浏览器中的 JavaScript执行机制:07 | 变量提升:JavaScript代码是按顺序执行的吗?
前言:该篇说明:请见 说明 —— 浏览器工作原理与实践 目录
讲解完宏观视角下的浏览器后,从这篇文章开始,我们就进入下一个新的模块了,这里我会对 JavaScript 执行原理做深入介绍。
今天在该模块的第一篇文章,我们主要讲解执行上下文相关的内容。那为什么先讲执行上下文呢?它这么重要吗?可以这么说,只有理解了 JavaScript 的执行上下文,你才能更好地理解 JavaScript 语言本身,比如变量提升、作用域和闭包等。不仅如此,理解执行上下文和调用栈的概念还能助你成为一名更合格的前端开发者。
不过由于我们专栏不是专门讲 JavaScript 语言的,所以我并不会对 JavaScript 语法本身做过多介绍。本文主要是从 JavaScript 的顺序执行讲起,然后一步步带你了解 JavaScript 是怎么运行的。
接下来咱们先看段代码,你觉得下面这段代码输出的结果是什么?

showName() console.log(myname) var myname = '极客时间'
function showName() { console.log('函数showName被执行'); }
使用过 JavaScript 开发的程序员应该都知道,JavaScript 是按顺序执行的。若按照这个逻辑来理解的话,那么:
- 当执行到第 1 行的时候,由于函数 showName 还没有定义,所以执行应该会报错;
- 当执行到第 2 行的时候,由于变量 myname 也未定义,所以同样也会报错。
然而实际执行结果却并非如此,如下图:
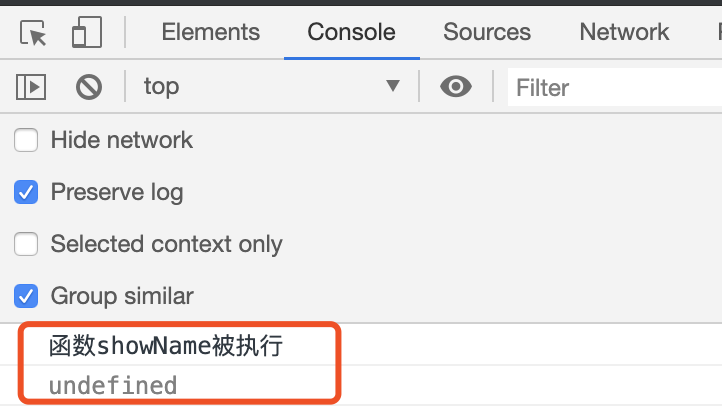
在声明之前使用函数和变量的执行结果
第 1 行输出 “函数 showName 被执行”, 第 2 行输出 “undefined”,这和前面想象中的顺序执行有点不一样啊!
通过上面的执行结果,你应该已经知道了函数或者变量可以在定义之前使用,那如果使用没有定义的变量或者函数,JavaScript 代码还能继续执行吗?为了验证这点,我们可以删除第 3 行变量 myname 的定义,如下所示:
showName()
console.log(myname)
function showName() {
console.log('函数showName被执行');
}
然后再次执行这段代码时,JavaScript 引擎就会报错,结果如下:
![]()
使用了未定义的变量——执行报错
从上面两段代码的执行结果来看,我们可以得出如下三个结论。
1、在执行过程中,若使用了未声明的变量,那么 JavaScript 执行会报错。
2、在一个变量定义之前使用它,不会报错,但是该变量的值会为 undefined,而不是定义时的值。
3、在一个函数定义之前使用它,不会报错,且函数能正确执行。
第一个结论很好理解,因为变量没有定义,这样在执行 JavaScript 代码时,就找不到该变量,所以 JavaScript 会抛出错误。
但是对于第二个和第三个结论,就挺让人费解的:
- 变量和函数为什么能在其定义之前使用?这似乎表明 JavaScript 代码并不是一行一行执行的。
- 同样的方式,变量和函数的处理结果为什么不一样?比如上面的执行结果,提前使用的 showName 函数能打印出完整结果,但是提前使用的 myname 变量值却是 undefined,而不是定义时使用的 “极客时间” 这个值。
变量提升
要解释这两个问题 ,你就需要先了解什么是变量提升。
不过在介绍变量提升之前,我们先通过下面这段代码,来看看什么是 JavaScript 中的声明和赋值。
var myname = '极客时间'
这段代码你可以把它看成是两行代码组成的:
var myname //声明部分 myname = '极客时间' //赋值部分
如下图所示:
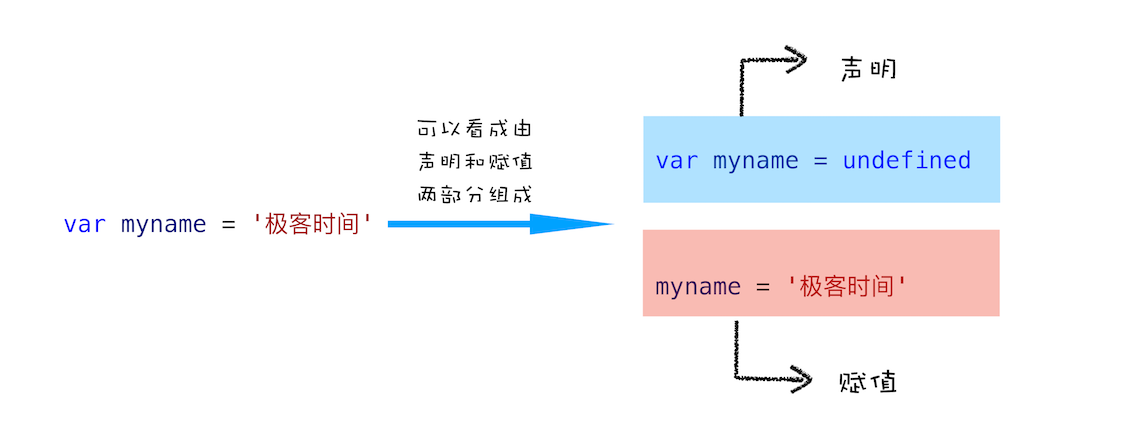
如何理解 “var myname = '极客时间' ”
上面是变量的声明和赋值,那接下来我们再来看看函数的声明和赋值,结合下面这段代码:
function foo(){
console.log('foo')
}
var bar = function(){
console.log('bar')
}
第一个函数 foo 是一个完整的函数声明,也就是说没有涉及到赋值操作;第二个函数是先声明变量 bar,再把 function(){console.log('bar')} 赋值给 bar。为了直观理解,你可以参考下图:
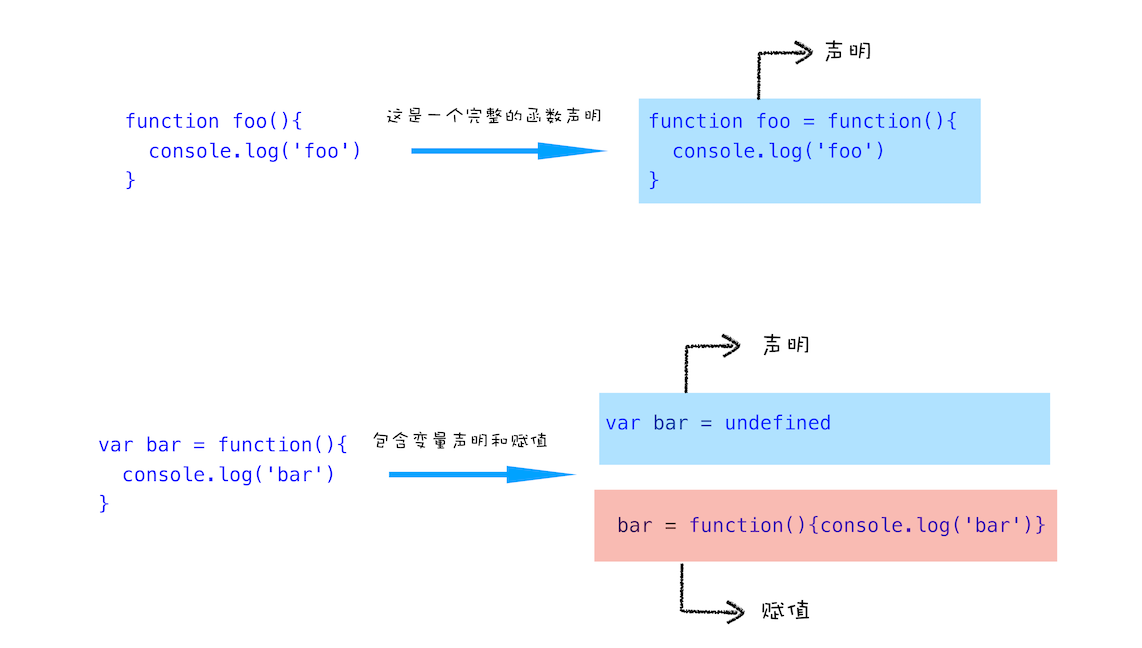
函数的声明和赋值
好了,理解了声明和赋值操作,那接下来我们就可以聊聊什么是变量提升了。
所谓的变量提升,是指在 JavaScript 代码执行过程中,JavaScript 引擎把变量的声明部分和函数的声明部分提升到代码开头的 “行为”。变量被提升后,会给变量设置默认值,这个默认值就是我们熟悉的 undefined。
下面我们来模拟下实现:
/*
* 变量提升部分
*/
// 把变量 myname提升到开头,
// 同时给myname赋值为undefined
var myname = undefined
// 把函数showName提升到开头
function showName() {
console.log('showName被调用');
}
/*
* 可执行代码部分
*/
showName()
console.log(myname)
// 去掉var声明部分,保留赋值语句
myname = '极客时间'
为了模拟变量提升的效果,我们对代码做了以下调整,如下图:
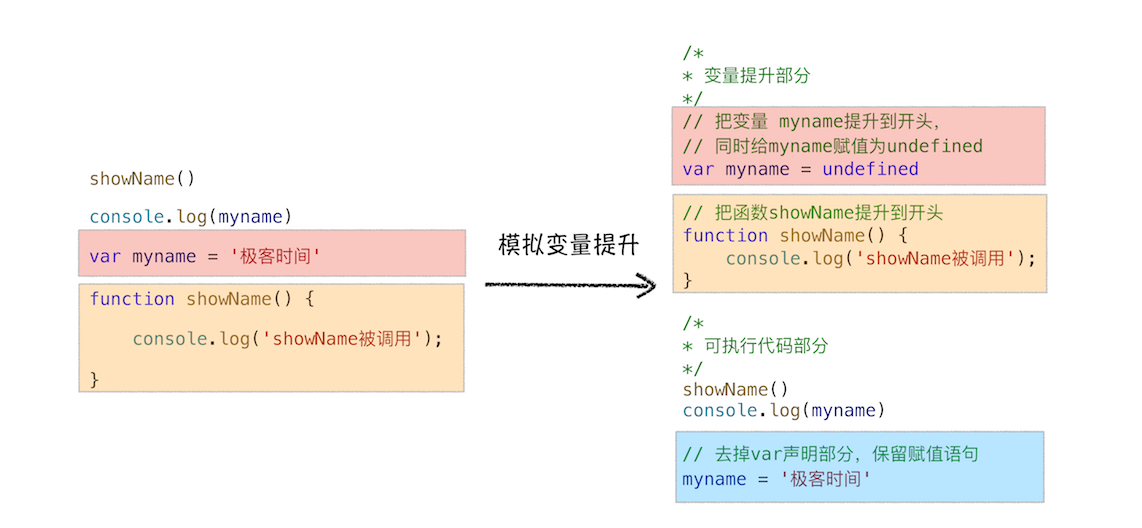
模拟变量提升示意图
从图中可以看出,对原来的代码主要做了两处调整:
- 第一处是把声明的部分都提升到了代码开头,如变量 myname 和函数 showName,并给变量设置默认值 undefined;
- 第二处是移除原本声明的变量和函数,如 var myname = '极客时间' 的语句,移除了 var 声明,整个移除 showName 的函数声明。
通过这两步,就可以实现变量提升的效果。你也可以执行这段模拟变量提升的代码,其输出结果和第一段代码应该是完全一样的。
通过这段模拟的变量提升代码,相信你已经明白了可以在定义之前使用变量或者函数的原因——函数和变量在执行之前都提升到了代码开头。
JavaScript 代码的执行流程
从概念的字面意义上来看,“变量提升” 意味着变量和函数的声明会在物理层面移动到代码的最前面,正如我们所模拟的那样。但,这并不准确。实际上变量和函数声明在代码里的位置是不会改变的,而是在编译阶段被 JavaScript 引擎放入内存中。对,你没听错,一段 JavaScript 代码在执行之前需要被 JavaScript 引擎编译,编译完成之后,才会进入执行阶段。大致流程你可以参考下图:

JavaScript 的执行流程图
1. 编译阶段
那么编译阶段和变量提升存在什么关系呢?
为了搞清楚这个问题,我们还是回过头来看上面那段模拟变量提升的代码,为了方便介绍,可以把这段代码分为两部分。
第一部分:变量提升部分的代码。
var myname = undefined
function showName() {
console.log('函数showName被执行');
}
第二部分:执行部分的代码。
showName() console.log(myname) myname = '极客时间'
下面我们就可以把 JavaScript 的执行流程细化,如下图所示:
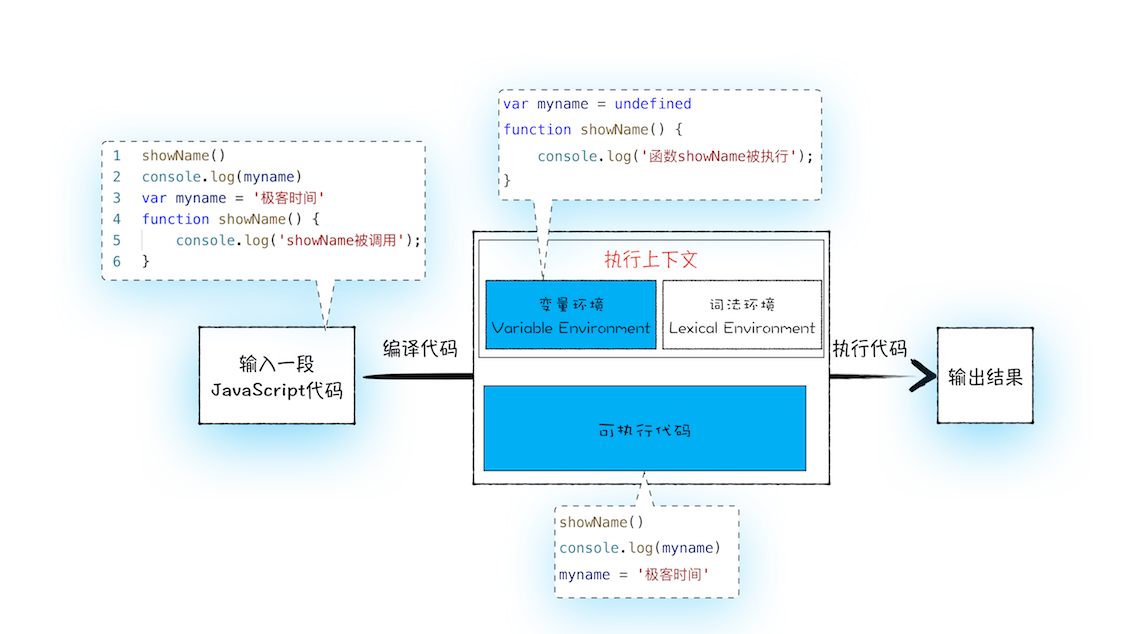
JavaScript 执行流程细化图
从上图可以看出,输入一段代码,经过编译后,会生成两部分内容:执行上下文(Execution context)和 可执行代码。
执行上下文 是 JavaScript 执行一段代码时的运行环境,比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的诸如 this、变量、对象以及函数等。
关于执行上下文的细节,我会在下一篇文章《08 | 调用栈:为什么 JavaScript 代码会出现栈溢出?》做详细介绍,现在你只需要知道,在执行上下文中存在一个变量环境的对象(Viriable Environment),该对象中保存了变量提升的内容,比如上面代码中的变量 myname 和函数 showName,都保存在该对象中。
你可以简单地把变量环境对象看成是如下结构:
VariableEnvironment:
myname -> undefined,
showName -> function : { console.log(myname) }
了解完变量环境对象的结构后,接下来,我们再结合下面这段代码来分析下是如何生成变量环境对象的。
showName()
console.log(myname)
var myname = '极客时间'
function showName(){
console.log('函数showName被执行')
}
我们可以一行一行来分析上述代码:
第 1 行 和 第 2 行,由于这两行代码不是声明操作,所以 JavaScript 引擎不会做任何处理;
第 3 行,由于这行是经过 var 声明的,因此 JavaScript 引擎将在环境对象中创建一个名为 myname 的属性,并使用 undefined 对其初始化;
第 4 行, JavaScript 引擎发现了一个通过 function 定义的函数,所以它将函数定义存储到堆(HEAP)中,并在环境对象中创建一个 showName 的属性,然后将该属性值指向堆中函数的位置(不了解堆也没关系,JavaScript 的执行堆和执行栈我会在后续文章中介绍。)
这样就生成了变量环境对象。接下来 JavaScript 引擎会把声明以外的代码编译为字节码,至于字节码的细节,我也会在后面文章中做详细介绍,你可以类比如下的模拟代码:
showName() console.log(myname) myname = '极客时间'
好了,现在有了执行上下文和可执行代码了,那么接下来就到了执行阶段了。
2. 执行阶段
JavaScript 引擎开始执行 “可执行代码”,按照顺序一行一行地执行。下面我们就来一行一行分析下这个执行过程:
- 当执行到 showName 函数时,JavaScript 引擎便开始在变量环境对象中查找该函数,由于变量环境对象中存在函数的引用,所以 JavaScript 引擎便开始执行该函数,并输出 “函数 showName 被执行” 结果。
- 接下来打印 “myname” 信息,JavaScript 引擎继续在变量环境对象中查找该对象,由于变量环境存在 myname 变量,并且其值为 undefined,所以这时候就输出 undefined。
- 接下来执行第 3 行,把 “极客时间” 赋给 myname 变量,赋值后变量环境中的 myname 属性值改变为 “极客时间”,变量环境如下所示:
VariableEnvironment:
myname -> "极客时间",
showName -> function : { console.log(myname) }
好了,以上就是一段代码的编译和执行流程。实际上,编译阶段和执行阶段都是非常复杂的,包括了词法分析、语法解析、代码优化、代码生成等,这些内容我会在《14 | 编译器和解释器: V8是如何执行一段 JavaScript 代码的?》那节详细介绍,在本篇文章中你只需要知道 JavaScript 代码经过编译生成了什么内容就可以了。
代码中出现相同的变量或者函数怎么办?
现在你已经知道了,在执行一段 JavaScript 代码之前,会编译代码,并将代码中的函数和变量保存到执行上下文的变量环境中,那么如果代码中出现了重名的函数或者变量,JavaScript 引擎会如何处理?
我们先看下面这样一段代码:
function showName() {
console.log('极客邦');
}
showName();
function showName() {
console.log('极客时间');
}
showName();
在上面代码中,我们先定义了一个 showName 的函数,该函数打印出来 “极客邦”;然后调用 showName,并定义了一个 showName 函数,这个 showName 函数打印出来的是 “极客时间”;最后接着继续调用 showName。那么你能分析出来这两次调用打印出来的值是什么吗?
我们来分析下其完整执行流程:
- 首先是编译阶段。遇到了第一个 showName 函数,会将该函数体存放到变量环境中。接下来是第二个 showName 函数,继续存放至变量环境中,但是变量环境中已经存在一个 showName 函数了,此时,第二个 showName 函数会将第一个 showName 函数覆盖掉。这样变量环境中就只存在第二个 showName 函数了。
- 接下来是执行阶段。先执行第一个 showName 函数,但由于是从变量环境中查找 showName 函数,而变量环境中只保存了第二个 showName 函数,所以最终调用的是第二个函数,打印的内容是 “极客时间”。第二次执行 showName 函数也是走同样的流程,所以输出的结果也是 “极客时间”。
综上所述,一段代码如果定义了两个相同名字的函数,那么最终生效的是最后一个函数。
总结
好了,今天就到这里,下面我来简单总结下今天的主要内容:
- JavaScript 代码执行过程中,需要先做变量提升,而之所以需要实现变量提升,是因为 JavaScript 代码在执行之前需要先编译。
- 在编译阶段,变量和函数会被存放到变量环境中,变量的默认值会被设置为 undefined;在代码执行阶段,JavaScript 引擎会从变量环境中去查找自定义的变量和函数。
- 如果在编译阶段,存在两个相同的函数,那么最终存放在变量环境中的是最后定义的那个,这是因为后定义的会覆盖掉之前定义的。
以上就是今天所讲的主要内容,当然,学习这些内容并不是让你掌握一些 JavaScript 小技巧,其主要目的是让你清楚 JavaScript 的执行机制:先编译,再执行。
如果你了解了 JavaScript 执行流程,那么在编写代码时,你就能避开一些陷阱;在分析代码过程中,也能通过分析 JavaScript 的执行过程来定位问题。
思考时间
最后,看下面这段代码:
showName()
var showName = function() {
console.log(2)
}
function showName() {
console.log(1)
}
你能按照 JavaScript 的执行流程,来分析最终输出结果吗?
答案:
编译阶段:变量提升
var showName
function showName(){ console.log(1) }
执行阶段:JavaScript引擎按照顺序一行一行执行。
show() // 所以此处输出 1
showName = function(){ console.log(2) }
// 如果后面再有 showName() 执行的话,就会输出 2,因为此时函数引用已经变了
问题记录
1、老师,head头部引入的js文件,也是先编译的吗?
作者回复: 我先来解释下页面在含有JavaScript的情况下DOM解析流程,然后再来解释你这个问题。
当从服务器接收HTML页面的第一批数据时,DOM解析器就开始工作了,在解析过程中,如果遇到了JS脚本,如下所示:
<html>
<body>
极客时间
<script>
document.write("--foo")
</script>
</body>
</html>
那么DOM解析器会先执行JavaScript脚本,执行完成之后,再继续往下解析。
那么第二种情况复杂点了,我们内联的脚本替换成js外部文件,如下所示:
<html>
<body>
极客时间
<script type="text/javascript" src="foo.js"></script>
</body>
</html>
这种情况下,当解析到JavaScript的时候,会先暂停DOM解析,并下载foo.js文件,下载完成之后执行该段JS文件,然后再继续往下解析DOM。这就是JavaScript文件为什么会阻塞DOM渲染。
我们再看第三种情况,还是看下面代码:
<html>
<head>
<style type="text/css" src = "theme.css" />
</head>
<body>
<p>极客时间</p>
<script>
let e = document.getElementsByTagName('p')[0]
e.style.color = 'blue'
</script>
</body>
</html>
当我在JavaScript中访问了某个元素的样式,那么这时候就需要等待这个样式被下载完成才能继续往下执行,所以在这种情况下,CSS也会阻塞DOM的解析。
所以这时候如果头部包含了js文件,那么同样也会暂停DOM解析,等带该JavaScript文件下载后,便开始编译执行该文件,执行结束之后,才开始继续DOM解析。
2、老师好,请教您一个问题。
debugger;
(function(){
console.log(g)
if(true){
console.log('hello world');
function g(){ return true; }
}
})();
这个函数步进调试时,发现打印g时值是undefined而不是提示not defined,说明if中g函数确实是提升了,但是为何不是g()而是undefined?然后走完function g(){ return true; }这一步后 console.log(g)中的g才变为g()。这里条件声明函数的变量提升有点搞不明白。
作者回复:
ES规定函数只不能在块级作用域中声明,
function foo(){
if(true){
console.log('hello world');
function g(){ return true; }
}
}
也就是说,上面这行代码执行会报错,但是个大浏览器都没有遵守这个标准。
接下来到了ES6了,ES6明确支持块级作用域,ES6规定块级作用域内部声明的函数,和通过let声明变量的行为类似。
规定的是理想的,但是还要照顾实现,要是完全按照let的方式来修订,会影响到以前老的代码,所以为了向下兼容,个大浏览器基本是按照下面的方式来实现的:
function foo(){
if(true){
console.log('hello world');
var g = function(){return true;}
}
}
这就解释了你的疑问,不过还是不建议在块级作用域中定义函数,很多时候,简单的才是最好的。
3、老师,如果把两个函数调换个儿。那么先声明function,然后把 showName 赋值 undefined,undefined不会覆盖函数声明。这是为什么?
console.log(showName.toString())
function showName() {
console.log(1)
}
var showName = function() {
console.log(2)
}
打印的是函数体,而非undefined,证明 undefined 不会覆盖函数声明!!
作者回复: 对 是这样的,下面是关于同名变量和函数的两点处理原则: 1:如果是同名的函数,JavaScript编译阶段会选择最后声明的那个。 2:如果变量和函数同名,那么在编译阶段,变量的声明会被忽略。
4、函数提升要比变量提升的优先级要高一些,且不会被变量声明覆盖,但是会被变量赋值之后覆盖。
作者回复: 对
5、
x = 10 + 20;
console.log(x);
若对 x 未进行定义, 直接赋值, 可以输出
若按照课程理解并假设
编译阶段会有一个
x = undefine
但是
console.log(x);
x = 10 + 20;
console.log(x);
会出现报错 x is not defined
在这个地方 我的理解有什么问题吗 还是说 原来就没有 x = undefine 操作, 只是在 x = 10 + 20; 给 x 赋值了一下.
作者回复: 需要通过 var x 声明才会在编译期间提升
6、老师我想问下,一段javascript代码进入编译阶段是会对函数体内的代码也进行编译,还是只是将函数体的代码存储在堆,在执行中遇到该函数再去编译?
作者回复: 记住一点就行:函数只有在调用的时候才会被编译。
浏览器中的JavaScript执行机制:08 | 调用栈:为什么JavaScript代码会出现栈溢出?
前言:该篇说明:请见 说明 —— 浏览器工作原理与实践 目录
在上篇文章中,我们讲到了,当一段代码被执行时,JavaScript 引擎先会对其进行编译,并创建执行上下文。但是并没有明确说明到底什么样的代码才算符合规范。
那么接下来我们就来明确下,哪些情况下代码才算是“一段”代码,才会在执行之前就进行编译并创建执行上下文。一般说来,有这么三种情况:
1、当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生存周期内,全局执行上下文只有一份。
2、当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁。
3、当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
好了,又进一步理解了执行上下文,那本节我们就在这基础之上继续深入,一起聊聊调用栈。学习调用栈至少有以下三点好处:
1、可以帮助你了解 JavaScript 引擎背后的工作原理;
2、让你有调试 JavaScript 代码的能力;
3、帮助你搞定面试,因为面试过程中,调用栈也是出镜率非常高的题目。
比如你在写 JavaScript 代码的时候,有时候可能会遇到栈溢出的错误,如下图所示:
栈溢出的错误
那为什么会出现这种错误呢?这就涉及到了调用栈的内容。你应该知道 JavaScript 中有很多函数,经常会出现在一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构。因此要讲清楚调用栈,你还要先弄明白函数调用和栈结构。
什么是函数调用
函数调用就是运行一个函数,具体使用方式是使用函数名称跟着一对小括号。下面我们看个简单的示例代码:
var a = 2
function add() {
var b = 10
return a+b
}
add()
这段代码很简单,先是创建了一个 add 函数,接着在代码的最下面又调用了该函数。
那么下面我们就利用这段简单的代码来解释下函数调用的过程。
在执行到函数 add() 之前,JavaScript 引擎会为上面这段代码创建全局执行上下文,包含了声明的函数和变量,你可以参考下图:
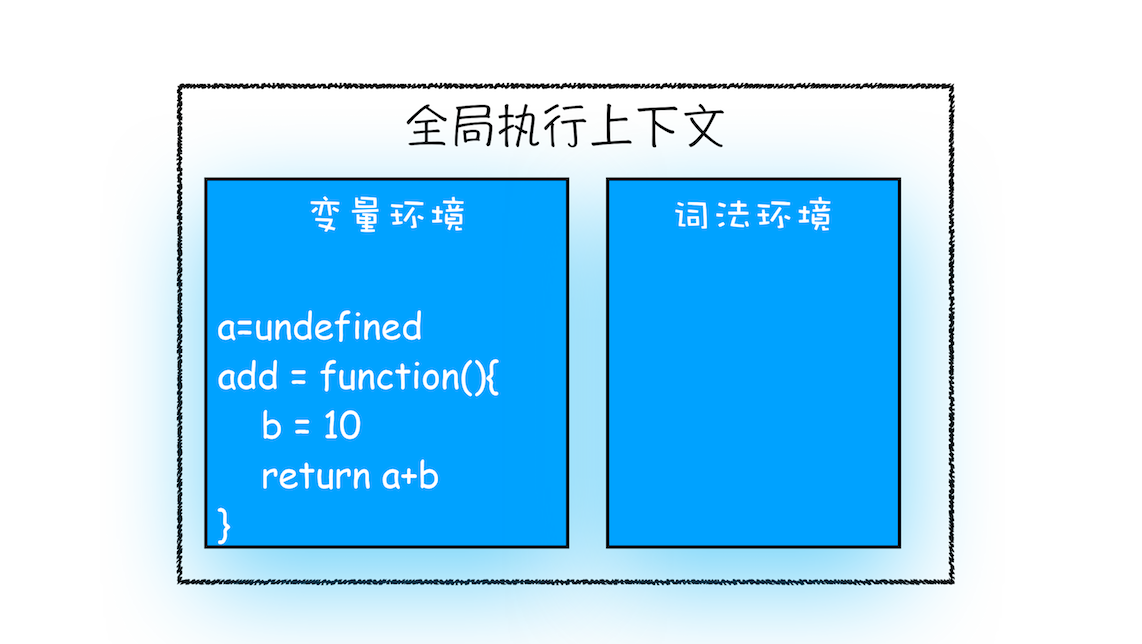
全局执行上下文
从图中可以看出,代码中全局变量和函数都保存在全局上下文的变量环境中。
执行上下文准备好之后,便开始执行全局代码,当执行到 add 这时,JavaScript 判断这是一个函数调用,那么将执行以下操作:
- 首先,从全局执行上下文中,取出 add 函数代码。
- 其次,对 add 函数的这段代码进行编译,并创建该函数的执行上下文和可执行代码。
- 最后,执行代码,输出结果。
完整流程你可以参考下图:
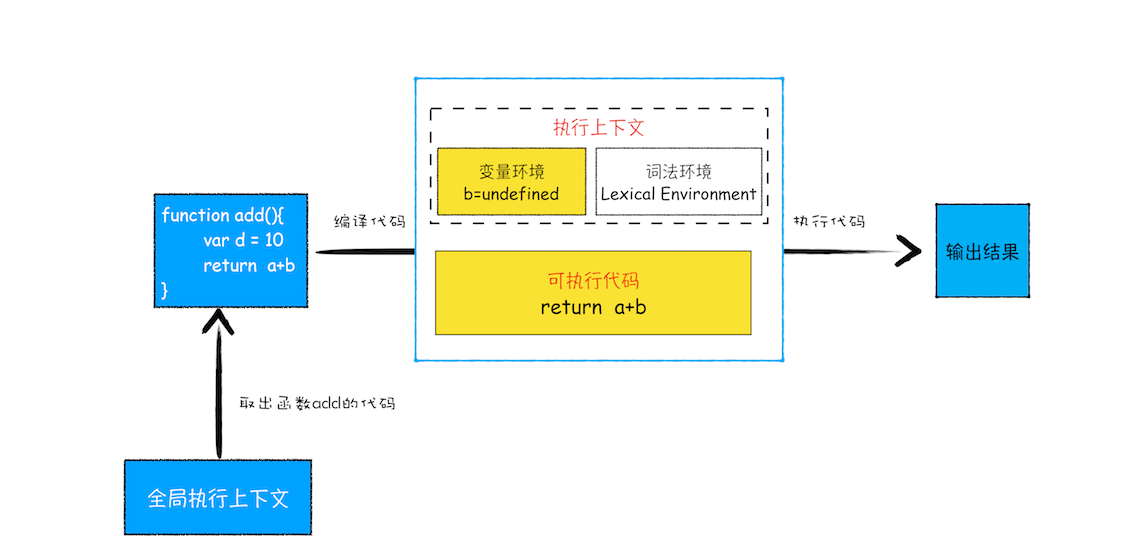
函数调用过程
就这样,当执行到 add 函数的时候,我们就有了两个执行上下文了 —— 全局执行上下文和 add 函数的执行上下文。
也就是说在执行 JavaScript 时,可能会存在多个执行上下文,那么JavaScript 引擎是如何管理这些执行上下文的呢?
答案是通过一种叫栈的数据结构来管理的。那什么是栈呢?它又是如何管理这些执行上下文呢?
什么是栈
关于栈,你可以结合这么一个贴切的例子来理解,一条单车道的单行线,一端被堵住了,而另一端入口处没有任何提示信息,堵住之后就只能后进去的车子先出来,这时这个堵住的单行线就可以被看作是一个栈容器,车子开进单行线的操作叫做入栈,车子倒出去的操作叫做出栈。
在车流量较大的场景中,就会发生反复的入栈、栈满、出栈、空栈和再次入栈,一直循环。
所以,栈就是类似于一端被堵住的单行线,车子类似于栈中的元素,栈中的元素满足先进后出的特点。你可以参考下图:
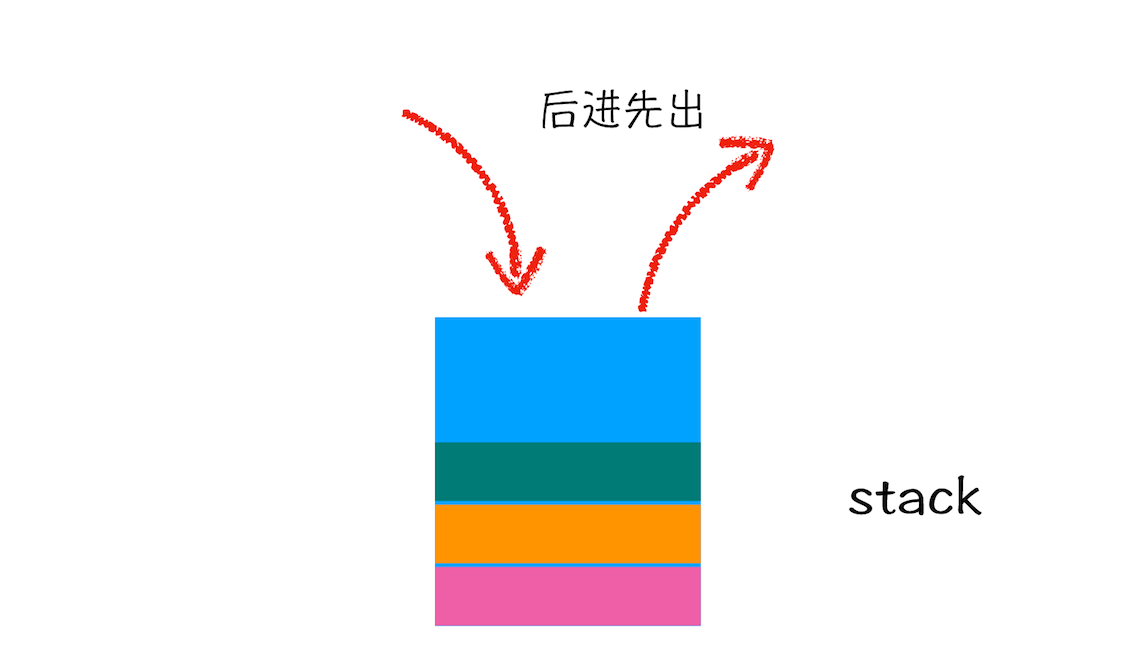
栈示意图
什么是 JavaScript 的调用栈
JavaScript 引擎正是利用栈的这种结构来管理执行上下文的。在执行上下文创建好后,JavaScript 引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。
为便于你更好地理解调用栈,下面我们再来看段稍微复杂点的示例代码:
var a = 2
function add(b, c){
return b+c
}
function addAll(b, c){
var d = 10
result = add(b, c)
return a+result+d
}
addAll(3, 6)
在上面这段代码中,你可以看到它是在 addAll 函数中调用了 add 函数,那在整个代码的执行过程中,调用栈是怎么变化的呢?
下面我们就一步步地分析在代码的执行过程中,调用栈的状态变化情况。
第一步:创建全局上下文,并将其压入栈底。如下图所示:
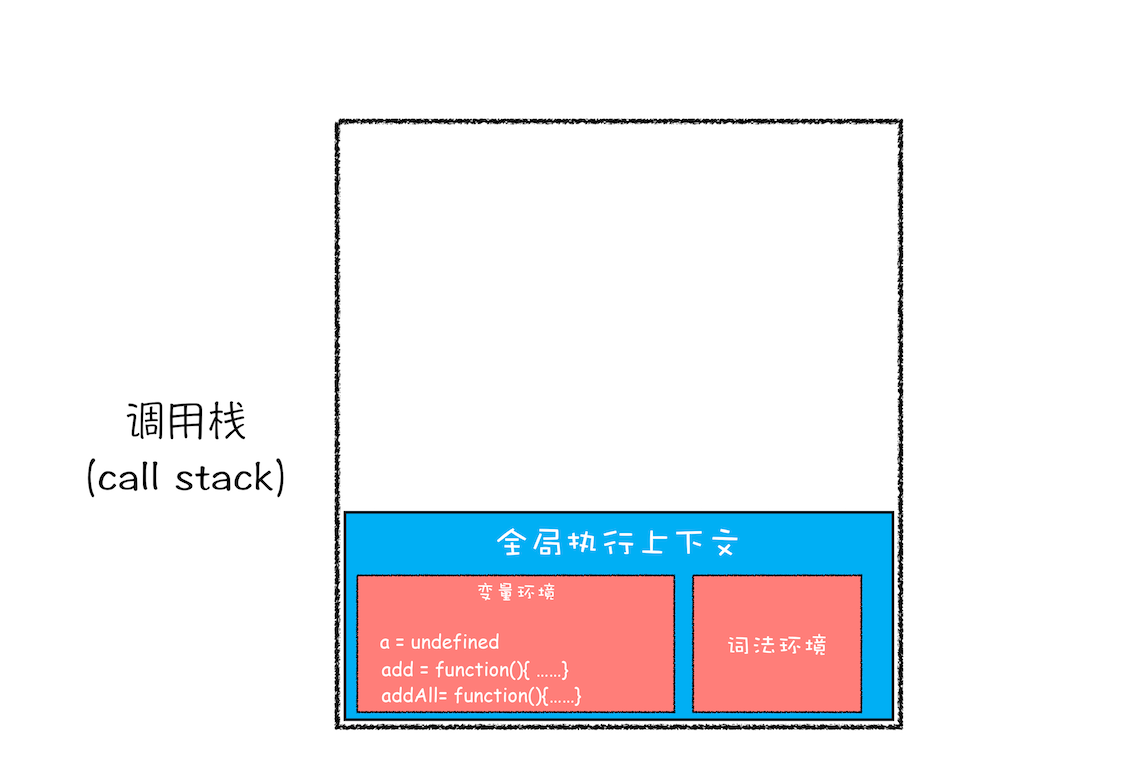
全局执行上下文压栈
从图中你也可以看出,变量 a、函数 add 和 addAll 都保存到了全局上下文的变量环境对象中。
全局执行上下文压入到调用栈后,JavaScript 引擎便开始执行全局代码了。首先会执行 a=2 的赋值操作,执行该语句会将全局上下文变量环境中 a 的值设置为 2。设置后的全局上下文的状态如下图所示:
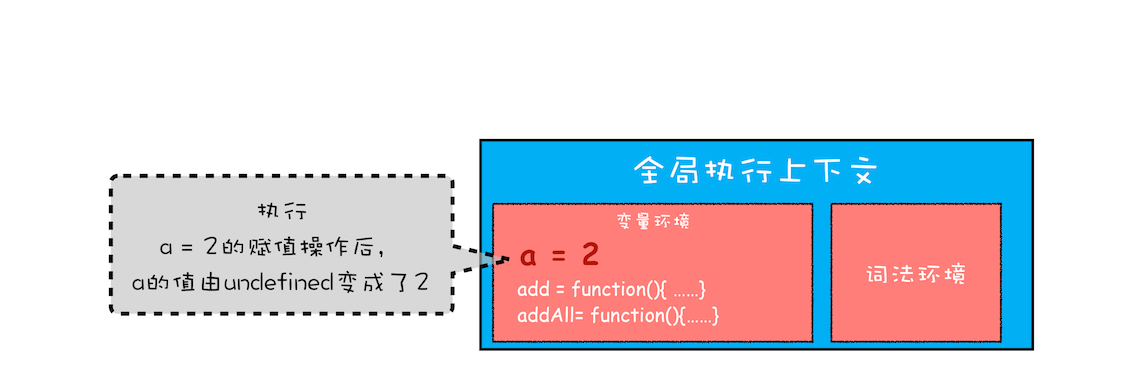
赋值操作改变执行上下文中的值
接下来,第二步是调用 addAll 函数。当调用该函数时,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中,如下图所示:
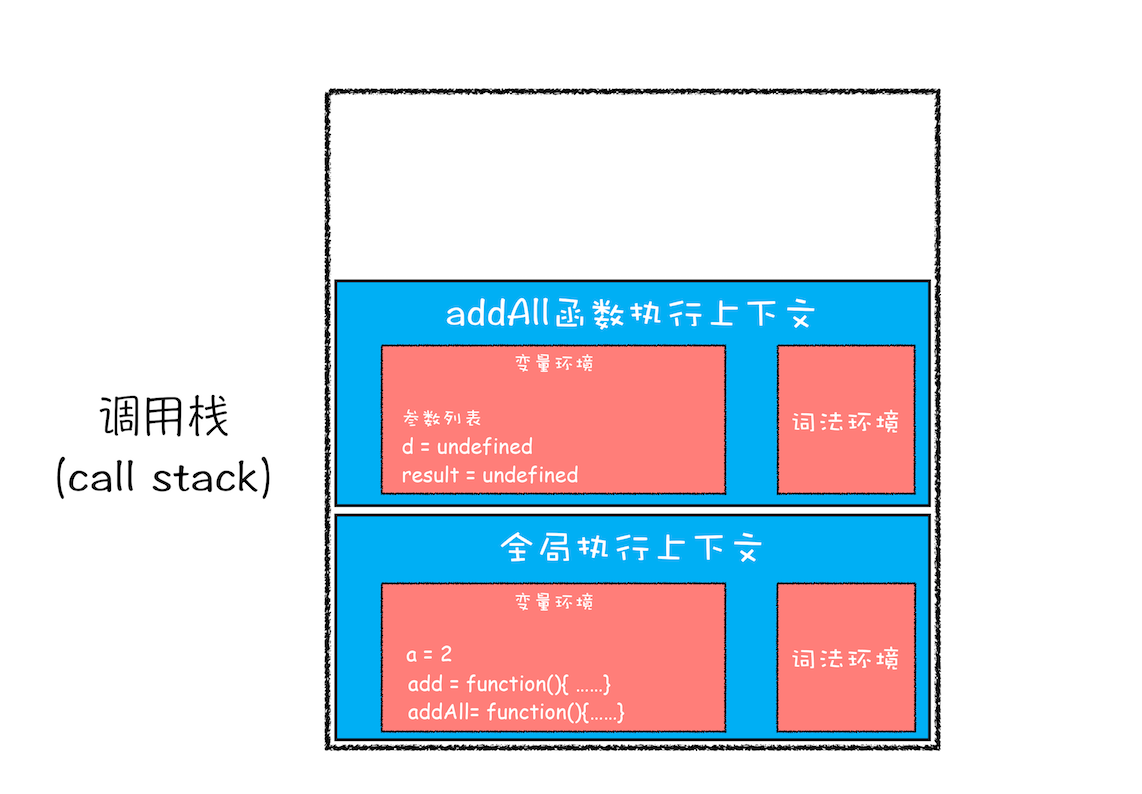
执行 addAll 函数时的调用栈
addAll 函数的执行上下文创建好之后,便进入了函数代码的执行阶段了,这里先执行的是 d=10 的赋值操作,执行语句会将 addAll 函数执行上下文中的 d 由 undefined 变成了 10。
然后接着往下执行,第三部,当执行到 add 函数调用语句时,同样会为其创建执行上下文,并将其压入调用栈,如下图所示:
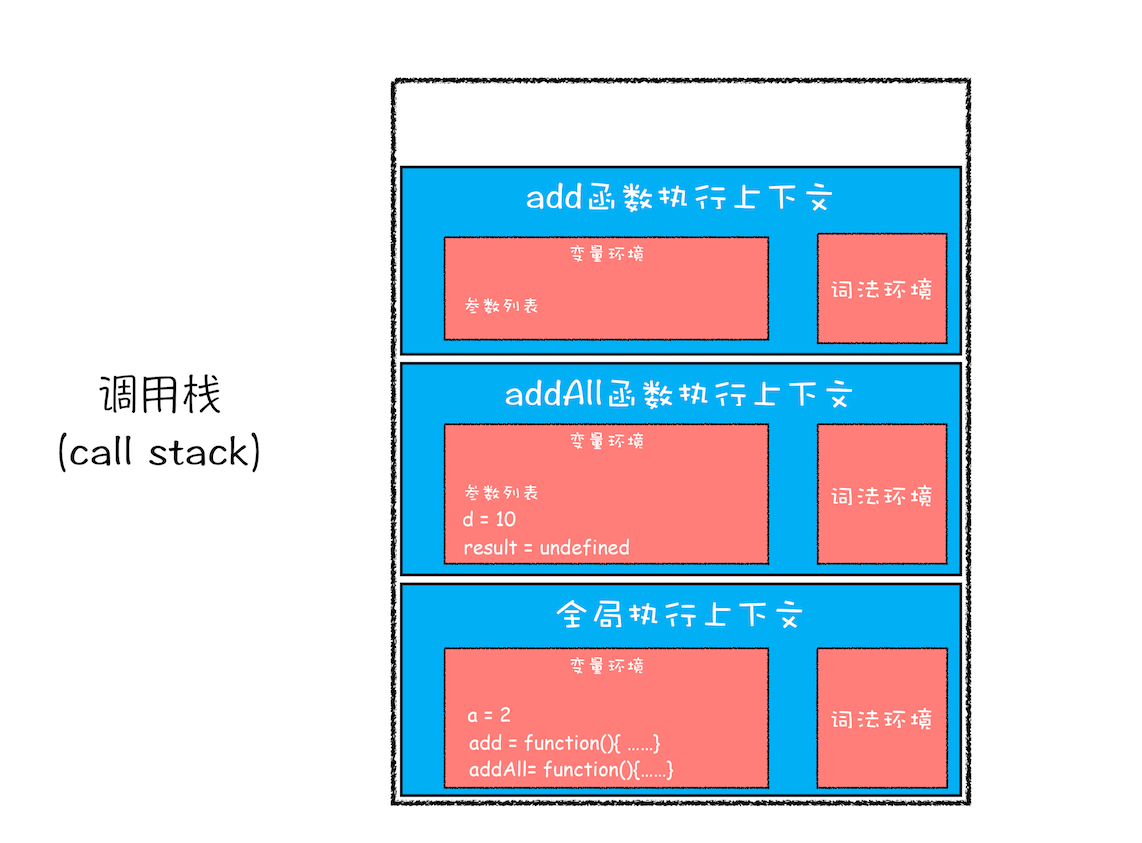
执行 add 函数时的调用栈
当 add 函数返回时,该函数的执行上下文就会从栈顶弹出,并将 result 的值设置为 add 函数的返回值,也就是 9。如下图所示:
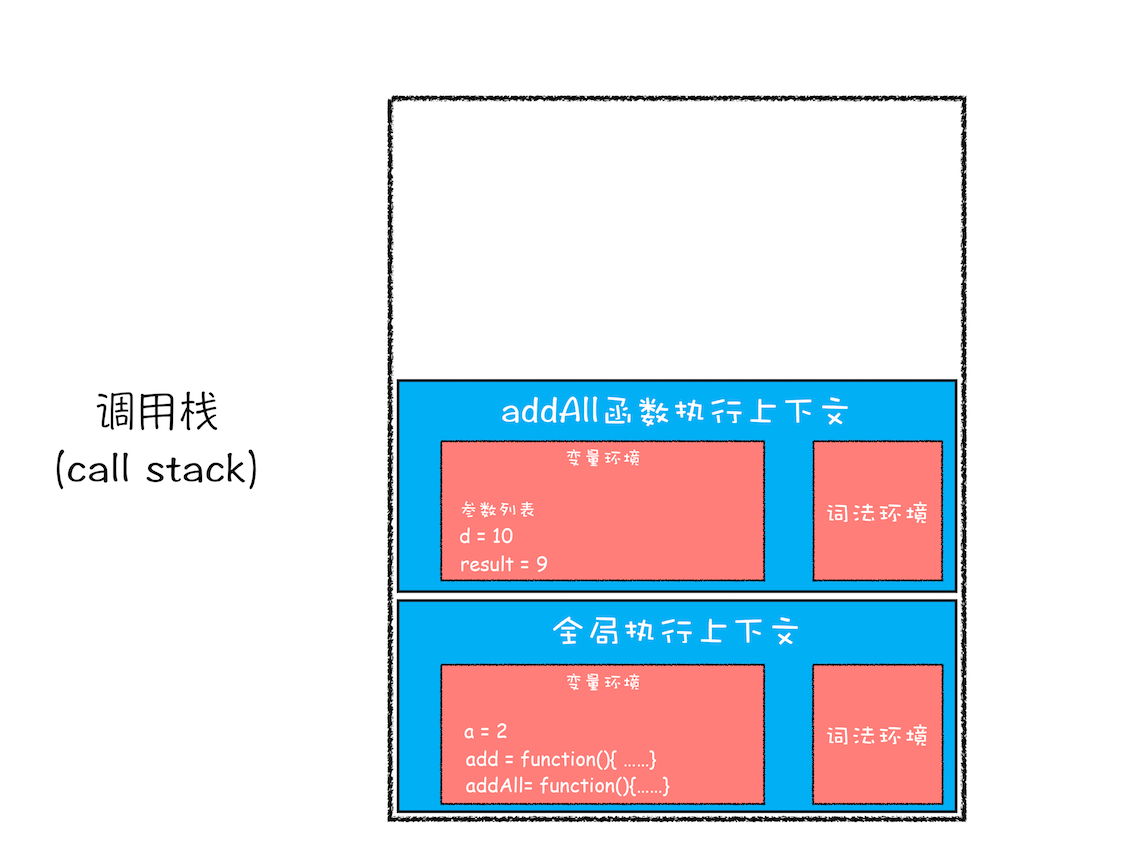
add 函数执行结束时的调用栈
紧接着 addAll 执行最后一个相加操作后并返回,addAll 的执行上下文也会从栈顶弹出,此时调用栈中就只剩下全局上下文了。最终如下图所示:
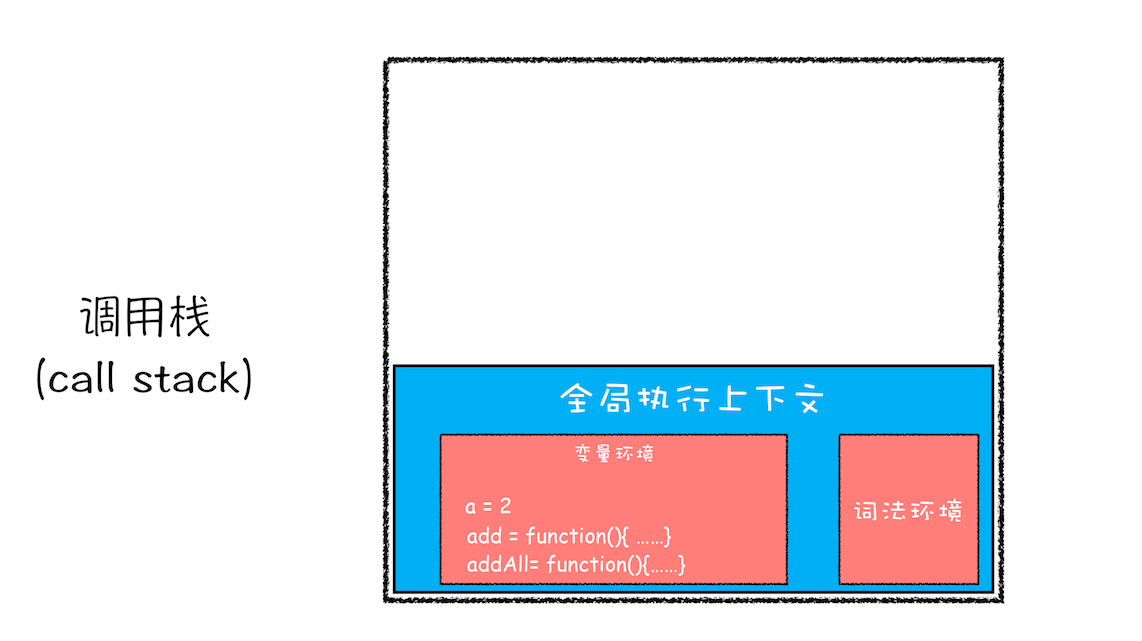
addAll 函数执行结束时的调用栈
至此,整个 JavaScript 流程执行结束了。
好了,现在你应该知道了调用栈是 JavaScript 引擎追踪函数执行的一个机制,当一次有多个函数被调用时,通过调用栈就能够追踪到哪个函数正在被执行以及各函数之间的调用关系。
在开发中,如何利用好调用栈
鉴于调用栈的重要性和实用性,那么接下来我们就一起来看看在实际工作中,应该如何查看和利用好调用栈。
1. 如何利用浏览器查看调用栈的信息
当你执行一段复杂的代码时,你可能很难从代码稳重分析其调用关系,这时候你可以在你想要查看的函数中加入断点,然后当执行到该函数时,就可以查看该函数的调用栈了。
这么说可能有点抽象,这里我们拿上面的那段代码做个演示,你可以打开 “开发者工具” ,点击 “Source” 标签,选择 JavaScript 代码的页面,然后在第 3 行加上断点,并刷新页面。你可以看到执行到 add 函数时,执行流程就暂停了,这里可以通过右边 “call stack” 来查看当前的调用栈的情况,如下图:
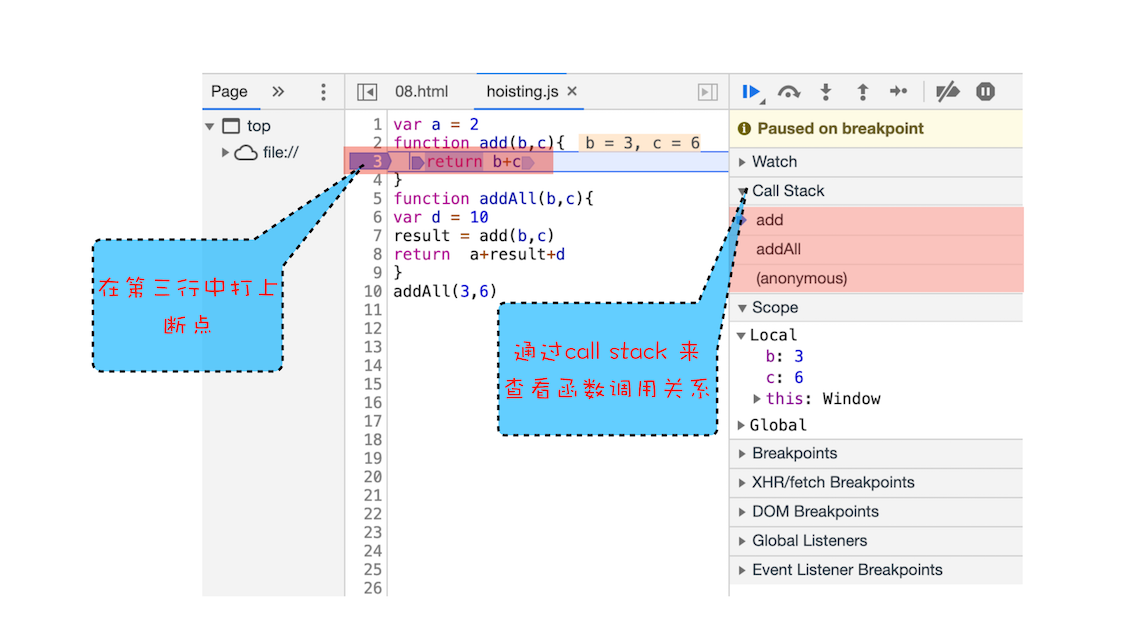
查看函数调用关系
从图中可以看出,右边的 “call stack’ 下面显示出来了函数的调用关系:栈的最底部是 anonymous,也就是全局的函数入口;中间是 addAll 函数;顶部是 add 函数。这就清晰地放映了函数的调用关系,所以在分析复杂结构代码,或者检查 Bug 时,调用栈都是非常有用的。
除了通过断点来查看调用栈,你还可以使用 consol.trace() 来输出当前的函数调用关系,比如在示例代码中的 add 函数里面加上了 console.trace() ,你就可以看到控制台输出的结果,如下图:

使用 trace 函数输出当前调用栈信息
2. 栈溢出(Stack Overflow)
现在你知道了调用栈是一种用来管理执行上下文的数据结构,符合后进先出的规则。不过还有一点你要注意,调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,我们把这种错误叫做栈溢出。
特别是在你写递归代码的时候,就很容易出现栈溢出的情况。比如下面这段代码:
function division(a,b){
return division(a,b)
}
console.log(division(1,2))
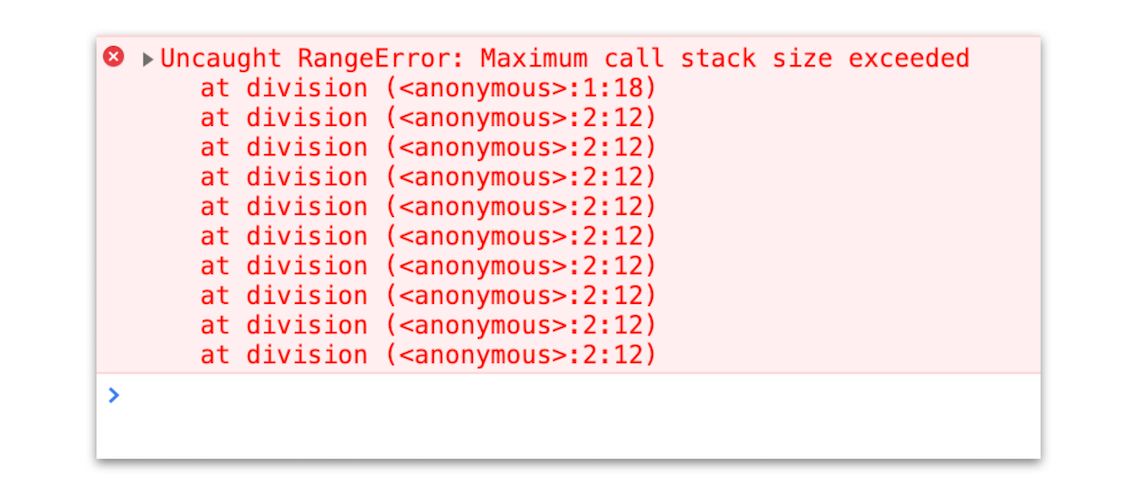
当执行时,就会抛出栈溢出错误,如下图:
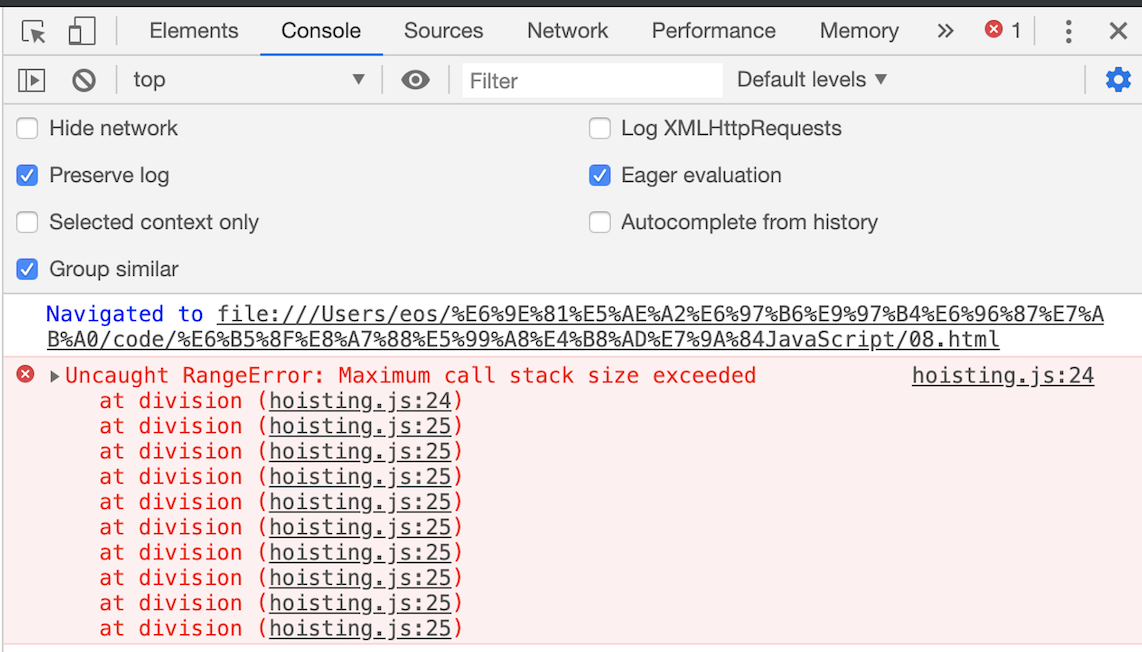
栈溢出错误
从上图你可以看到,抛出的错误信息为:超过了最大栈调用大小(Maximum call stack size exceeded)。
那为什么会出现这个问题呢?这是因为当 JavaScript 引擎开始执行这段代码时,它首先调用函数 division,并创建执行上下文,压入栈中;然而,这个函数是递归的,并且没有任何终止条件,所以它会一直创建新的函数执行上下文,并反复将其压入栈中,但栈是有容量限制的,超过最大数量后就会出现栈溢出的错误。
理解了栈溢出原因后,你就可以使用一些方法来避免或者解决栈溢出的问题,比如把递归调用的形式改造成其他形式,或者使用加入定时器的方法来把当前任务拆分为其他很多小任务。
总结
好了,今天的内容就到这里,下面来总结下今天的内容。
- 每调用一个函数,JavaScript 引擎会为其创建执行上下文,并把该执行上下文压入调用栈,然后 JavaScript 引入开始执行函数代码。
- 如果在一个函数 A 中调用了另外一个函数 B,那么 JavaScript 引擎会为 B 函数创建执行上下文,并将 B 函数的执行上下文压入栈顶。
- 当前函数执行完毕后,JavaScript 引擎会将该函数的执行上下文弹出栈。
- 当分配的调用栈空间被占满时,会引发 “堆栈溢出” 问题。
栈是一种非常重要的数据结构,不光应用在 JavaScript 语言中,其他的编程语言,如 C/C++、Java、Python 等语言,在执行过程中也都使用了栈来管理函数之间的调用关系。所以栈是非常基础且重要的知识点,你必须得掌握。
思考时间
最后,我给你留个思考题,你可以看下面这段代码:(作者的意思:runStack要执行50000次的,但是要避免栈溢出,改成斐波那契数列的列子可能好点)
function runStack (n) {
if (n === 0) return 100;
return runStack( n- 2);
}
runStack(50000)
这是一段递归代码,可以通过传入参数 n,让代码递归执行 n 次,也就意味着调用栈的深度能达到 n,当输入一个较大的数时,比如 50000,就会出现栈溢出的问题,那么你能优化下这段代码,以解决栈溢出的问题吗?
问题记录
1、关于调用栈的大小,不用的平台,比如浏览器,nodejs 怎么查看设置的,还是硬编码的?
作者回复: 调用栈有两个指标,最大栈容量和最大调用深度,满足其中任意一个就会栈溢出,
不过具体多大和多深,这个没有研究过,你可以拿我留的作业那段代码去各平台测试下,应该很快
就能测试出来最大调用深度。
浏览器中的JavaScript执行机制:09 | 块级作用域:var缺陷以及为什么要引入let和const?
前言:该篇说明:|请见 说明 —— 浏览器工作原理与实践 目录
在前面《07 | 变量提升:JavaScript 代码是按照顺序执行的吗?》这篇文章中,我们已经讲解了 JavaScript 中变量提升的相关内容,正是由于 JavaScript 存在变量提升这种特性,从而导致了很多于直觉不符的代码,这也是 JavaScript 的一个重要设计缺陷。
虽然 ECMAScript6(以下简称 ES6 )已经通过引入块级作用域并配合 let、const 关键字,来避开了这种设计缺陷,但是由于 JavaScript 需要保持向下兼容,所以变量提升在相当长一段时间内还会继续存在。这也加大了你理解概念的难度,因为既要理解新的机制,又要理解变量提升这套机制,关键这两套机制还是同时运行在 “一套” 系统中的。
但如果抛开 JavaScript 的底层去理解这些,那么你大概率会很难深入理解其概念。俗话说,“断病要断因,治病要治根”,所以为了便于你更好地理解和学习,今天我们这篇文忠会先 “探病因” —— 分析为什么在 JavaScript 中会存在变量提升,以及变量提升所带来的问题;然后再来 “开药方” —— 介绍如何通过块级作用域并配合 let 和 const 关键字来修复这种缺陷。
作用域
为什么 JavaScript 中会存在变量提升这个特性,而其他语言似乎都没有这个特性呢?要讲清楚这个问题,我们就得先从作用域讲起。
作用域是指在程序中定义变量的区域,该位置决定了变量的生命周期。通俗的理解,作用域就是变量与函数的可访问范围,即作用域控制着变量和函数的可见性和生命周期。
在 ES6 之前,ES 的作用域只有两种:全局作用域和函数作用域。
- 全局作用域中的对象在代码中的任何地方都能访问,其生命周期伴随着页面的生命周期。
- 函数作用域就是在函数内部定义的变量或者函数,并且定义的变量或者函数只能在函数内部被访问。函数执行结束之后,函数内部定义的变量会被销毁。
在 ES6 之前,JavaScript 只支持这两种作用域,相较而言,其他语言则都普遍支持块级作用域。块级作用域就是使用一对大括号包裹的一段代码,比如函数、判读语句、循环语句,甚至单独的一个 {} 都可以被看作是一个块级作用域。
为了更好地理解块级作用域,你可以参考下面的一些示例代码:
//if块
if(1){}
//while块
while(1){}
//函数块
function foo(){}
//for循环块
for(let i = 0; i<100; i++){}
//单独一个块
{}
简单来讲,如果一种语言支持块级作用域,那么其代码块内容定义的变量在代码块外部是访问不到的,并且该代码块中的代码执行完成之后,代码块中定义的变量会被销毁。你可以看下面这段 C代码:
char* myname = "极客时间";
void showName() {
printf("%s
",myname);
if(0){
char* myname = "极客邦";
}
}
int main(){
showName();
return 0;
}
上面这段 C 代码执行后,最终打印出来的是上面全局变量 myname 的值,之所以这样,是因为 C 语言是支持块级作用域的,所以 if 块里面定义的变量是不能被 if 块外面的语句访问到的。
和 Java、C/C++ 不同,ES6 之前是不支持块级作用域的,因为当初设计这门语言的时候,并没有想到 JavaScript 会火起来,所以只是按照最简单的方式来设计。没有了块级作用域,再把作用域内部的变量统一提升无疑是最快速、最简单的设计,不过这也直接导致了函数中的变量无论是在哪里声明的,在编译阶段都会被提取到执行上下文的变量环境中,所以这些变量在整个函数内部的任何地方都是能被访问的,这也就是 JavaScript 中的变量提升。
变量提升所带来的问题
由于变量提升作用,使用 JavaScript 来编写和其他语言相同逻辑的代码,都有可能会导致不一样的执行结果。那为什么会出现这种情况呢?主要有以下两种原因。
1. 变量容易在不被察觉的情况下被覆盖掉
比如我们重新使用 JavaScript 来实现上面那段 C 代码,实现后的 JavaScript 代码如下:
var myname = "极客时间"
function showName(){
console.log(myname);
if(0){
var myname = "极客邦"
}
console.log(myname);
}
showName()
执行上面这段代码,打印出来的是 undefined,而并没有像前面 C 代码那样打印出来 “极客时间” 的字符串。为什么输出的内容是 undefined 呢?我们再来分析下。
首先当刚执行到 showName 函数调用时,执行上下文和调用栈的状态是怎样的?具体分析过程你可以回顾《08 | 调用栈:为什么JavaScript 代码会出现栈溢出?》这篇文章的分析过程,这里我就直接展示出来了,最终的调用栈状态如下图所示:
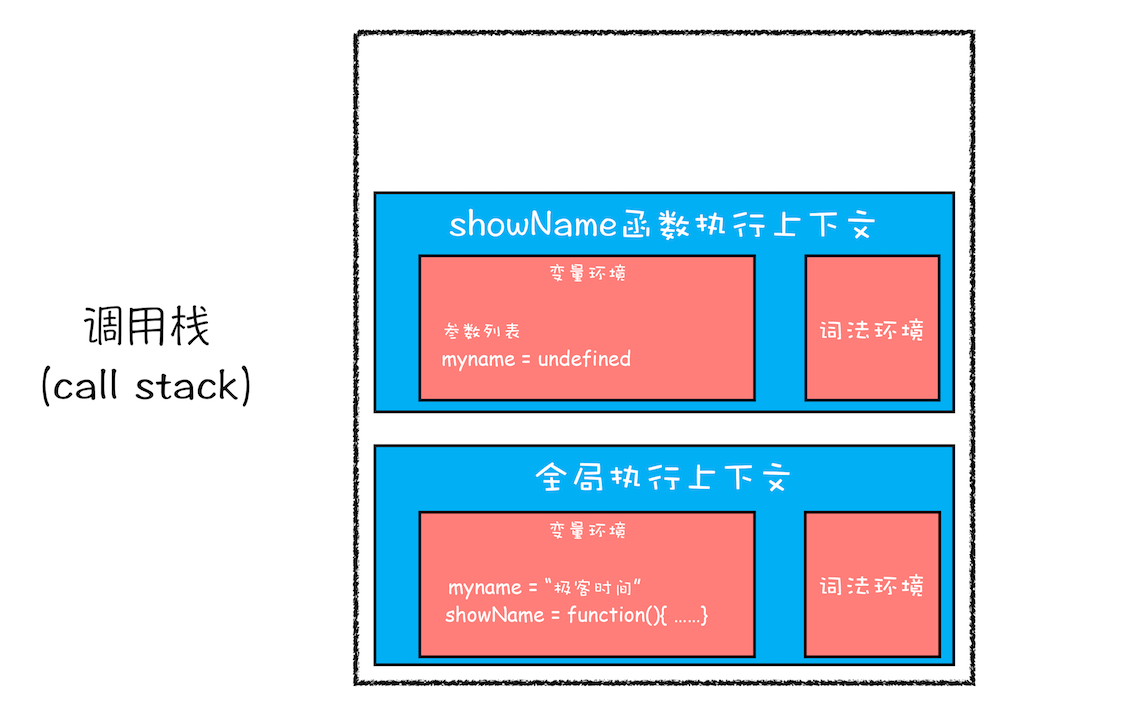
开始执行 showName 函数时的调用栈
showName 函数的执行上下文创建后,JavaScript 引擎便开始执行 showName 函数内部的代码了。首先执行的是:
console.log(myname);
执行这段代码需要使用变量 myname,结合上面的调用栈状态图,你可以看到这里有两个 myname 变量:一个在全局执行上下文中,其值是 “极客时间”;另外一个在 showName 函数的执行上下文中,其值是 undefined。那么到底该使用哪个呢?
相信做过 JavaScript 开发的同学都能轻松回答出来答案:"当然是先使用函数执行上下文里面的变量啦!" 的确是这样,这是因为在函数执行过程中,JavaScript 会优先从当前的执行上下文中查找变量,由于变量提升,当前的执行上下文中就包含了变量 myname,而值是 undefined,所以获取到的 myname 的值就是 undefined。
这输出的结果和其他大部分支持块级作用域的语言都不一样,比如上面 C 语言输出的就是全局变量,所以这会很容易造成误解,特别是在你会一些其他语言的基础之上,再来学习 JavaScript,你会觉得这种结果很不自然。
2. 本应销毁的变量没有被销毁
接下来我们再来看下面这段让人误解更大的代码:
function foo(){
for (var i = 0; i < 7; i++) {
}
console.log(i);
}
foo()
如果你使用 C 语言或者其他的大部分语言实现类似代码,在 for 循环结束之后, i 就已经被销毁了,但是在 JavaScript 代码中,i 的值并未被销毁,所以最后打印出来的是 7。
这同样也是由变量提升而导致的,在创建执行上下文阶段,变量 i 就已经被提升了,所以当 for 循环结束之后,变量 i 并没有被销毁。
这依旧和其他支持块级作用域的语言表现是不一致的,所以必然会给一些人造成误解。
ES6 是如何解决变量提升带来的缺陷
上面我们介绍了变量提升而带来的一系列问题,为了解决这些问题, ES6 引入了 let 和 const 关键字,从而使 JavaScript 也能像其他语言一样拥有了块级作用域。
关于 let 和 const 的用法,你可以参考下面代码:
let x = 5 const y = 6 x = 7 y = 9 //报错,const声明的变量不可以修改
从这段代码你可以看出来,两者之间的区别是,使用 let 关键字声明的变量是可以被改变的,而使用 const 声明的变量其值是不可以被改变的。但不管怎么样,两者都可以生成块级作用域,为了简单起见,在下面的代码中,我统一使用 let 关键字来演示。
那么接下来,我们就通过实际的例子来分析下,ES6 是如何通过块级作用域来解决上面的问题的。
你可以先参考下面这段存在变量提升的代码:
function varTest() {
var x = 1;
if (true) {
var x = 2; // 同样的变量!
console.log(x); // 2
}
console.log(x); // 2
}
在这段代码中,有两个地方都定义了变量 x,第一个地方在函数块的顶部,第二个地方在 if 块的内部,由于 var 的作用范围是整个函数,所以在编译阶段,会生成如下的执行上下文:
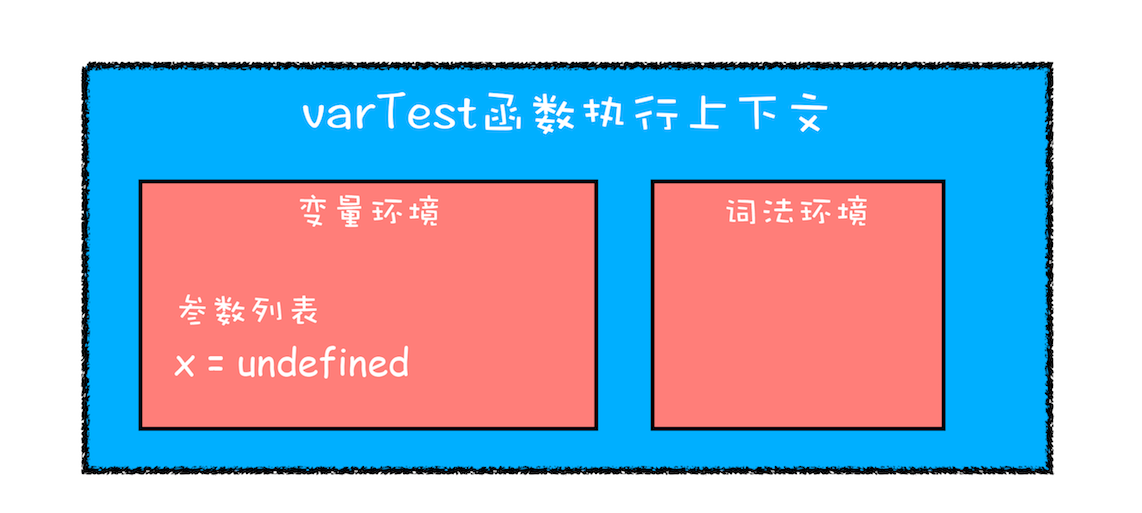
varTest 函数的执行上下文
从执行上下文的变量环境中可以看出,最终只生成了一个变量 x,函数体内所有对 x 的赋值操作都会直接改变变量环境中的 x 值。
所以上述代码最后通过 console.log(x) 输出的是 2,而对于同样逻辑的代码,其他语言最后一步输出的值应该是 1,因为在 if 块里面的声明不应该影响到块外的变量。
既然支持块级作用域和不支持块级作用域的代码执行逻辑是不一样的,那么接下来我们就来改造上面的代码,让其支持块级作用域。
这个改造过程其实很简单,只需要把 var 关键字替换为 let 关键字,改造后的代码如下:
function letTest() {
let x = 1;
if (true) {
let x = 2; // 不同的变量
console.log(x); // 2
}
console.log(x); // 1
}
执行这段代码,其输出结果就和我们的预期是一致的。这是因为 let 关键字是支持块级作用域的,所以在编译阶段,JavaScript 引擎并不会把 if 块中通过 let 声明的变量存放到变量环境中,这也就意味着在 if 块通过 let 声明的关键字,并不会提升到全函数可见。所以在 if 块之内打印出来的值是 2,跳出语块之后,打印出来的值就是 1 了。这种就非常符合我们的编程习惯了:作用域块内声明的变量不影响块外面的变量。
JavaScript 是如何支持块级作用域的
现在你知道了 ES 可以通过使用 let 或者 const 关键字来实现块级作用域,不过你是否有过这样的疑问:“在同一段代码中,ES6 是如何做到既要支持变量提升的特性,又要支持块级作用域的呢?”
那么接下来,我们就要站在执行上下文的角度来揭开答案。
你已经知道 JavaScript 引擎是通过变量环境实现函数级作用域的,那么 ES6 又是如何在函数级作用域的基础之上,实现对块级作用域的支持呢?你可以先看下面这段代码:
function foo(){
var a = 1
let b = 2
{
let b = 3
var c = 4
let d = 5
console.log(a)
console.log(b)
}
console.log(b)
console.log(c)
console.log(d)
}
foo()
当执行上面这段代码的时候,JavaScript 引擎会先对其进行编译并创建执行上下文,然后再按照顺序执行代码,关于如何创建执行上下文我们在前面的文章中已经分析过了,但是现在的情况有点不一样,我们引入了 let 关键字,let 关键字会创建块级作用域,那么 let 关键字是如何影响执行上下文的呢?
接下来我们就来一步步分析上面这段代码的执行流程。
第一步是编译并创建执行上下文,下面是我画出来的执行上下示意图,你可以参考下:
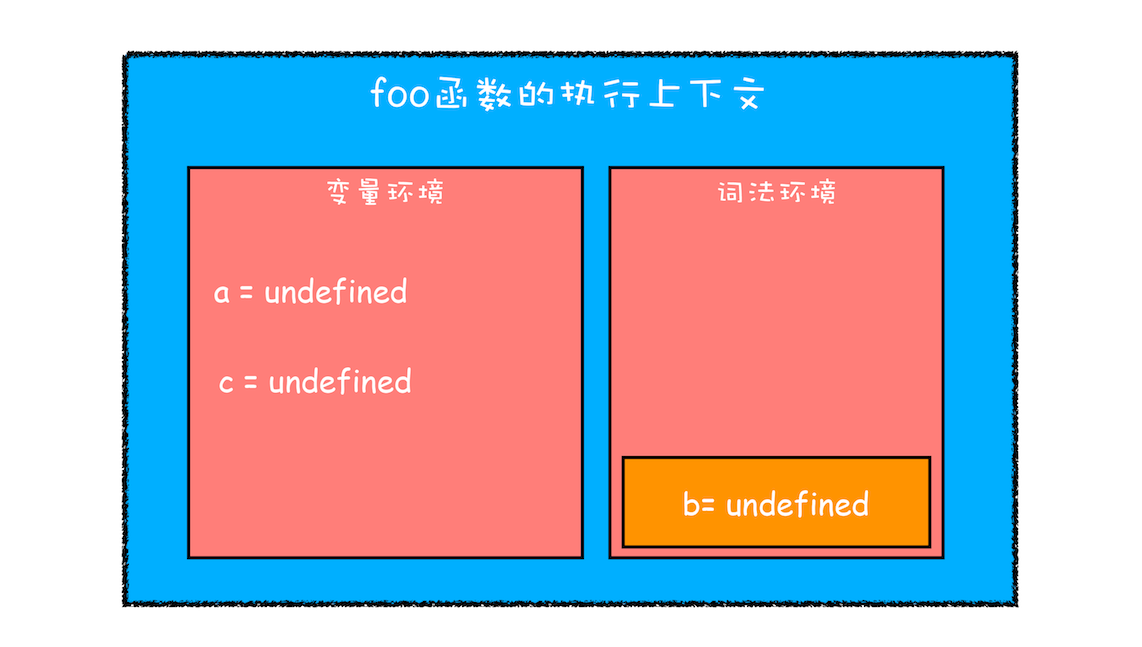
刚执行时 foo 函数的执行上下文
通过上图,我们可以得出以下结论:
- 函数内部通过 var 声明的变量,在编译阶段全都被存放到变量环境里面了。
- 通过 let 声明的变量,在编译阶段会被存放到词法环境(Lexical Environment)中。
- 在函数的作用域内部,通过 let 声明的变量并没有被存放到词法环境中。
接下来,第二步继续执行代码,当执行到代码块里面时,变量环境中 a 的值已经被设置成了 1,词法环境中 b 的值已经被设置成了 2,这时候函数的执行上下文就如下图所示:
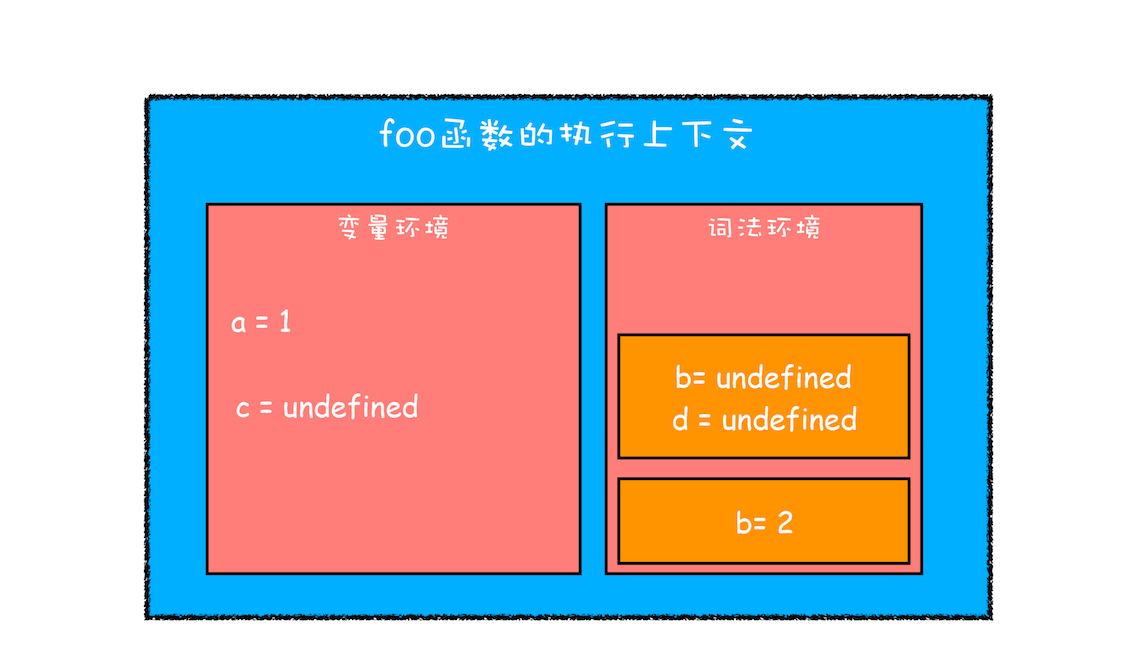
执行 foo 函数内部作用域块时的执行上下文
从图中可以看出,当进入函数的作用域块时,作用域块中通过 let 声明的变量,会被存放在词法环境的一个单独的区域中,这个区域中的变量并不影响作用域块外面的变量,比如在作用域外面声明了变量 b ,在该作用域块内部也声明了变量 b,当执行到作用域内部时,他们都是独立的存在。
其实,在词法环境内部,维护了一个小型栈结构,栈底是函数最外层的变量,进入一个作用域块后,就会把该作用域块内部的变量压到栈顶;当作用域执行完成之后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构。需要注意下,我这里所讲的变量是指通过 let 或 const 声明的变量。
再接下来,当执行到作用域块中的 console.log(a) 这行代码时,就需要在词法环境和变量环境中查找变量 a 的值了,具体查找方式是:沿着词法环境的栈顶向下查询,如果在词法环境中的某个块中查找到了,就直接返回给 JavaScript 引擎,如果没有查找到,那么继续在变量环境中查找。
这样一个变量查找过程就完成了,你可以参考下图:
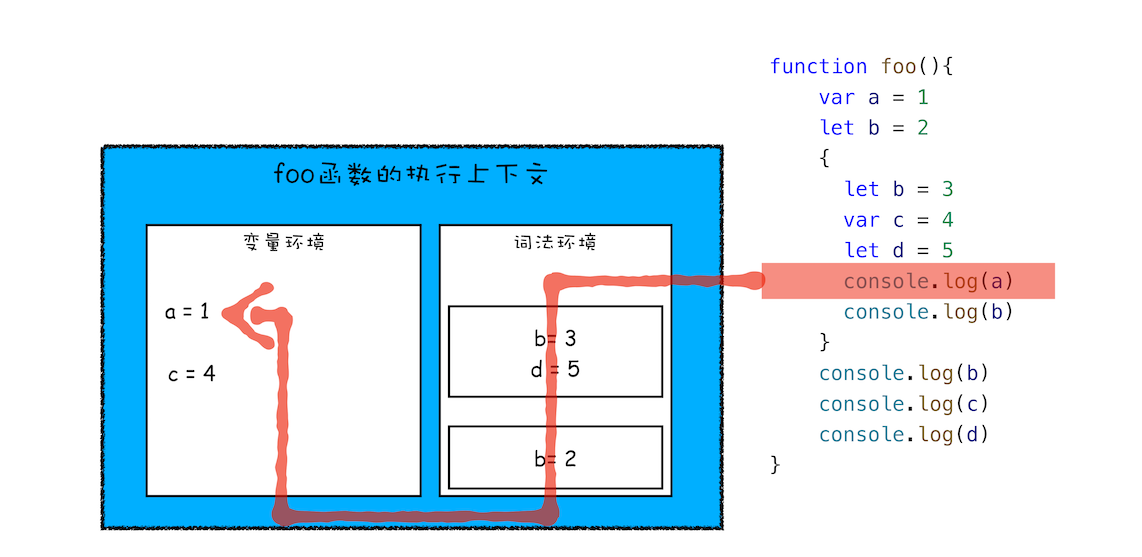
变量查找过程
从上图你可以清晰地看出变量查找流程,不过要完整理解查找变量或者查找函数的流程,就涉及到作用域链了,这个我们会在下篇文章中做详细介绍。
当作用域块执行结束之后,其内部定义的变量就会从词法环境的栈顶弹出,最终执行上下文如下图所示:
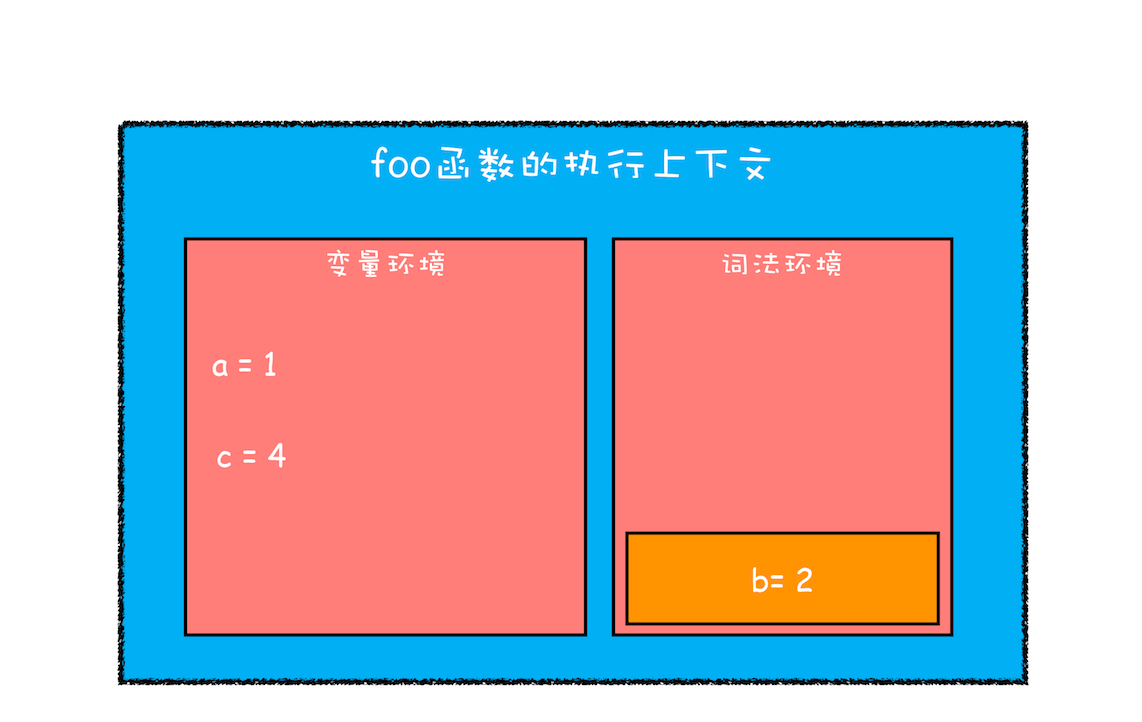
作用域执行完成示意图
通过上面的分析,想必你已经理解了词法环境的结构和工作机制,块级作用域就是通过词法环境的栈结构来实现的,而变量提升是通过变量环境来实现,通过这两者的结合,JavaScript 引擎也就同时支持了变量提升和块级作用域了。
总结
好了,今天的内容就讲到这里了,下面我来简单总结下今天的内容。
由于 JavaScript 的变量提升存在着变量覆盖、变量污染等设计缺陷,所以 ES6 引入了块级作用域关键字来解决这些问题。
之后我们还通过对变量环境和词法环境的介绍,分析了 JavaScript 引擎是如何同时支持变量提升和块级作用域的。
既然聊到了作用域,那最后我们再简单聊下编程语言把。经常有人争论什么编程语言是世界上最好的语言,但如果站在语言本身来说,我觉得这种争论没有意义,因为语言是工具,而工具是用来创造价值的,至于能否创造或者创造多大价值不完全由语言本身的特性决定。这么说吧,即便一门设计不那么好的语言,它也可能拥有非常好的生态,比如有完善的框架、非常多的落地应用,又或者能够给开发者带来更多的回报,这些都是评判因素。
如果站在语言层面来谈,每种语言其实都是在相互借鉴对方的优势,协同进化,比如 JavaScript 引进了块级作用域、迭代器和协程,其底层虚拟机的实现和 Java、Python 又是非常相似,也就是说如果你理解了 JavaScript 协程和 JavaScript 中的虚拟机,其实你也就理解了 Java、Python 中的协程和虚拟机的实现机制。
所以说,语言本身好坏不重要,重要的是能为开发者创造价值。
思考时间
下面留个思考题,看下面这样一段代码:
let myname= '极客时间'
{
console.log(myname)
let myname= '极客邦'
}
你能通过分析词法环境,得出来最终的打印结果吗?
答案: 【最终打印结果】:VM6277:3 Uncaught ReferenceError: Cannot access 'myname' before initialization 【分析原因】:在块作用域内,let声明的变量被提升,但变量只是创建被提升,初始化并没有被提升,在初始化之前使用变量,就会形成一个暂时性死区。 【拓展】 var的创建和初始化被提升,赋值不会被提升。 let的创建被提升,初始化和赋值不会被提升。 function的创建、初始化和赋值均会被提升。
/* other */
牛逼的回答,应该是分创建,初始化,赋值三个步骤,不然按照文章提到的变量从词法环境到变量环境的查询方向,理论上还是可以打印出myname。正因为let没有初始化,所以暂时性死区中使用变量就会报错
/* other */
实际上 let会被提升,只是初始化为uninitialized
-> 注:此处个人觉得这个说法有点不妥当,不应该说 let 会被提升,而应该换成 let 会先被创建,值是 uninitialized。 此处应该像楼上说的那样,分三步:创建,初始化,赋值,才更好理解。
问题记录
1、执行上下文是在编译时创建的,在执行代码的时候已经有词法环境了,而且变量已经默认初始化了undefiend,为什么还会存在暂时性死区?
作者回复: 暂时性死去是语法规定的,也就是说虽然通过let声明的变量已经在词法环境中了,但是在没有赋值之前,访问该变量JavaScript引擎就会抛出一个错误。
2、也就是编译时,块级作用域不编译。只有在执行时会为块级作用域临时创建词法环境
浏览器中的JavaScript执行机制:10 | 作用域链和闭包:代码中出现相同的变量,JavaScript引擎是如何选择的?
前言:该篇说明:|请见 说明 —— 浏览器工作原理与实践 目录
在上一篇文章中我们讲到了什么是作用域,以及 ES6 是如何通过变量环境和词法环境来同时支持变量提升和块级作用域,在最后我们也提到了如何通过词法环境和变量环境来查找变量,这其中就涉及到作用域链的概念。
理解作用域链是理解闭包的基础,而闭包在 JavaScript 中几乎无处不在,同时作用域和作用域链还是所有编程语言的基础。所以,如果你想学透一门语言,作用域和作用域链一定是绕不开的。
那今天我们就来聊聊什么是作用域链。并通过作用域链再来讲讲什么是闭包。
首先我们来看下面这段代码:
function bar() {
console.log(myName)
}
function foo() {
var myName = "极客邦"
bar()
}
var myName = "极客时间"
foo()
你觉得这段代码中的 bar 函数和 foo 函数打印出来的内容是什么?这就要分析下这两段代码的执行流程。
通过前面几篇文章的学习,想必你已经知道了如何通过执行上下文来分析代码的执行流程了。那么当这段代码执行到 bar 函数内部时,其调用栈的状态图如下所示:
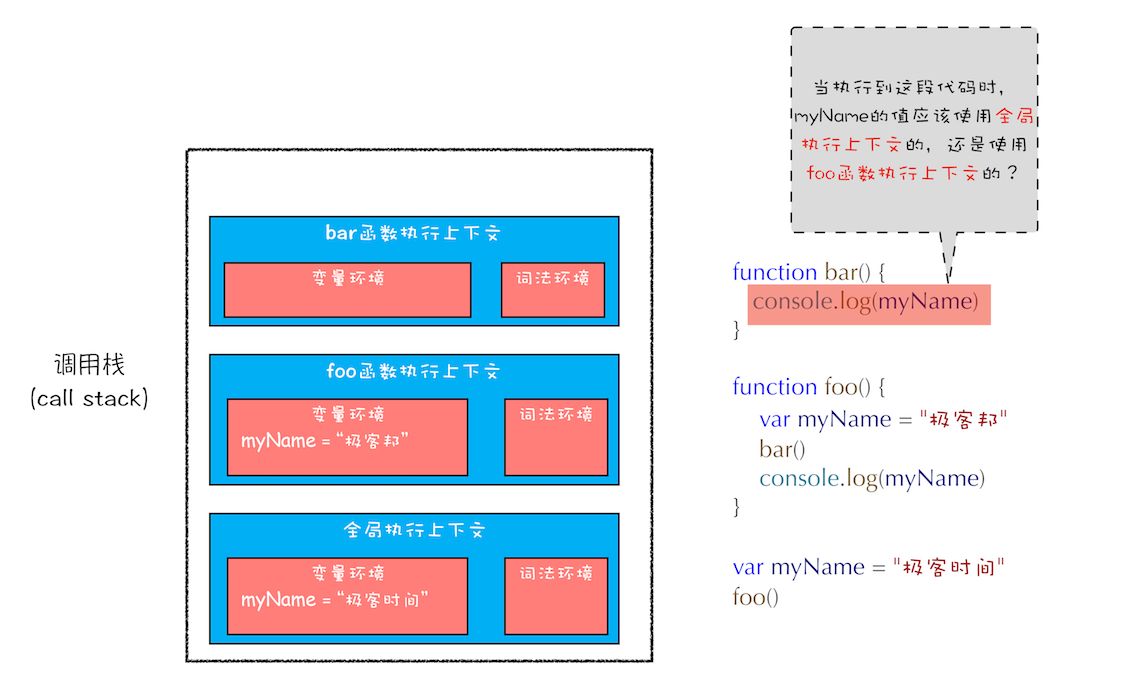
执行 bar 函数时的调用栈
从图中可以看出,全局执行上下文和 foo 函数的执行上下文中都包含变量 myName,那 bar 函数里面 myName 的值到底该选择哪个呢?
也许你的第一反应是按照调用栈的顺序来查找变量,查找方式如下:
1、先查找栈顶是否存在 myName 变量,但是这里没有,所以接着往下查找 foo 函数中的变量。
2、在 foo 函数中查到到了 myName 变量,这时候就使用 foo 函数中的 myName。
如果按照这种方式来查找变量,那么最终执行 bar 函数打印出来的结果是 “极客邦”。但实际情况并非如此,如果你试着执行上述代码,你会发现打印出来的结果是 “极客时间”。为什么会是这种情况呢?要解释清楚这个问题,那么你就需要先搞清楚作用域链了。
作用域链
关于作用域链,很多人会感觉费解,但如果你理解了调用栈、执行上下文、词法环境、变量环境等概念,那么你理解起来作用域链也会很容易。所以很是建议你结合前几篇文章将上面那几个概念学习透彻。
其实在每个执行上下文的变量环境中,都包含了一个外部引用,用来指向外部的执行上下文,我们把这个外部引用称为 outer。
当一段代码使用了一个变量时,JavaScript 引擎首先会在 “当前的执行上下文” 中查找该变量。
比如上面那段代码在查找 myName 变量时,如果在当前的变量环境中没有查找到,那么 JavaScript 引擎会继续在 outer 所指向的执行上下文中查找。为了直观理解,你可以看下面这张图:

带有外部引用的调用栈示意图
从图中可以看出,bar 函数和 foo 函数的 outer 都是指向全局上下文的,这也就意味着如果在 bar 函数或者 foo 函数中使用了外部变量,那么 JavaScript 引擎会去全局执行上下文中查找。我们把这个查找的链条就称为作用域链。
现在你知道变量是通过作用域链来查找的了,不过还有一个疑问没有解开,foo 函数调用 bar 函数,那为什么 bar 函数的外部引用是去全局执行上下文,而不是 foo 函数的执行上下文?
要回答这个问题,你还需要知道什么是 词法作用域。这是因为在 JavaScript 执行过程中,其作用域链是由词法作用域决定的。
词法作用域
词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。
这么讲可能不太好理解,你可以看下面这张图:
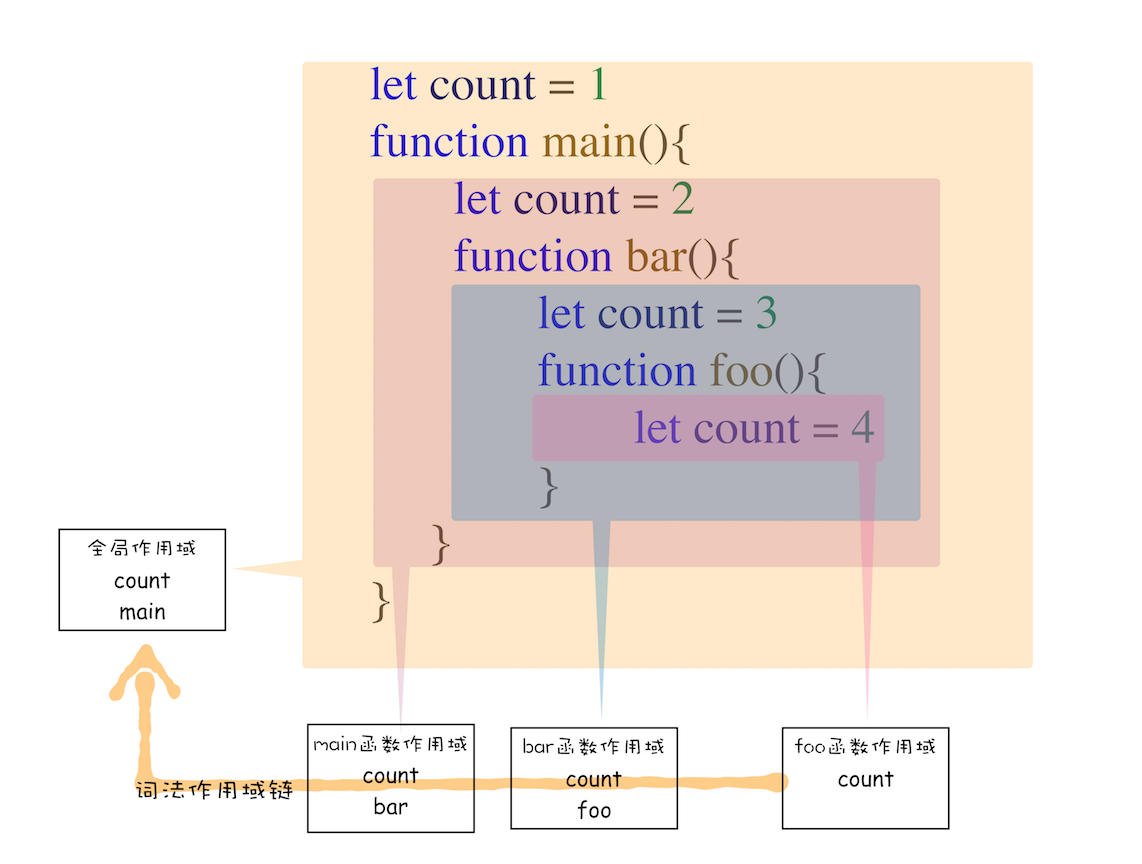
词法作用域
从图中可以看出,词法作用域就是根据代码的位置来决定的,其中 main 函数包含了 bar 函数,bar 函数中包含了 foo 函数,因为 JavaScript 作用域链是由词法作用域决定的,所以整个词法作用域链的顺序是:foo 函数作用域 ——> bar 函数作用域 ——> main 函数作用域 ——> 全局作用域。
了解了词法作用域以及 JavaScript 中的作用域链,我们再来回过头来看看上面的那个问题:在开头那段代码中,foo 函数调用了 bar 函数,那为什么 bar 函数的外部引用是全局执行上下文,而不是 foo 函数的执行上下文?
这是因为根据词法作用域,foo 和 bar 的上级作用域都是全局作用域,所以如果 foo 或者 bar 函数使用了一个它们没有定义的变量,那么它们会到全局作用域去查找。也就是说,词法作用域是代码阶段就决定好的,和函数是怎么调用的没有关系。
块级作用域中的变量查找
前面我们通过全局作用域和函数级作用域来分析了作用域链,那接下来我们再来看看块级作用域中变量是如何查找的?在编写代码的时候,如果你使用了一个在当前作用域中不存在的变量,这时 JavaScript 引擎就需要按照作用域链在其他作用域中查找该变量,如果你不了解该过程,那就会有很大概率写出不稳定的代码。
我们还是先看下面这段代码:
function bar() {
var myName = "极客世界"
let test1 = 100
if (1) {
let myName = "Chrome浏览器"
console.log(test)
}
}
function foo() {
var myName = "极客邦"
let test = 2
{
let test = 3
bar()
}
}
var myName = "极客时间"
let myAge = 10
let test = 1
foo()
你可以自己先分析下这段代码的执行流程,看看能否分析出来执行结果。
要想得出其执行结果,那接下来我们就得站在作用域链和词法环境的角度来分析下其执行过程。
在上篇文章中我们已经介绍过了,ES6 是支持块级作用域的,当执行到代码块时,如果代码块中有 let 或者 const 声明的变量,那么变量就会存放到该函数的词法环境中。对于上面这段代码,当执行到 bar 函数内部的 if 语句块时,其调用栈的情况如下图所示:

块级作用域中是如何查找变量的
现在是执行到 bar 函数的 if 语块之内,需要打印出来变量 test,那么就需要查找到 test 变量的值,其查找过程我已经在上图中使用序号 1、2、3、4、5 标记出来了。
下面我就来解释下这个过程。首先是在 bar 函数的执行上下文中查找,但因为 bar 函数的执行上下文中没有定义 test 变量,所以根据词法作用域的规则,下一步就在 bar 函数的外部作用域中查找,也就是全局作用域。
至于单个执行上下文中如何查找变量,我在上一篇文章中已经做了介绍,这里就不重复了。
闭包
了解了作用域链,接着我们就可以来聊聊闭包了。关于闭包,理解起来可能会是一道坎,特别是在你不太熟悉 JavaScript 这门语言的时候,接触闭包很可能会让你产生一些挫败感,因为你很难通过理解背后的原理来彻底理解闭包,从而导致学习过程中似乎总是似懂非懂。最要命的是,JavaScript 代码中还总是充斥着大量的闭包代码。
但理解了变量环境、词法环境和作用域链等概念,那接下来你再理解什么是 JavaScript 中的闭包就容易多了。这里你可以结合下面这段代码来理解什么是闭包:
function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = {
getName:function(){
console.log(test1)
return myName
},
setName:function(newName){
myName = newName
}
}
return innerBar
}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())
首先我们看看当执行到 foo 函数内部的 return innerBar 这行代码时调用栈的情况,你可以参考下图:
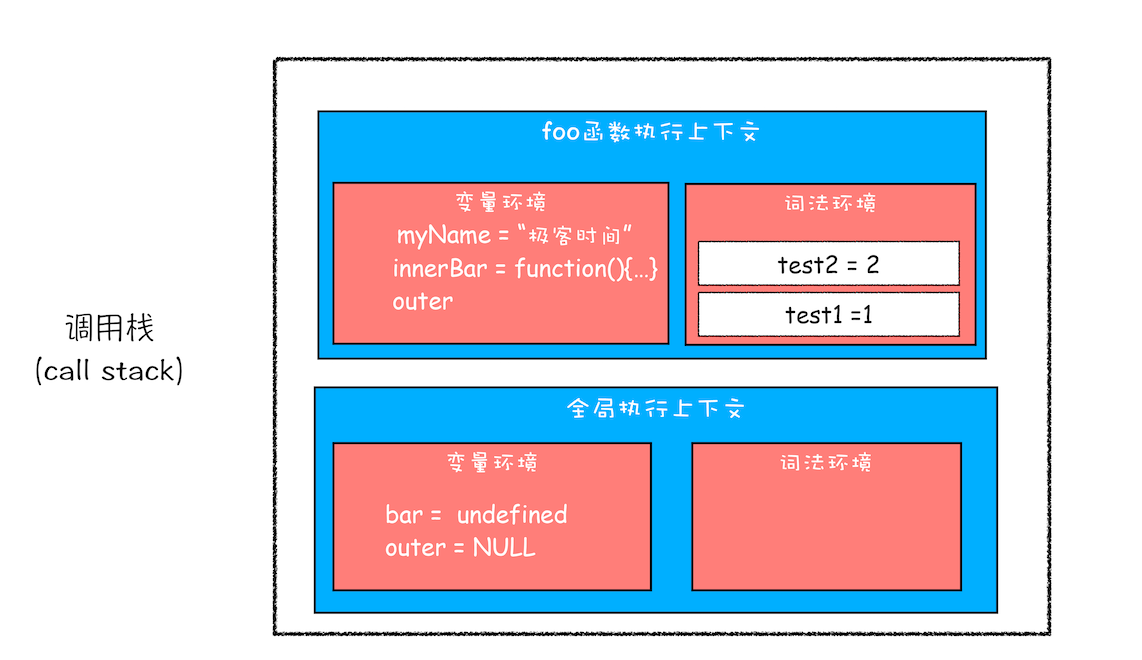
执行到 return bar 时候的调用栈
从上面的代码可以看出,innerBar 是一个对象(注:图中有点问题:在 foo 函数执行上下文中,innerBar 不应该是一个 function,而应该是一个对象),包含了 getName 和 setName 的两个方法(通常我们把对象内部的函数称为方法)。你可以看到,这两个方法都是在 foo 函数内部定义的,并且这两个方法内部都使用了 myName 和 test1 两个变量。
根据词法作用域的规则,内部函数 getName 和 setName 总是可以访问它们的外部函数 foo 中的变量,所以当 innerBar 对象返回给全局变量 bar 时,虽然 foo 函数已经执行结束,但是 getName 和 setName 函数依然可以使用 foo 函数中的变量 myName 和 test1。所以当 foo 函数执行完成之后,其整个调用栈的状态如下图所示:
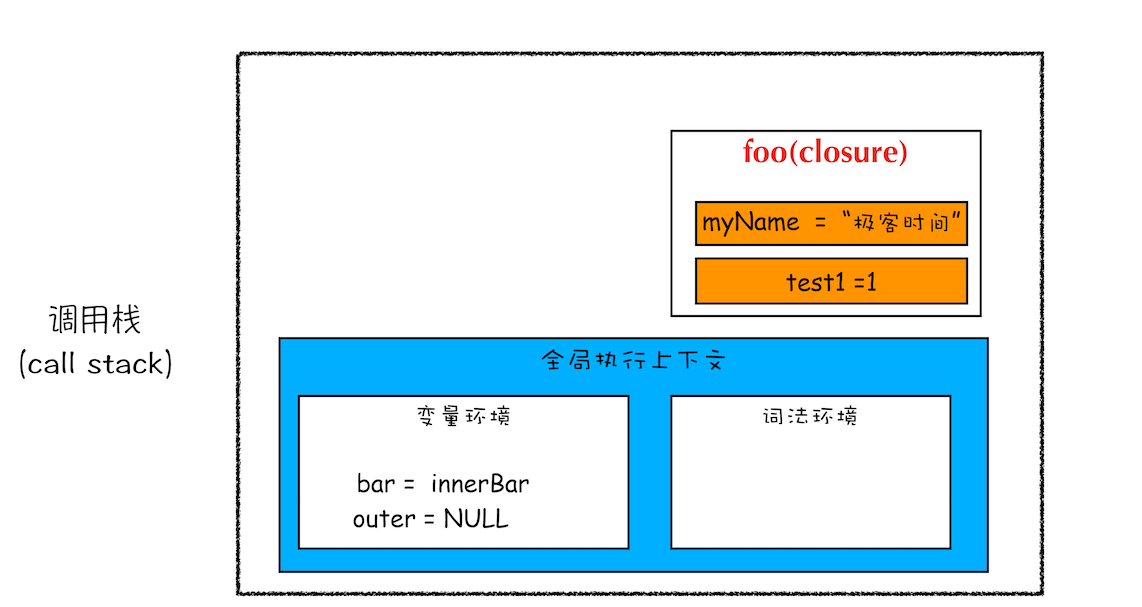
闭包的产生过程
从上图可以看出,foo 函数执行完成之后,其执行上下文从栈顶弹出了,但是由于返回的 setName 和 getName 方法中使用了 foo 函数内部的变量 myName 和 test1,所以这两个变量依然保存在内存中。这像极了 setName 和 getName 方法背的一个专属背包,无论在哪里调用了 setName 和 getName 方法,它们都会背着这个 foo 函数的专属背包。
之所以是专属背包,是因为除了 setName 和 getName 函数之外,其他任何地方都是无法访问该背包的,我们就可以把这个背包称为 foo 函数的闭包。
好了,现在我们终于可以给闭包一个正式的定义了。在 JavaScript 中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包。
那这些闭包是如何使用的呢?当执行到 bar.setName 方法中的 myName = "极客邦" 这句代码时,JavaScript 引擎会沿着 "当前执行上下文 -> foo 函数闭包 -> 全局执行上下文" 的顺序来查找 myName 变量,你可以参考下面的调用栈状态图:
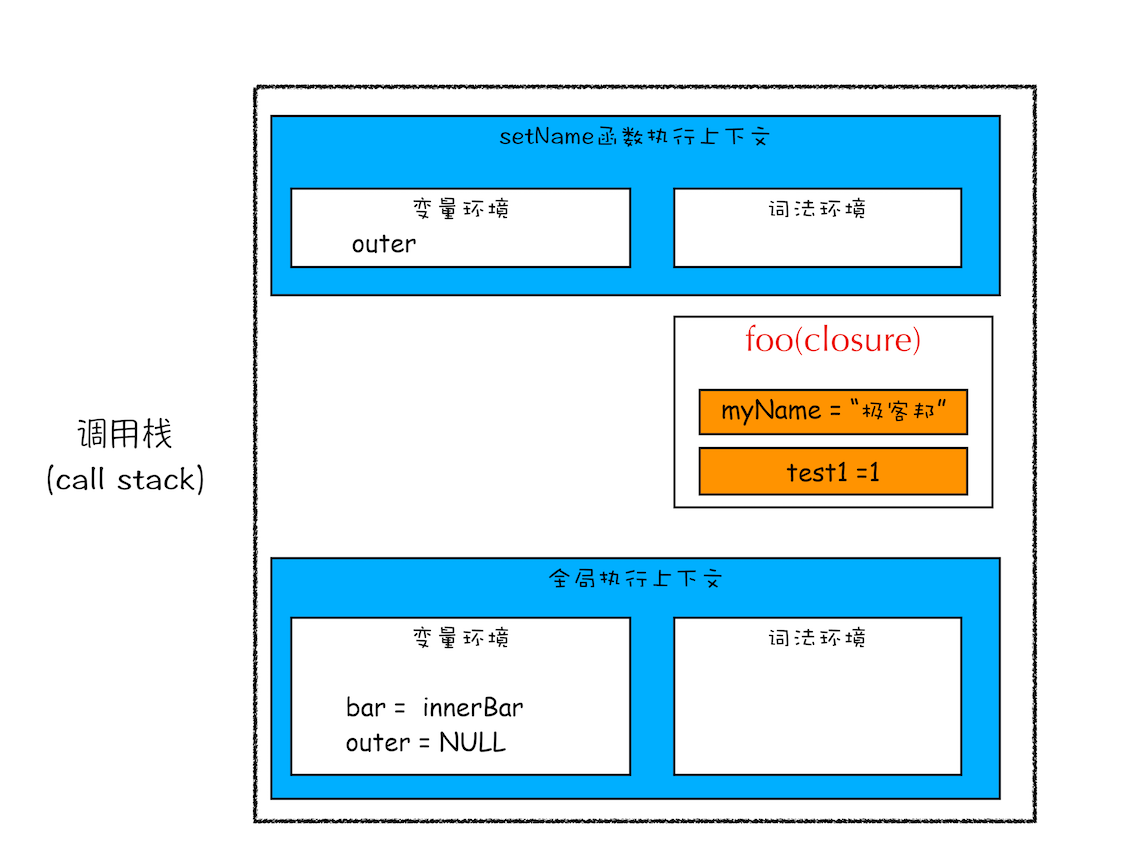
执行 bar 时调用栈状态
从图中可以看出,setName 的执行上下文中没有 myName 变量,foo 函数的闭包中包含了变量 myName,所以调用 setName 时,会修改 foo 闭包中的 myName 变量的值。
同样的流程,当调用 bar.getName 的时候,所访问的变量 myName 也是位于 foo 函数闭包中的。
你也可以通过 “开发者工具” 来看看闭包的情况,打开 chrome 的 “开发者工具”,在 bar 函数任意地方打上断点,然后刷新页面,可以看到如下内容:
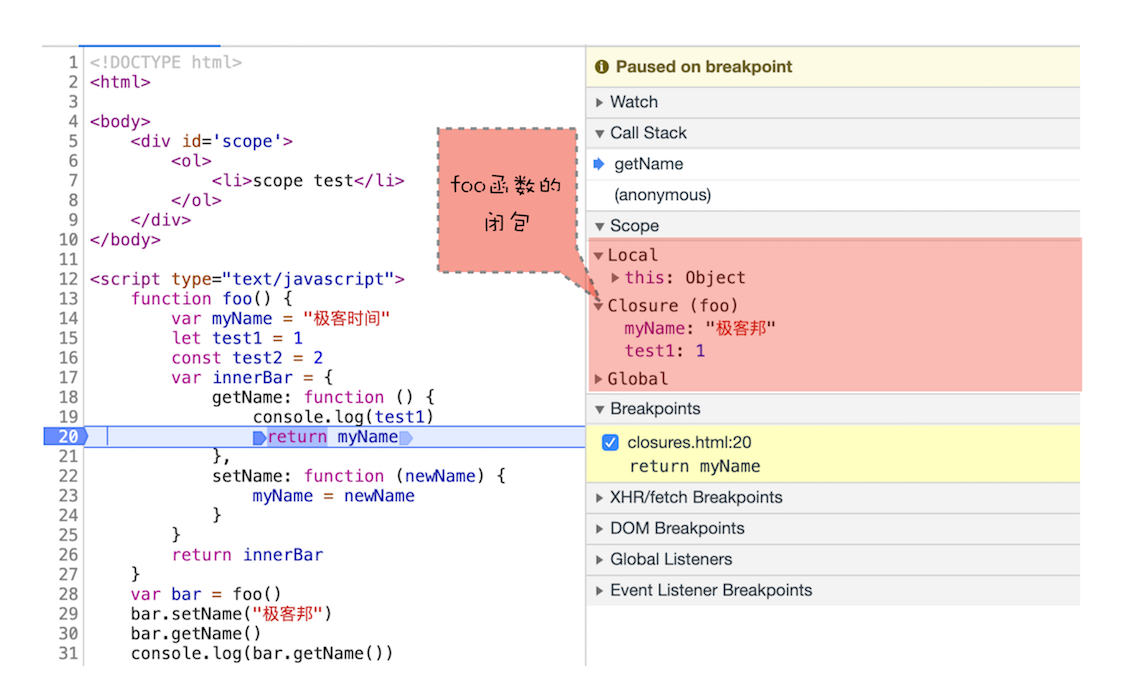
开发者工具中的闭包展示
从图中可以看出来,当调用 bar.getName 的时候,右边 Scope 项就体现出了作用域链的情况: Local 就是当前的 getName 函数的作用域,Closure(foo) 是指 foo 函数的闭包,最下面的 Global 就是指全局作用域,从 “Local -> Closure(foo) -> Global ” 就是一个完整的作用域链。
所以说,你以后也可以通过 Scope 来查看实际代码作用域链的情况,这样调试代码也会比较方便。
闭包是怎么回收的
理解什么是闭包之后,接下来我们再来简单聊聊闭包是什么时候销毁的。因为如果闭包使用不正确,会很容易造成内存泄露的,关注闭包是如何回收的能让你正确地使用闭包。
通常,如果引用闭包的函数是一个全局函数,那么闭包会一直存在知道页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄露。
如果引用闭包的函数是个局部变量,等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存。
所以在使用闭包的时候,你要尽量注意一个原则:如果该闭包会一直使用,那么它可以作为全局变量而存在;但如果使用频率不高,而且占用内存又比较大的话,那就尽量让它成为一个局部变量。
关于闭包回收的问题本文只是做了个简单的介绍,其实闭包是如何回收的还牵涉到了 JavaScript 的垃圾回收机制,而关于垃圾回收,后续章节我会再为你做详细介绍的。
总结
好了,今天的内容就讲到这里,下面我们来回顾下今天的内容:
- 首先,介绍了什么是作用域链,我们把通过作用域查找变量的链条称为作用域链;作用域链是通过词法作用域来确定的,而词法作用域反映了代码的结构。
- 其次,介绍了在块级作用域中是如何通过作用域链来查找变量的。
- 最后,又基于作用域链和词法环境介绍了到底什么是闭包。
通过展开词法作用域,我们介绍了 JavaScript 中的作用域链和闭包;通过词法作用域,我们分析了在 JavaScript 的执行过程中,作用域链是已经注定好了,比如即使在 foo 函数中调用了 bar 函数,你也无法在 bar 函数中直接使用 foo 函数中的变量信息。
因此理解词法作用域对于你理解 JavaScript 语言本身有着非常大帮助,比如有助于你理解下一篇文章中要介绍的 this。另外,理解 词法作用域对于你理解其他语言也有很大的帮助,因为它们的逻辑都是一样的。
思考时间
今天留给你的思考题是关于词法作用域和闭包,我修改了上面那段产生闭包的代码,如下所示:
var bar = {
myName:"time.geekbang.com",
printName: function () {
console.log(myName)
}
}
function foo() {
let myName = "极客时间"
return bar.printName
}
let myName = "极客邦"
let _printName = foo()
_printName()
bar.printName()
在上面这段代码中有三个地方定义了 myName,分析这段代码,你觉得这段代码在执行过程中会产生闭包吗?最终打印的结果是什么?
// 答案
1、 var bar = { myName:"time.geekbang.com", printName: function () { console.log(myName) } } function foo() { let myName = " 极客时间 " return bar.printName } let myName = " 极客邦 " let _printName = foo() _printName() bar.printName() 全局执行上下文: 变量环境: Bar=undefined Foo= function 词法环境: myname = undefined _printName = undefined 开始执行: bar ={myname: "time.geekbang.com", printName: function(){...}} myName = " 极客邦 " _printName = foo() 调用foo函数,压执行上下文入调用栈 foo函数执行上下文: 变量环境: 空 词法环境: myName=undefined 开始执行: myName = " 极客时间 " return bar.printName 开始查询变量bar, 查找当前词法环境(没有)->查找当前变量环境(没有) -> 查找outer词法环境(没有)-> 查找outer语法环境(找到了)并且返回找到的值 pop foo的执行上下文 _printName = bar.printName printName()压bar.printName方法的执行上下文入调用栈 bar.printName函数执行上下文: 变量环境: 空 词法环境: 空 开始执行: console.log(myName) 开始查询变量myName, 查找当前词法环境(没有)->查找当前变量环境(没有) -> 查找outer词法环境(找到了) 打印" 极客邦 " pop bar.printName的执行上下文 bar.printName() 压bar.printName方法的执行上下文入调用栈 bar.printName函数执行上下文: 变量环境: 空 词法环境: 空 开始执行: console.log(myName) 开始查询变量myName, 查找当前词法环境(没有)->查找当前变量环境(没有) -> 查找outer词法环境(找到了) 打印" 极客邦 " pop bar.printName的执行上下文 2、思考题: 这道题其实是个障眼法,只需要确定好函数调用栈就可以很轻松的解答,调用了foo()后,返回的是bar.printName,后续就跟foo函数没有关系了,所以结果就是调用了两次bar.printName(),根据词法作用域,结果都是“极客邦”,也不会形成闭包。 闭包还可以这样理解:当函数嵌套时,内层函数引用了外层函数作用域下的变量,并且内层函数在全局作用域下可访问时,就形成了闭包。 3、 思考题,最后输出的都是 “极客邦”,这里不会产生函数闭包,解释如下: 1). bar 不是一个函数,因此 bar 当中的 printName 其实是一个全局声明的函数,bar 当中的 myName 只是对象的一个属性,也和 printName 没有联系,如果要产生联系,需要使用 this 关键字,表示这里的 myName 是对象的一个属性,不然的话,printName 会通过词法作用域链去到其声明的环境,也就是全局,去找 myName 2). foo 函数返回的 printName 是全局声明的函数,因此和 foo 当中定义的变量也没有任何联系,这个时候 foo 函数返回 printName 并不会产生闭包
问题记录
一、关于闭包的概念:
老师提出的概念:内部函数引用外部函数的变量的集合。
高级程序设计中的概念:闭包是指有权访问另一个函数作用域中的变量的函数。
MDN上的概念:闭包是函数和声明该函数的词法环境的组合。
所以到底哪个是对的。。MDN = 老师 + 高程
作者回复: 很高兴终于有人提这个问题了,我的观点是不要太纠结于概念,因为如何定义闭包不会影响到实际的使用,了解闭包是如何产生的,这才是本质的东西。
二、本来对这篇文章充满期待,看完后还是有很多疑惑
又翻看了一下小红书
有以下疑问:
1. 最后的分析图是不是有问题,全局上下文中变量环境怎么会有myName
foo上下文中的innerBar是对象,用了函数?
2.闭包是存在调用栈里的,现在的模块化存在大量闭包,那不是调用栈底部存在大量闭包
很容易栈溢出吧
3.看了下chrome中函数对应的[[Scopes]]是个List集合包含了闭包模块,这个是不是文章中的outer
4.闭包是包含了整个变量环境和词法环境,还是只是包含用到的变量
作者回复: 第一个我的疏忽,图明天改正过来。 第二个问题:当闭包函数执行结束之后,执行上下文都从栈中弹出来,只不过被内部函数引用的变量不会被垃圾回收,这块内容要到讲v8 GC那节来讲了。 第三个没明白意思 第四个是 只包含用到的变量,这是因为在返回内部函数时,JS引擎会提前分析闭包内部函数的词法环境,有引用的外部变量都不会被gc回收。