OR Talk NO.4 | Attain.ai 创始人李玉喜:强化学习遇见组合优化


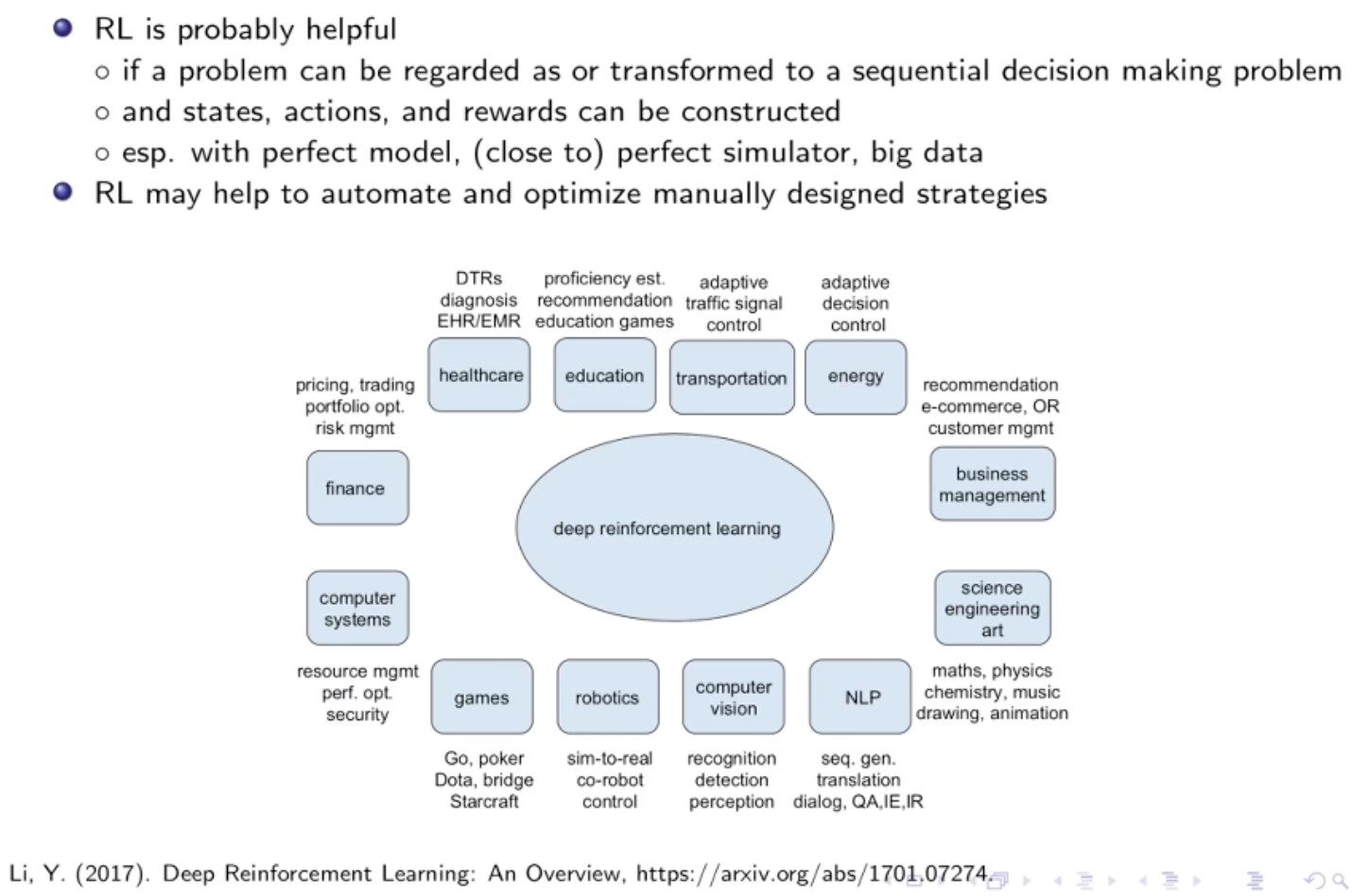
序列决策问题
能定义:state/action/reward
能有很多数据(比如有个好的 simulator)
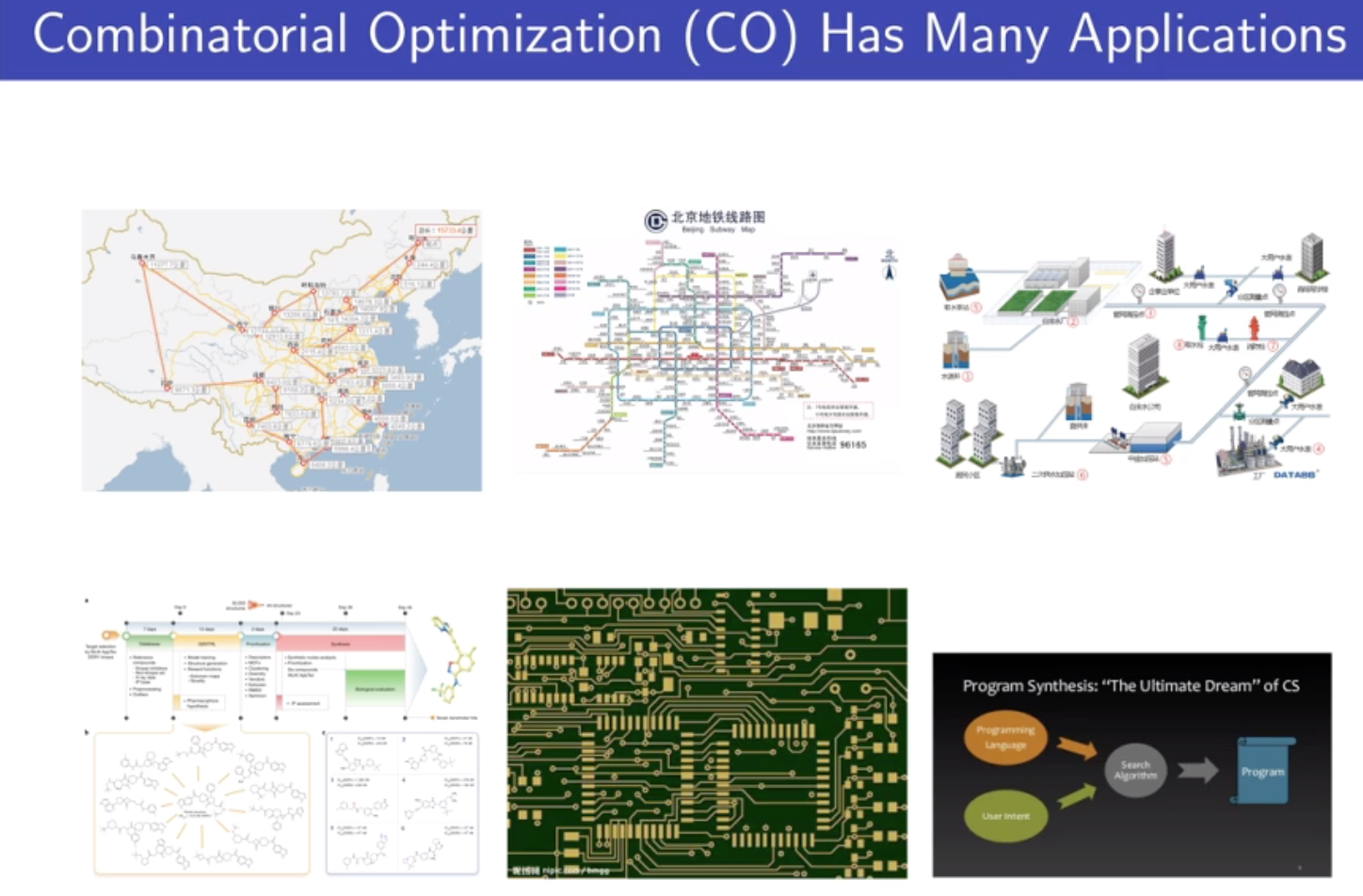
物流供应链
交通设计
网络调度(自来水)
药物设计
芯片设计
程序合成


1 end to end:pointer network 相当于给这个领域开创了一个先河:end-to-end——野心比较大,问题规模大时,效果不了,或 scalability 问题
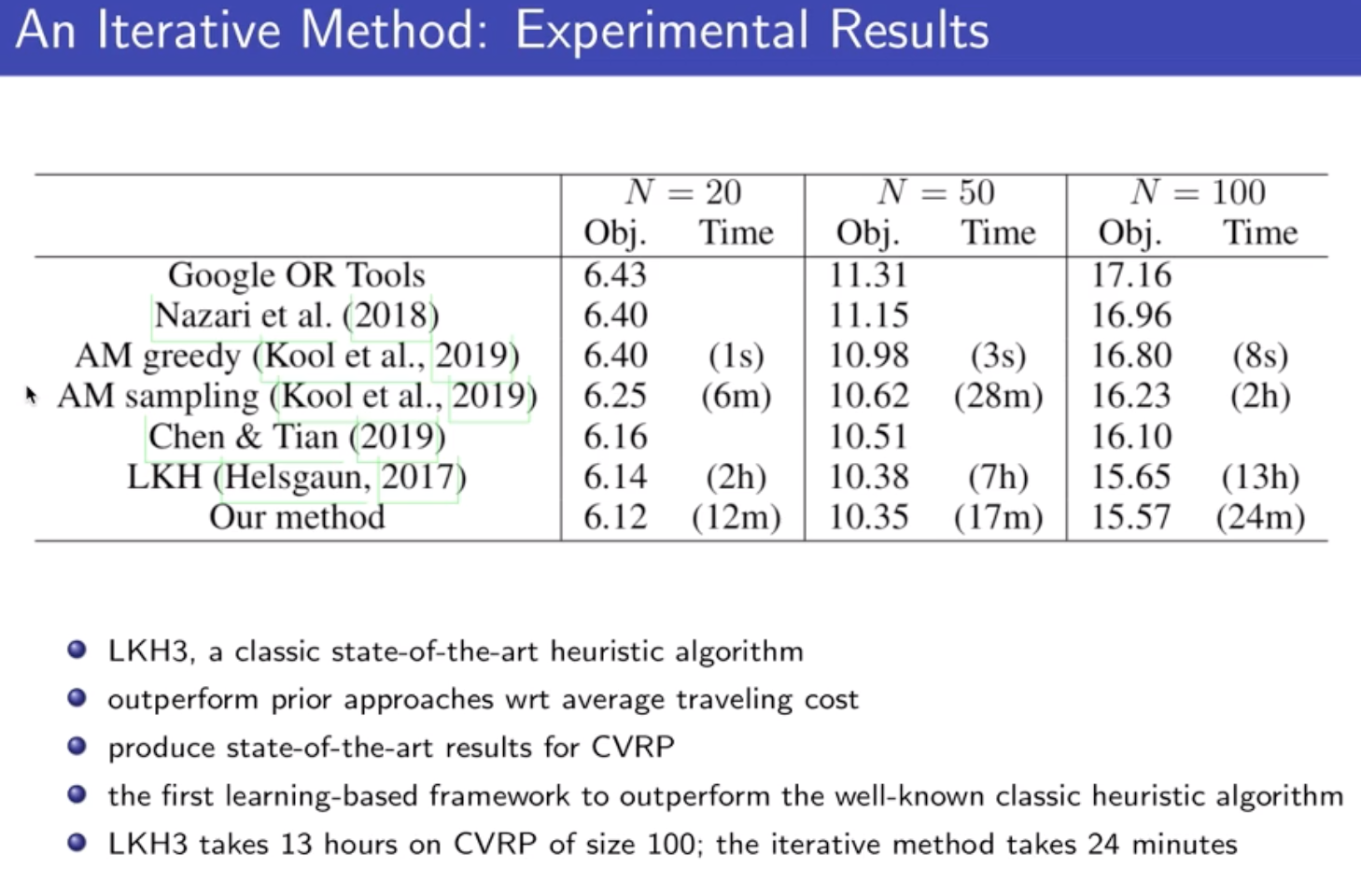
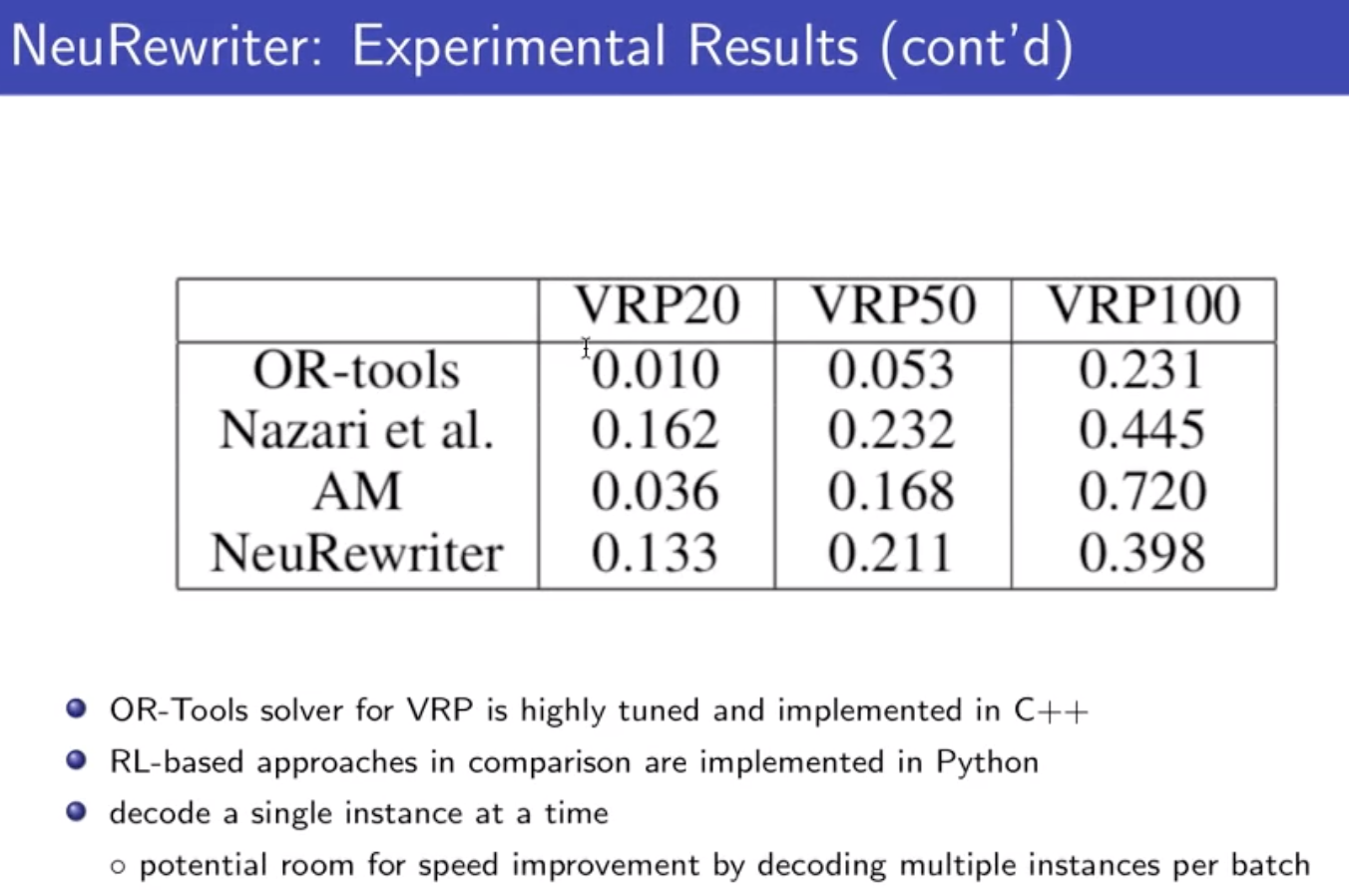
2 local search:目前最好的结果是这种方法;
3

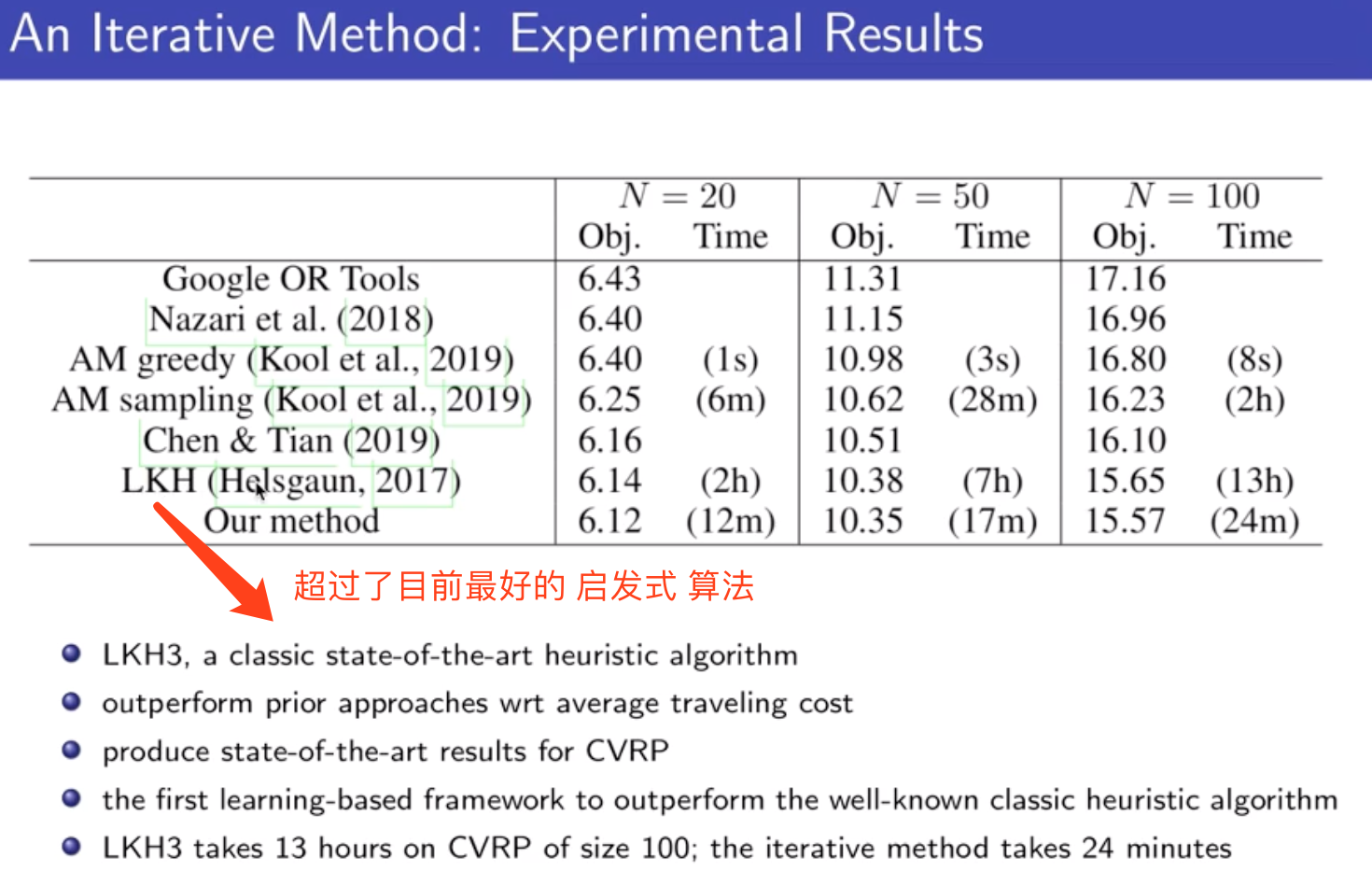
目前在100个节点的问题上,超过传统方法;
两种 operator: improvement operator(传统的heuristic 方法) & pertubation operator(local minima 时加摄动)
+ ensemble:训练几个不同的强化学习策略,ensemble


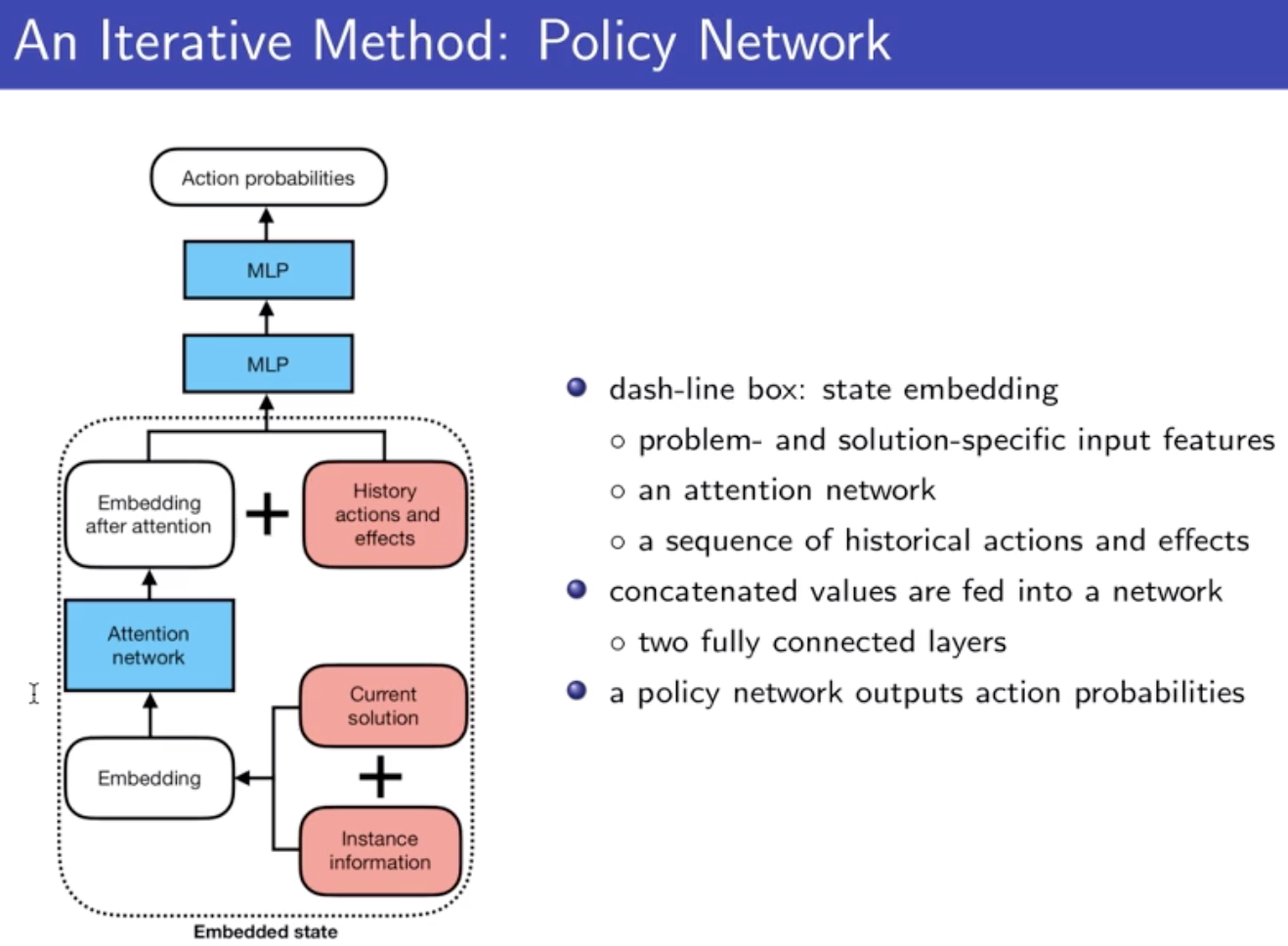

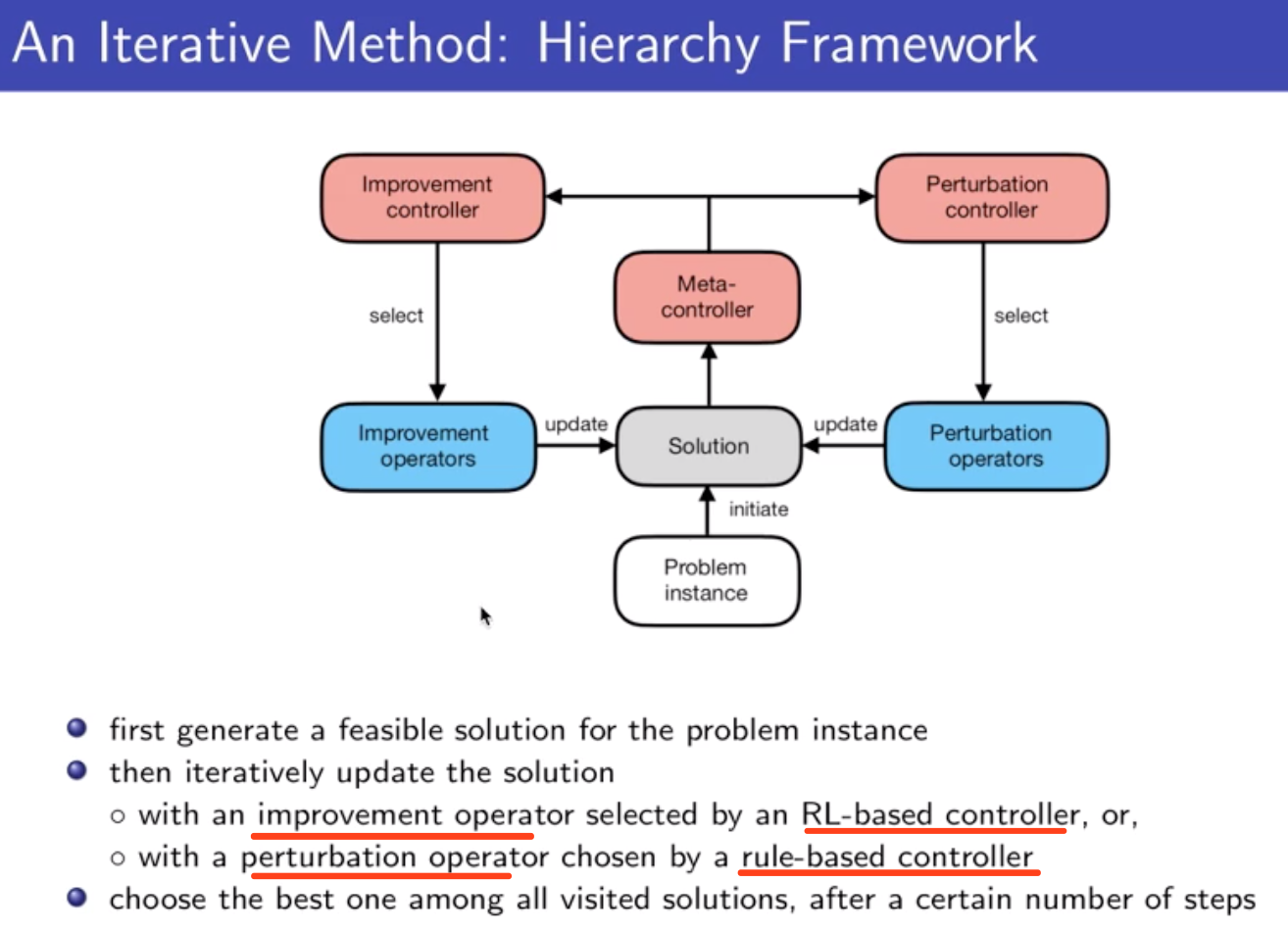





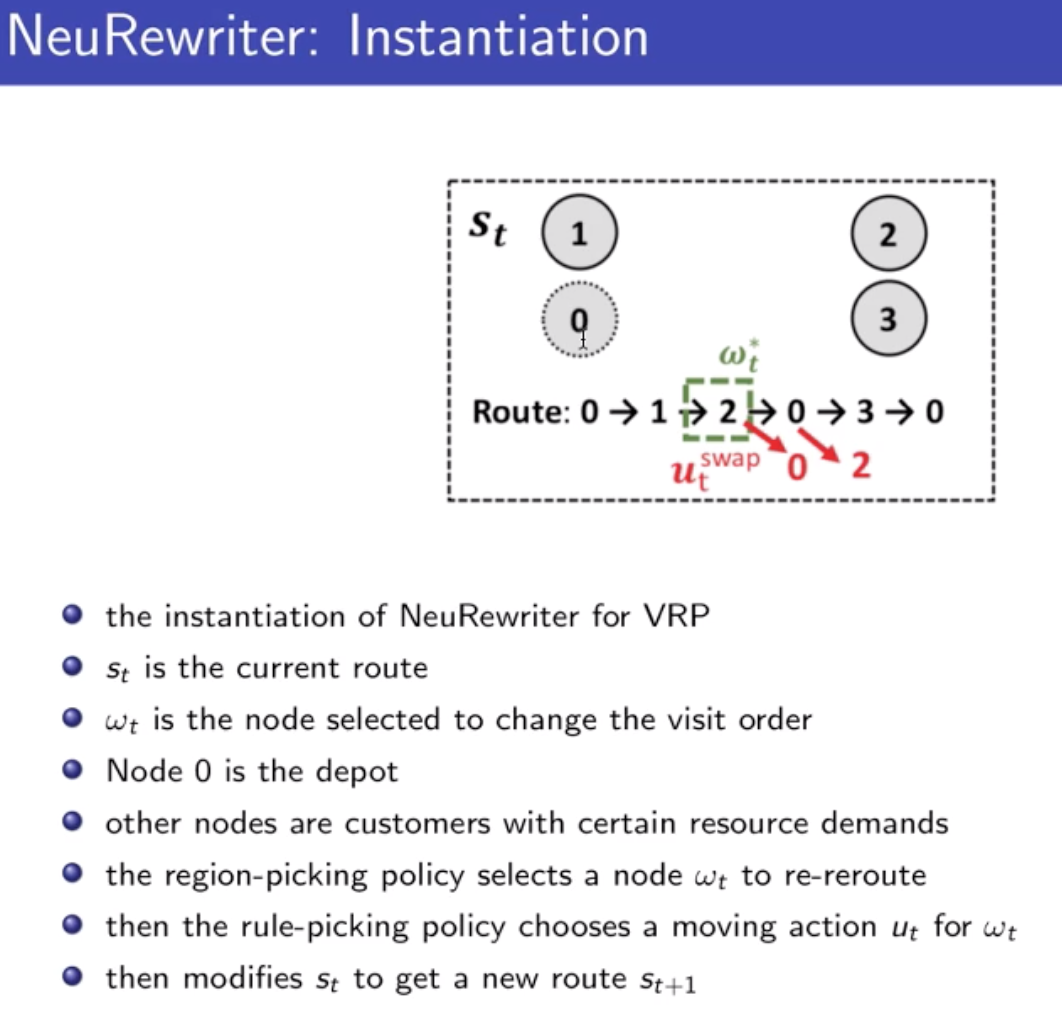


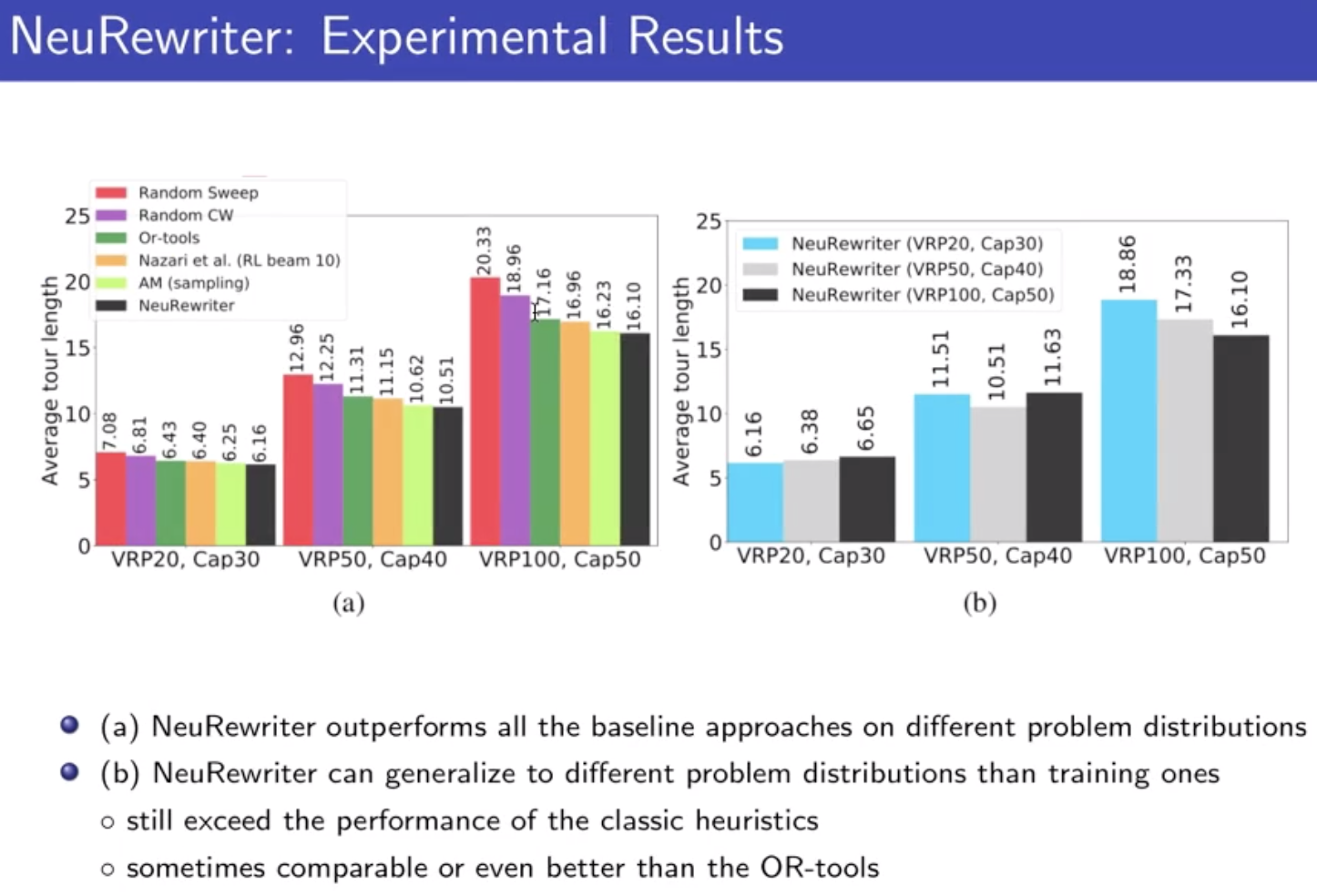

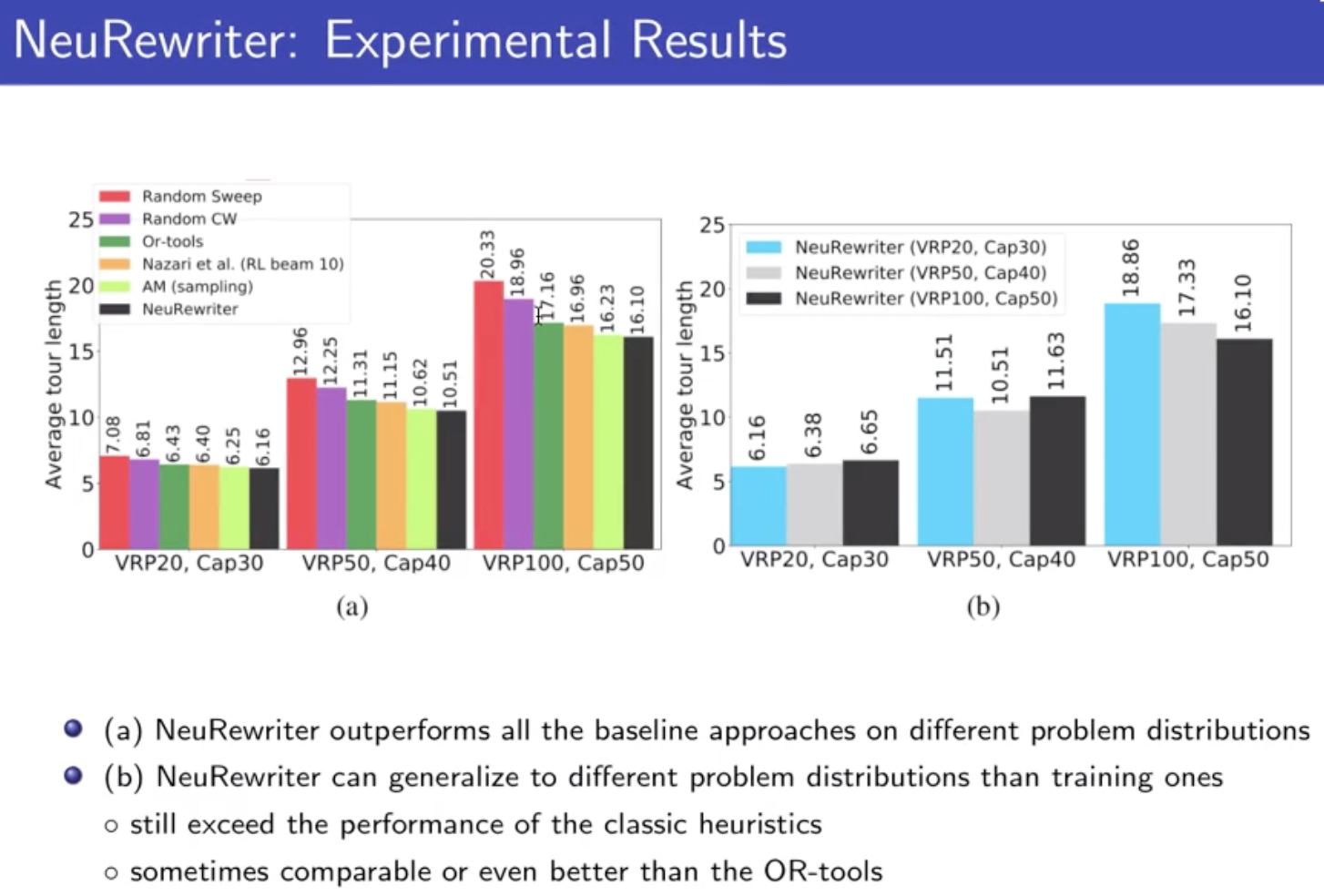

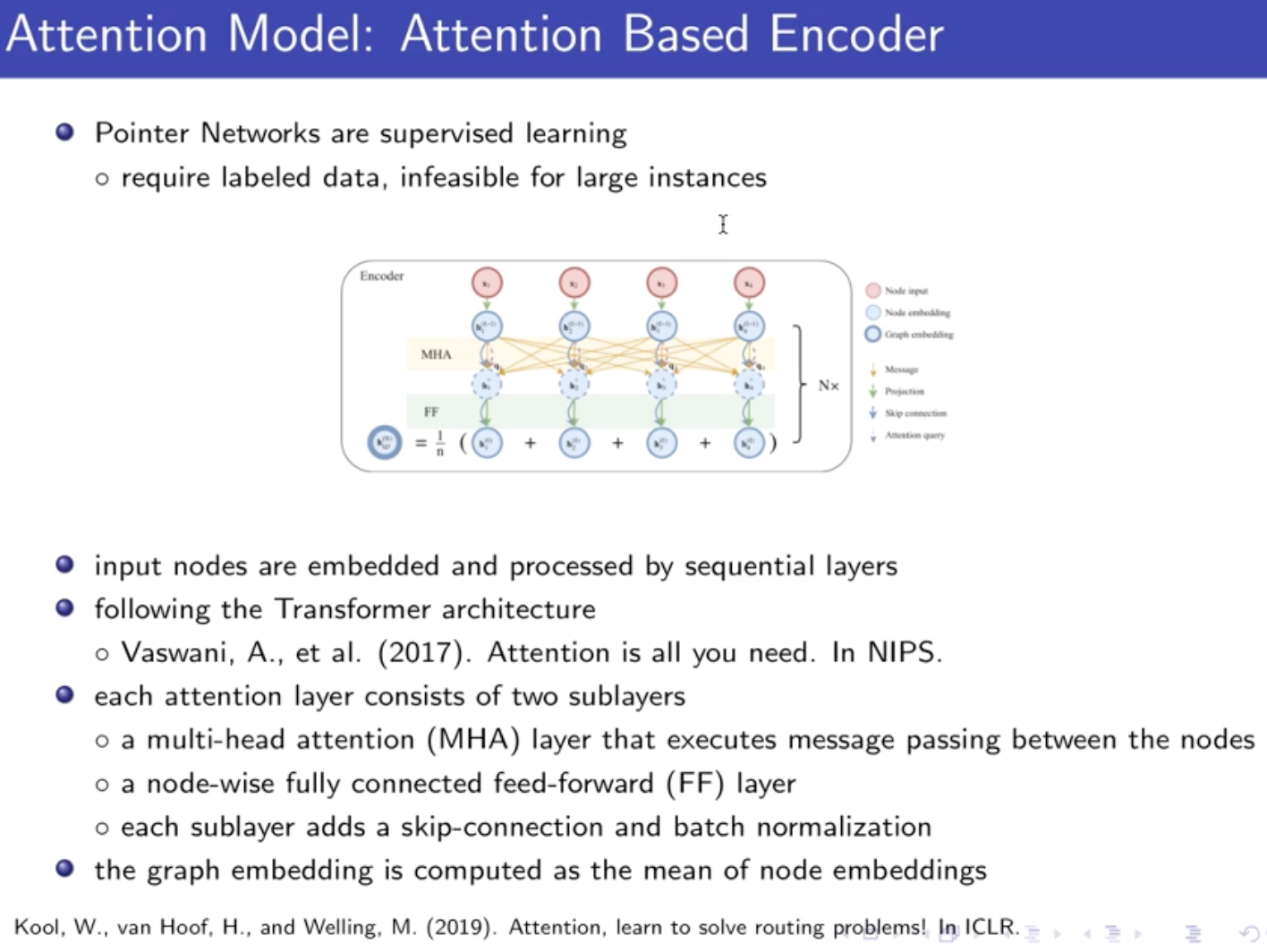
解决输入不定长的问题
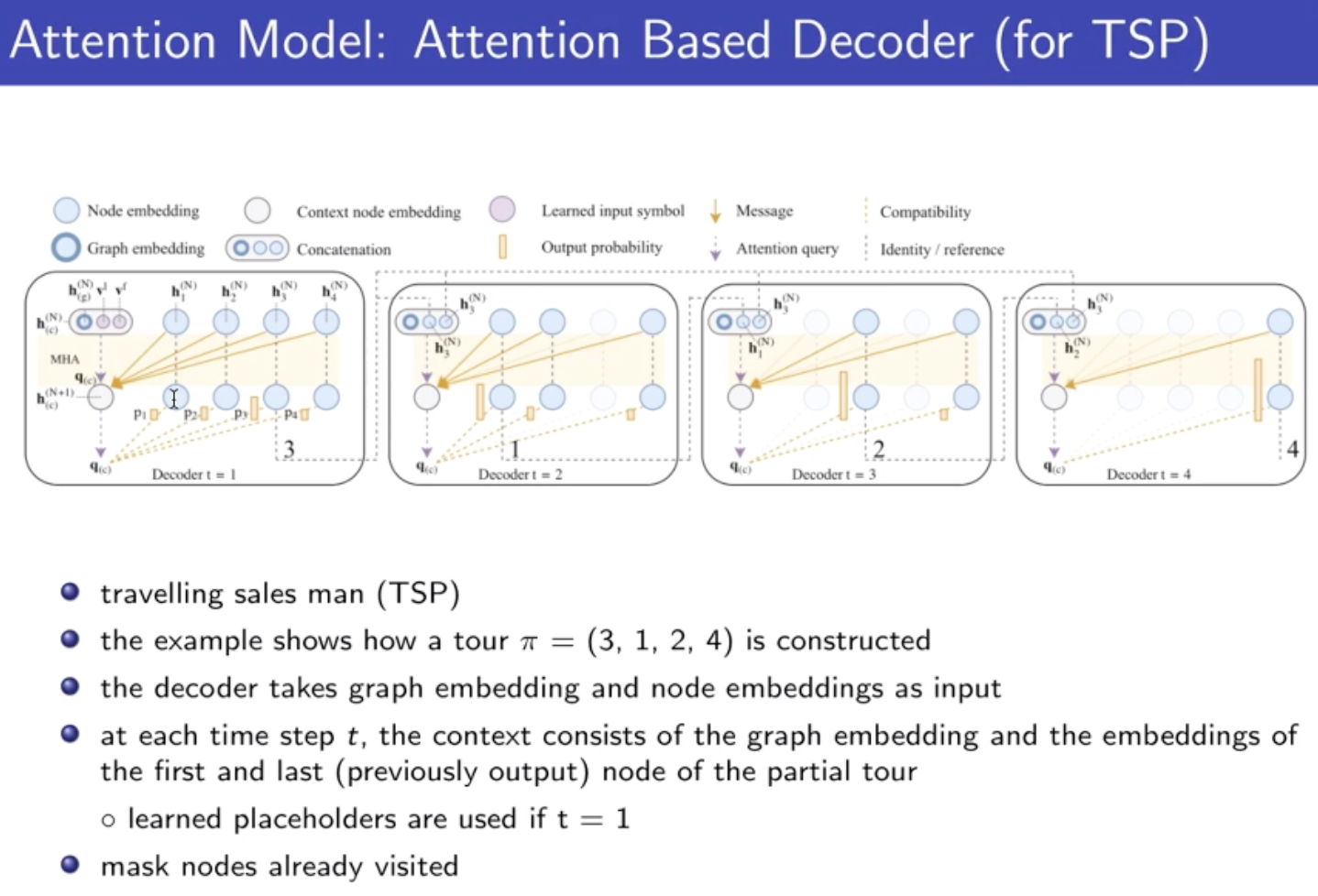



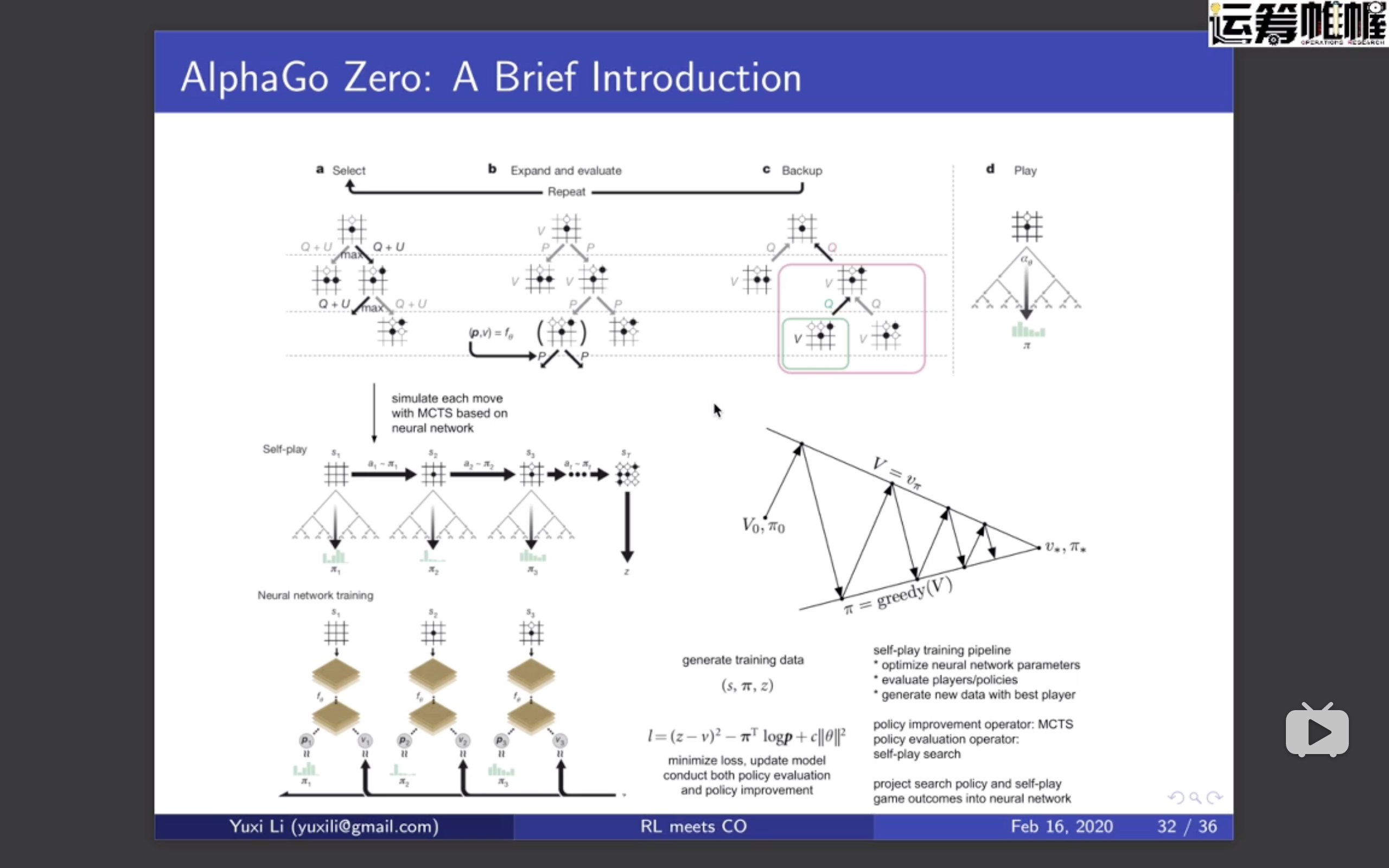
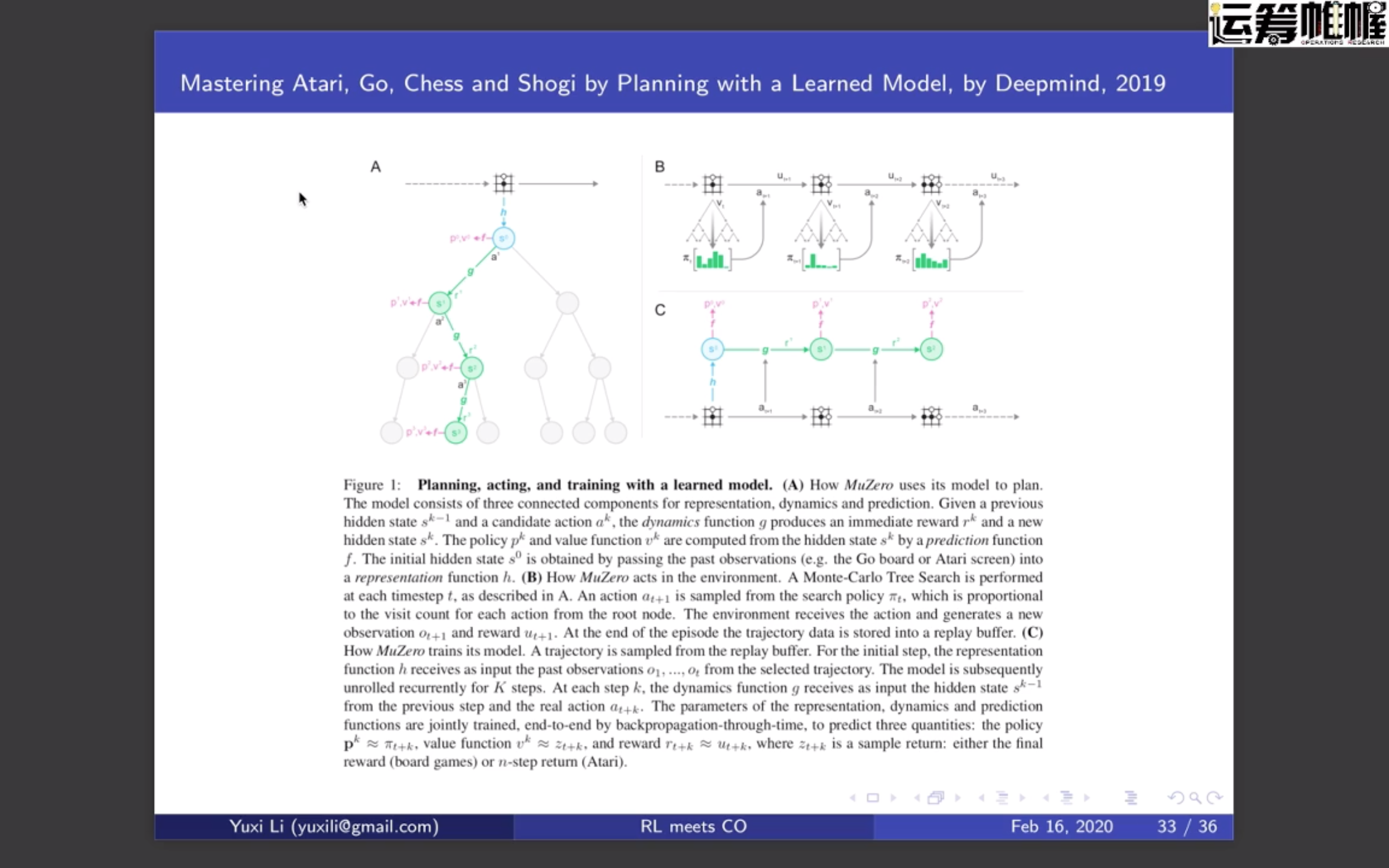
先学model ,再根据 model 学 policy;
对AlphaGO 批评:拥有完美的模型,棋盘又不会变等
有model 的好处:可以产生无数的数据,供我学 policy


(RL的语言)evolution 和 control 同时考虑


同学们对李老师的直播反响热烈,现场提问积极踊跃,比如:
-
请问怎么看这些年强化学习的发展方向?
-
请问您博士时期 RL 和现在 RL 研究课题有什么不同?
-
如何找到最优策略进行有效进行训练?
-
组合优化为什么不用传统方法解?
-
强化学习和最短路径可以结合吗?
-
现在单 agent rl sac 是不是最好?
-
不同分布的问题要单独训练模型,怎么处理?
-
请问 RL+某新领域应该如何考虑和入手呢?
-
如何构建结合 attention 的 RNN?
-
老师觉得多智能体强化学习前景怎样?
-
端对端解决组合优化前途好吗?
-
请问演化计算好找工作吗?感觉都是在搞科研?
-
基于 pointer 的方法过时了吗?
-
请问现在比较可靠的强化学习算法有哪些?
-
图神经网络解决组合优化怎么样?
-
GNN 和 RL 有何结合?
-
强化学习在设备故障诊断方面前景怎么样?
-
模仿学习或逆强化学习,有什么实用的方法吗?
-
端对端解决组合优化前途好吗?
-
端到端的最大优势就是快,LS 慢。请问该怎么看?
-
游戏能形成 local search 吗?
李老师就他最有心得的问题进行了耐心解答,受到了同学们的一致好评。
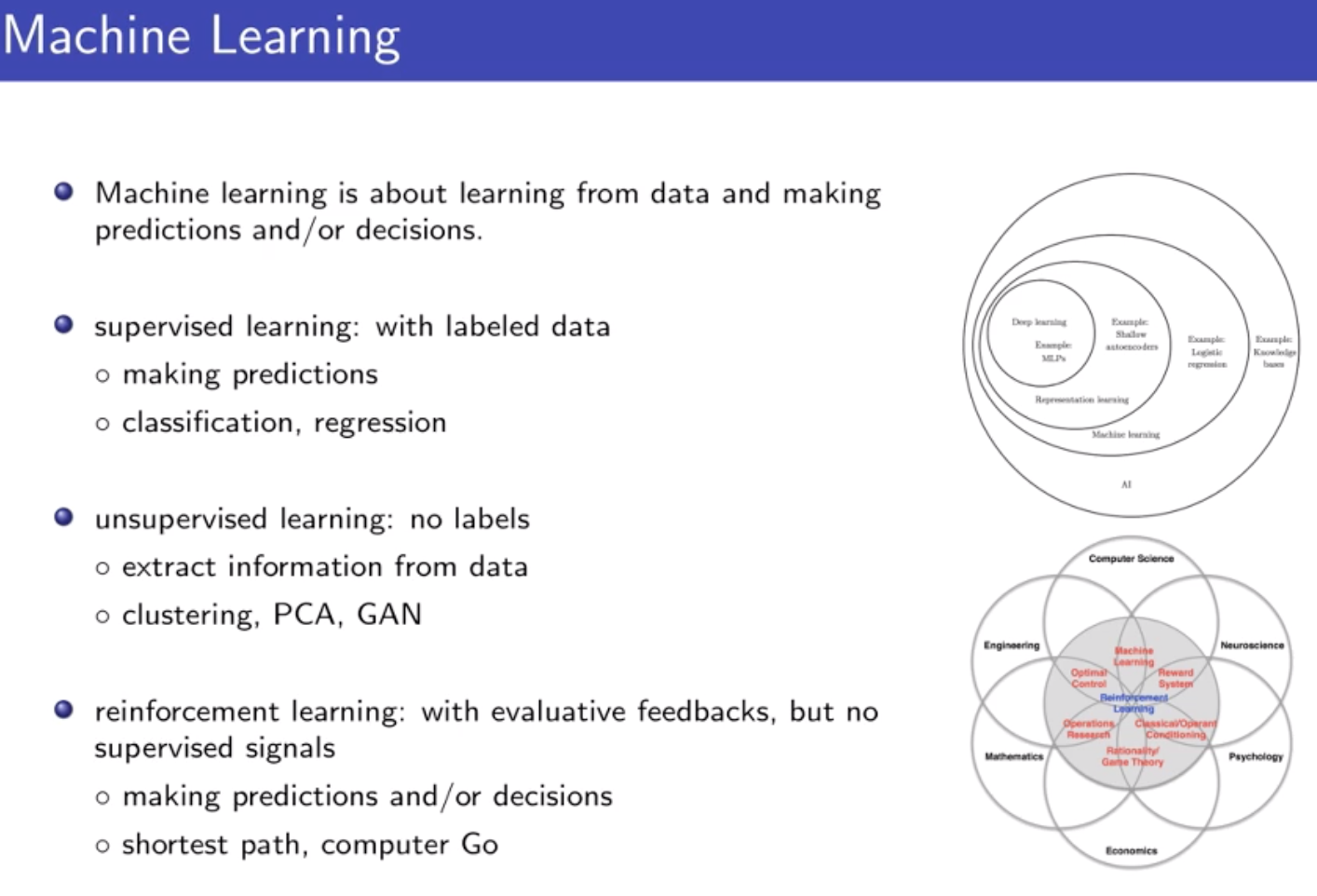
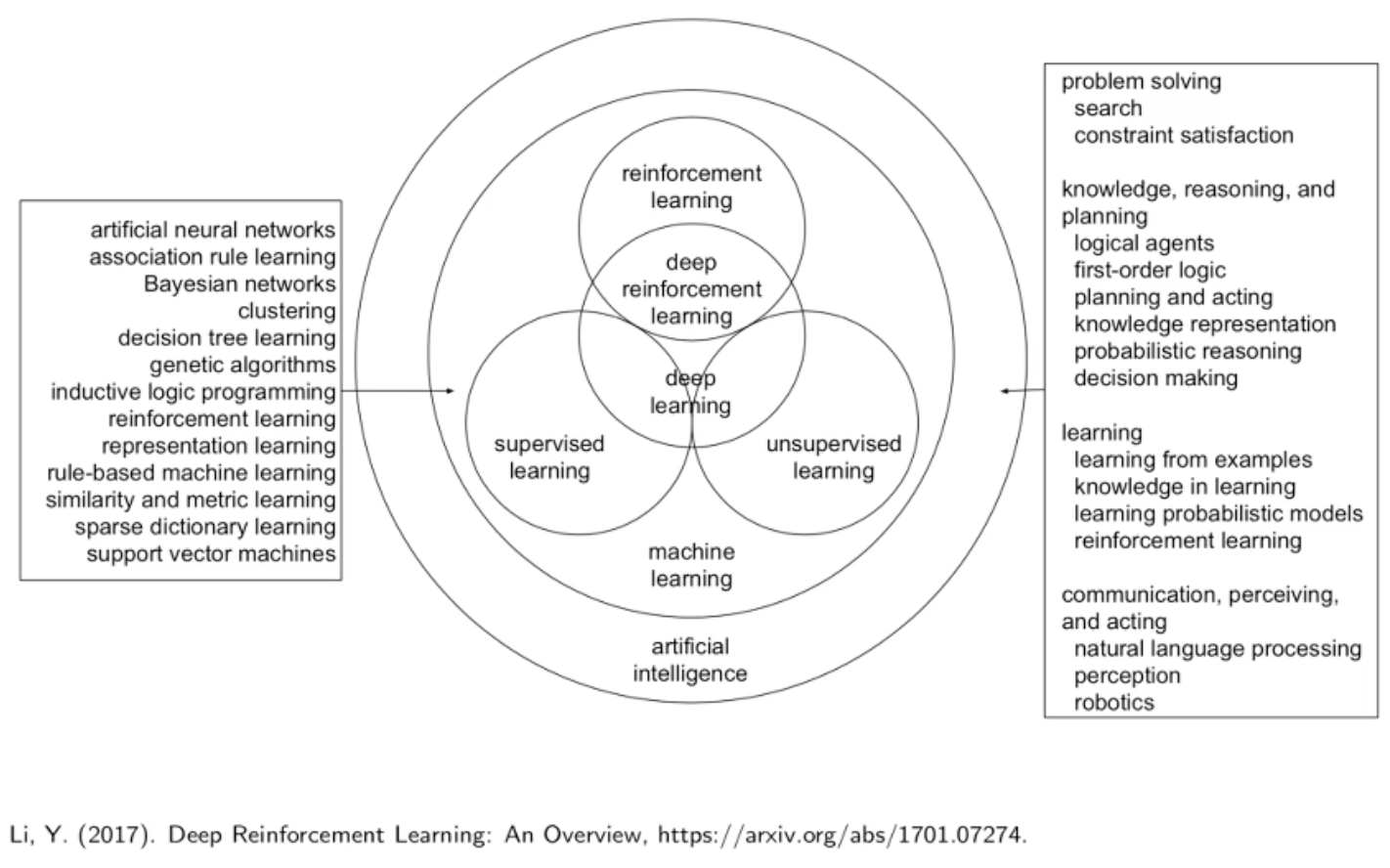
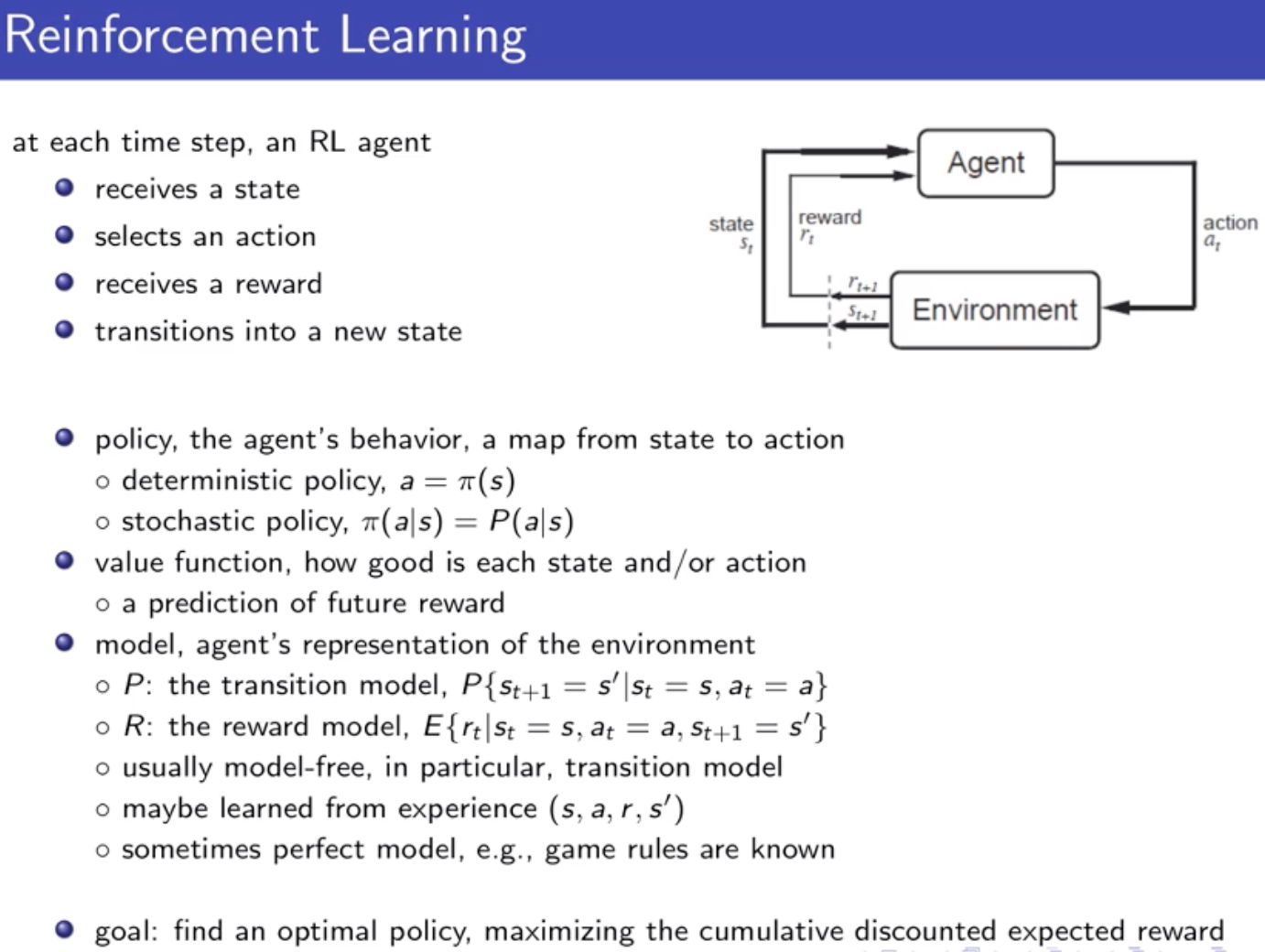
他指出:强化学习是一类通过试错来学习、预测、决策的序列决策方法框架。相比一般考虑一次性的问题、关注短期效益、考虑即时回报的监督学习,强化学习考虑的是序列问题,具有长远眼光,考虑长期回报。宽泛地说,强化学习有可能帮助自动化、最优化手动设计的策略。而深度强化学习则是使用了深度神经网络的强化学习。
meta learning : learning to learn