances in neural information processing systems. 2015: 1486-1494.
【2】Burt P, Adelson E. The Laplacian pyramid as a compact image code[J]. IEEE Transactions on communications, 1983, 31(4): 532-540.
LAPGAN 论文下载地址: