NLPer最头疼的可能就是数据预处理了,拿到的多源数据通常长下面这样,乱成一团。

「我只想远离我的数据集,休息一下。」
如果你已经处理过文本数据并应用过一些机器学习算法,那么你肯定了解「NLP 管道」是多么复杂。
你通常需要写一堆正则表达式来清理数据,使用 NLTK、 SpaCy 或 Textblob 预处理文本,使用 Gensim (word2vec)或 sklearn (tf-idf、 counting 等)将文本向量化。
即使对于 Python 专家来说,如果考虑不周全,不理解哪些任务是必需的,也很容易迷失在不同的包文档中。
而现在有一个全新的自然语言处理工具箱,你只需要打开一个新的笔记本,就能像Pandas一样开始文本数据分析了,先睹为快!

文本英雄:一个pipeline完成所有NLP操作
Texthero 是一个开源的NLP工具包,旨在 Pandas 之上使用单一工具简化所有 NLP 开发人员的任务。它由预处理、向量化、可视化和 NLP 四个模块组成,可以快速地理解、分析和准备文本数据,以完成更复杂的机器学习任务。

Texthero可以轻松实现以下功能。 文本数据预处理
和Pandas无缝衔接,既可以直接使用,又可以自定义解决方案十分灵活。
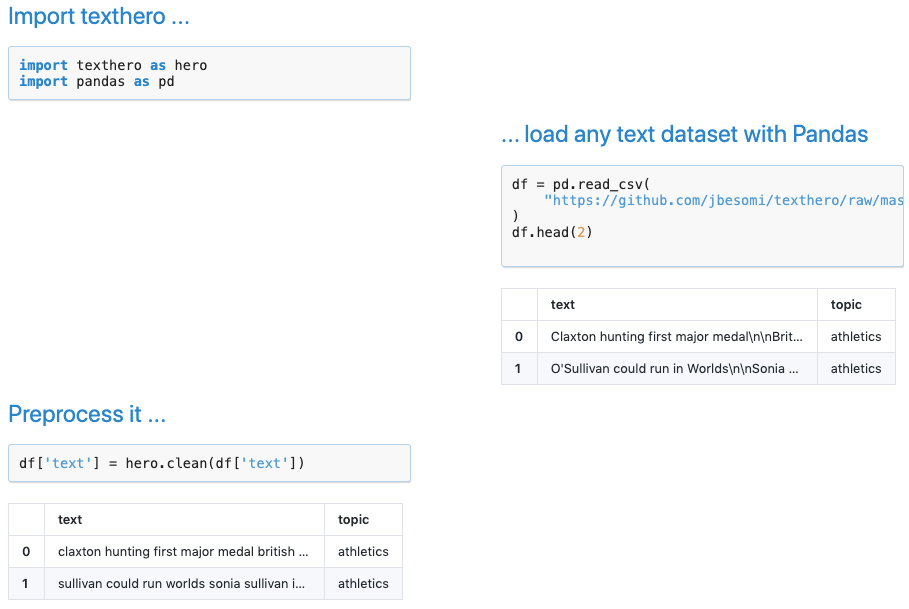
导入完数据直接clean ,不要太简单,所有脏活累活,Texthero都帮你完成了!我们来看看它在后台做了哪些工作。

Wow!填充缺失值、大小写转换、移除标点符号、移除空白字符等应有尽有,这些预处理对普通的文本数据已经足够了。 而此前,没有Texthero的话,你只能自定义文本清洗函数,包括去停用词、去特殊符号、词干化、词型还原等,非常复杂。
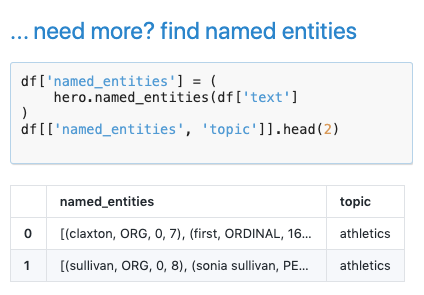
自然语言处理
关键短语和关键字提取,命名实体识别等等。
文本表示
TF-IDF,词频,预训练和自定义词嵌入。

向量空间分析
聚类(K均值,Meanshift,DBSAN和Hierarchical),主题建模(LDA和LSI)和解释。

文本可视化
一行代码即可完成关键字可视化,向量空间可视化等。

不仅功能强大速度还超快!
有网友怀疑融合了这么多的功能,速度一定有所下降。 而真相是:Texthero 相当快。 Texthero 使用了许多其他库,因此它的速度在很大程度上受到依赖库的影响。 但是对于文本预处理: 基本上就是 Pandas (在内存中使用 NumPy)和 Regex,速度非常快。对于tokenize,默认的 Texthero 函数是一个简单但功能强大的 Regex 命令,这比大多数 NLTK 和 SpaCy 的tokenize快,因为它不使用任何花哨的模型,缺点是没有 SpaCy 那样精确。

对于文本表示: TF-IDF 和 Count底层使用 sklearn 进行计算,因此它和 sklearn 一样快。嵌入是预先计算加载的,因此没有训练过程。词性标注和 NER 是用 SpaCy 实现的。众所周知,SpaCy 是同类自然语言处理中最快的,它也是工业界使用最多的。 网友:恨不生同时,早用早下班!
作者Jonathan Besomi是一个瑞士的NLP工程师。Texthero开源之后,他也在Reddit耐心回答了网友提问。

网友们用过之后也是纷纷点赞。 一周前放出来,我就能早点下班了!

简直是上帝的杰作!
来,快到我碗里来,我要应用到我现在的项目中。
太酷了!还可以将自己的TensorFlow/PyTorch模块融合进去。

当然这不是一个详尽的文档,作者稍后会写一个详细的博客文章,如果你也感兴趣并想加入Texthero,赶紧联系作者提交你的代码吧,或者直接撸一个Texthero中文版出来估计也能赚一波star! 参考链接:
https://github.com/jbesomi/textherohttps://texthero.org/