在以前学习深度学习的优化算法的时候,学习过有动量的梯度下降可以加快收敛速度,但对于这些算法的特性和动量大小如何选取还是一头雾水。这篇文章通俗地介绍一下微分方程和带有动量的梯度下降的联系,只是讲一下定性的分析,证明在Part IV里面以参考文献形式给出,本文分成一下几个部分:
Part I: 带有动量的梯度下降简介
Part II: 如何把微分方程和有动量的梯度下降联系起来?
Part III: 从摩擦力角度理解震荡现象和动量系数的选取
Part IV: 证明和新的进展
如果有啥没有说对的欢迎指出来,因为能力有限,所以很多东西都是emmm拼出来的,所以如果有哪里错了请一定指出来!
Part 0: 主要内容
因为本文内容比较杂,我组织地又不太好,容易看了后面忘了后面,所以把总结写在前面,其实这篇文章能记住总结就可以了。总结:Nesterov Accelerated Gradient(NAG)可以把gradient的收敛速度从 提高到
。NAG对应一个二阶微分方程,动量的系数对应摩擦力,动量系数越大,摩擦力越小,摩擦力小了算法收敛就会震荡。
Part I: 梯度下降和带有动量的梯度下降
首先介绍一下三个梯度下降方法,首先是最普通的梯度下降
然后是heavy ball method,区别是加了一个动量
接着是Nesterov method,区别在于改了动量的方向
在Nesterov方法当中,动量大小的选择是这个样子的
第一种选的方法还稍微可以理解一点儿,毕竟反比可以凑出来,第二种选的方法的动量居然还带开方,真是神奇,后面会对这两个选取方法加以解释。
为啥会有这些动量算法呢?当年提出的目的是为了加速收敛,各种方法的收敛性如下,对收敛性不是很了解的同学可以去看以前的专栏文章 [0]:

(备注:在strongly convex和smooth的情况下nesterov动量系数取 而非上述所说
才能达到线性收敛速度)
看上去就是不就是多了个根号嘛,到底能快多少呢?我们看一下Nesterov方法在经典的最小二乘法和lasso当中是怎么收敛的。
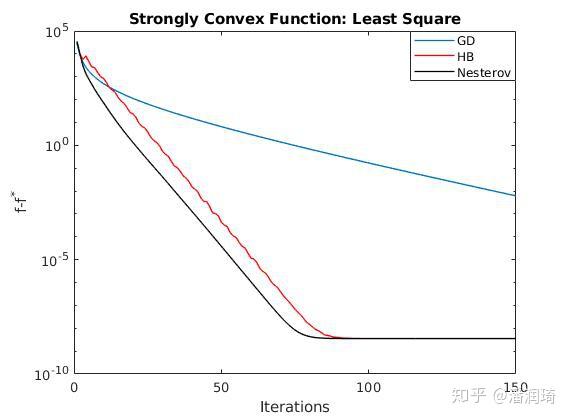
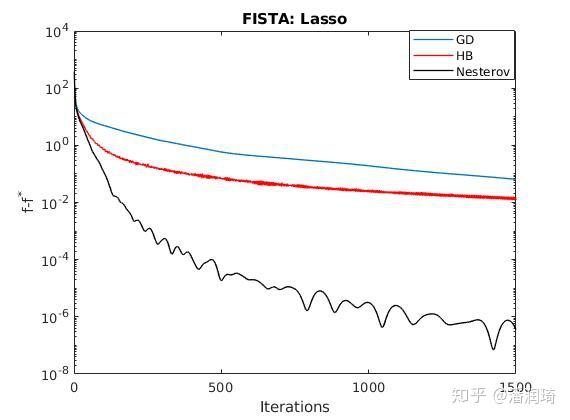
其实加速的效果还是挺明显的。我们的简介就到这里啦,大家应该已经有了一个基本的概念。但是对于这些动量的算法啊,还是有几个问题的:
- Nesterov method这个神奇的动量系数是神马情况,其他系数也可以么?
- 有动量的算法为啥会有波动?为啥在lasso的实验当中Nesterov method一开始几个iteration没有波动,后面的iteration就有波动了?
在下面几个章节,我们把梯度下降和微分方程联系起来,从物理(摩擦力)的角度解释这两个问题)
Part II: 如何把微分方程和有动量的梯度下降联系起来?
在我刚学用梯度下降达到去达到一个凸函数的最小值的时候,我就在想一个问题,如果我们把目标函数看成是有摩擦力的一个山谷,从任意一个位置放小球下去,如果摩擦力合适的话就可以达到最小值了。
回到了我们高中熟悉的受力分析

如果我们把运动方程 写出来的话呢,就是
其中 表示位置,
是位置的求导也就是速度,
就是速度的方向,
是对速度的求导也就是加速度。向量的系数是很长的一坨,如果我们把这些系数用字母表示一下就是一个二阶微分方程
然后呢,带有动量的梯度下降也可以恰好可以表示成这个形式,从直觉上来说呢,我们把梯度下降的步长设得很小很小,就基本上可以认为是一个微分方程了。从数学推导上,我们假设 ,也就是把第k步迭代的位置对应到滑块
时刻的位置。令
,那么我们有
和
,也就是我们把
对应到
时刻Nesterov的迭代方程(3)又可以写成
我们展开 和
得到
展开 得到
带进去(4)之后方程长这个样子
整理下Nesterov梯度下降对应的就是这个方程
在这种近似条件下,heavy ball的方程也长这个样子,有兴趣的读者可以验证一下。
现在我们终于可以从物理的角度看到动量系数的作用了:控制摩擦力大小,摩擦力大了的话速度就慢了,到最小值的时间就长了,摩擦力小了的话就会一直在震荡,很难停下来。
这个微分方程和带动量的优化算法的等价性只有步长趋于0的时候才成立,步长不是0的时候它到底准不准呢?我们画个图看看
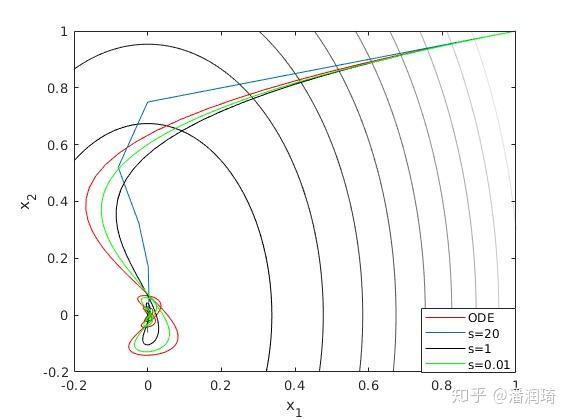
Emmmm... 其实在步长大的时候挺不准的。
Part III: 从摩擦力角度理解震荡现象和动量系数的选取
从上面的推导当中我们发现,有动量的梯度下降可以对应到一个二阶微分方程,其中的动量系数就是控制摩擦力大小的。
为啥会震荡呢?我们用二次函数的例子解释一下。我们把目标函数取成一个二次函数 ,其中
是正定矩阵。
的特征值分解
,其中
相当于把坐标轴旋转了一下,这种操作并不会影响收敛性,所以它的收敛和
是一样的。所以对应的微分方程就是
这个微分方程是不是看着贼熟悉?它其实就是中学里面的小球弹簧阻尼系统。
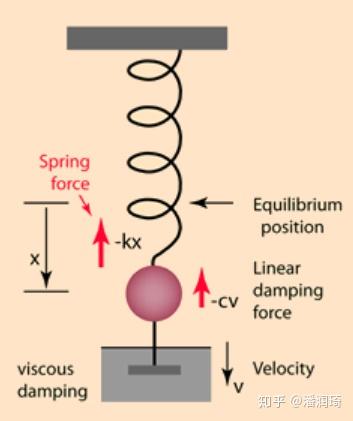
它的解分成过阻尼,欠阻尼,和临界阻尼三种,幅度都是指数衰减的,过阻尼和临界阻尼都不会震荡,欠阻尼会震荡。这样的话从这个方程当中我们既可以发现它是线性收敛的,又可以看到如果 的话就会发生震荡。在优化里面在过阻尼和欠阻尼情况下梯度下降的轨迹看起来是这个样子的
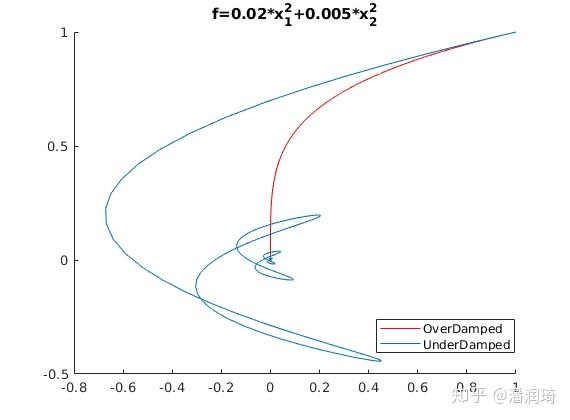
为啥对于lasso问题Nesterov方法一开始不会震荡,后来会了呢?因为在Nesterov方法当中摩擦力的系数是 ,一开始的时候摩擦力很大,所以不会有震荡现象,在最后的时候摩擦力很小很小,所以会出现震荡现象。
最后我们解决系数选取的问题,回顾一下Nesterov方法里面系数的选取有两种方法
画个图我们发现两种系数选取其实是差不多的
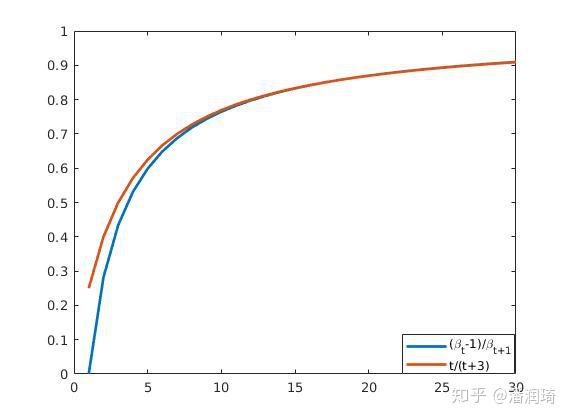
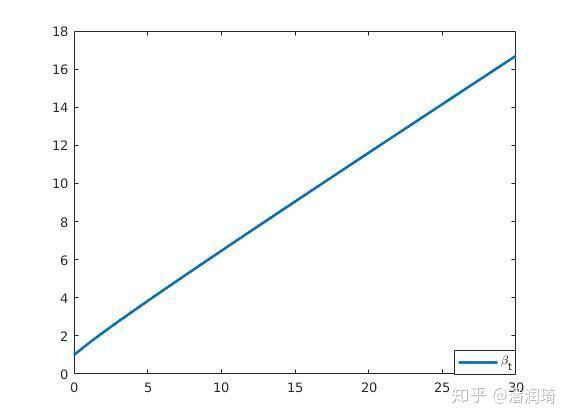
从下面这张图中我们看到 ,所以
(严谨一点就是
)。所以我们只要考虑
就可以啦~
这样的动量系数选取( )代入到(5)里面就对应到下面这个微分方程
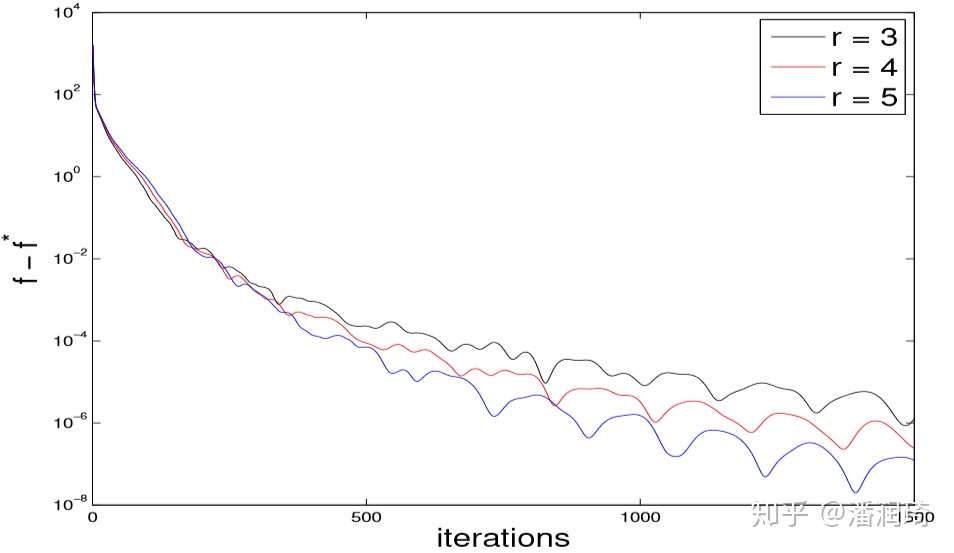
为啥r要取3呢?结论呢就是3是保证 收敛的最小的整数,
的时候是可以
收敛的,但是因为摩擦力大了收敛会变慢,
的时候是达不到
收敛的,证明比较复杂Reference会放在在Part IV。对于
的时候
如果r比较小,那么摩擦力也会比较小,这样算法一开始就会比较快,但是在离 比较近的时候会导致在
附近震荡,导致后来的收敛比较慢。
Part IV: 一些讨论和拓展阅读
1.证明部分
1.1 梯度下降的收敛性
1.2 Nesterov在strongly convex smooth下的收敛性
1.3 在步长趋于0的时候ODE和Nesterov的等价 [1] Theorem 2
1.4 Nesterov系数的选取 [1] Section 4
2.Heavy-Ball的全局收敛性
Heavy-Ball Method在二次函数下可以达到 的收敛速度[2] Theorem 7;在不是二次函数strongly convex的情况下是线性收敛的[3] Section 4,但是按照[2]当中的步长是不收敛的 [4] Equation 4.11,收敛也不会比gradient快;在只有smooth的情况下是收敛的 [3] Section 3。
这里感谢
大佬答疑。3. 一些新的进展
3.1 Heavy Ball和Nesterov有什么区别?如何从李雅普诺夫函数研究优化算法的收敛性?Understanding the Acceleration Phenomenon via High-Resolution Differential Equations
3.2 如何把微分方程离散化得到新的优化算法?Acceleration via Symplectic Discretization of High-Resolution Differential Equations Direct Runge-Kutta Discretization Achieves Acceleration
3.3 步长不趋于0怎么搞? Acceleration via Symplectic Discretization of High-Resolution Differential Equations
3.4 (正经)的物理insight? The Physical Systems Behind Optimization Algorithms
3.5 如何把微分方程离散化得到神经网络?Beyond Finite Layer Neural Networks: Bridging Deep Architectures and Numerical Differential Equations
4. 参考文献
[1] A Differential Equation for Modeling Nesterov's Accelerated Gradient Method: Theory and Insights
[2] A Fixed-Point of View on Gradient Methods for Big Data
[3] Global convergence of the Heavy-ball method for convex optimization
[4] Analysis and Design of Optimization Algorithms via Integral Quadratic Constraints
最后从知识的喜悦中脱离一下,点个赞呗~~欢迎关注专栏非凸优化学习之路