#include
- 处理过程:将头文件的内容插入到该命令所在的位置,从而把头文件和当前源文件连接成一个源文件,与复制粘贴的效果相同
- 使用尖括号
< >,编译器会到系统路径下查找头文件 - 使用双引号
" ",编译器首先在当前目录下查找头文件,如果没有找到,再到系统路径下查找(功能更强) - 一般使用尖括号来引入标准头文件,使用双引号来引入自定义头文件(自己编写的头文件)
- 同一个头文件可以被多次引入,多次引入的效果和一次引入的效果相同
- 不管是标准头文件,还是自定义头文件,都只能包含变量和函数的声明,不能包含定义,否则在多次引入时会引起重复定义错误
- 这种能够根据不同情况编译不同代码、产生不同目标文件的机制,称为条件编译。条件编译是预处理程序的功能,不是编译器的功能
多文件编程
- 多文件编程就是把多个头文件(
.h文件)和源文件(.c文件)组合在一起构成一个程序,这是C语言的重点,也是C语言的难点 - 对于多个文件的程序,通常是将函数定义放到源文件(
.c文件)中,将函数的声明放到头文件(.h文件)中,使用函数时引入对应的头文件就可以,编译器会在链接阶段找到函数体 - C语言代码是由上到下依次执行的,不管是变量还是函数,原则上都要先定义再使用,否则就会报错。但在实际开发中,经常会在函数或变量定义之前就使用它们,这个时候就需要提前声明
- 所谓声明(Declaration),就是告诉编译器我要使用这个变量或函数,你现在没有找到它的定义不要紧,请不要报错,稍后我会把定义补上
- 使用 printf()、puts()、scanf()、getchar() 等函数要引入 stdio.h 这个头文件,很多初学者认为 stdio.h 中包含了函数定义(也就是函数体),只要有了头文件程序就能运行。其实不然,头文件中包含的都是函数声明,而不是函数定义,函数定义都在系统库中,只有头文件没有系统库在链接时就会报错,程序根本不能运行
- 使用者往往只关心函数的功能和函数的调用形式,很少关心函数的实现细节,将函数定义放在最后,就是尽量屏蔽不重要的信息,凸显关键的信息。将函数声明放到 main() 的前面,在定义函数时也不用关注它们的调用顺序了,哪个函数先定义,哪个函数后定义,都无所谓了
- 函数的定义有函数体,函数的声明没有函数体,编译器很容易区分定义和声明,所以对于函数声明来说,有没有 extern 都是一样的
- 变量和函数不同,编译器只能根据 extern 来区分,有 extern 才是声明,没有 extern 就是定义
- 变量的定义有两种形式,你可以在定义的同时初始化,也可以不初始化
- 而变量的声明只有一种形式,就是使用 extern 关键字
- Visual Studio、Dev C++等 IDE 通常将编译和链接合并到一起,也就是构建(Build)或运行(Run)
- 从源代码生成可执行文件可以分为四个步骤,分别是预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)和链接(Linking)
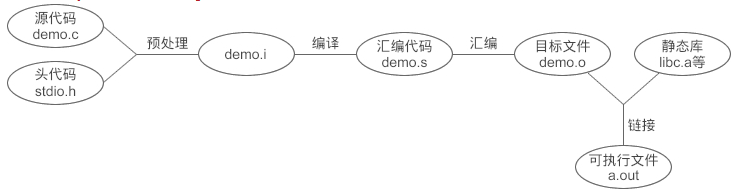
- 预处理过程主要是处理那些源文件和头文件中以
#开头的命令,比如 #include、#define、#ifdef 等 - 编译就是把预处理完的文件进行一些列的词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件
- 编译是针对单个源文件的,有几个源文件就会生成几个目标文件,并且在生成过程中不受其他源文件的影响
- 汇编的过程就是将汇编代码转换成可以执行的机器指令
- 链接的作用就是找到有些函数和全局变量的目标地址,将所有的目标文件组织成一个可以执行的二进制文件
- 现在PC平台上流行的可执行文件格式主要是 Windows 下的 PE(Portable Executable)和 Linux 下的 ELF(Executable Linkable Format),它们都是 COFF(Common File Format)格式的变种
- 在链接过程中,链接器会将多个目标文件中的代码段、数据段、调试信息等合并成可执行文件中的一个段
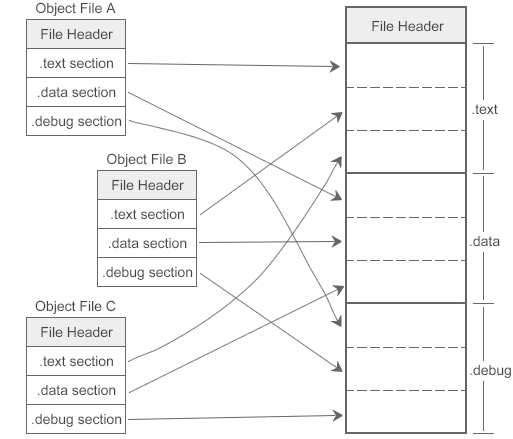
- 数据是保存在内存中的,对于计算机硬件来说,必须知道它的地址才能使用。变量名、函数名等仅仅是地址的一种助记符,目的是在编程时更加方便地使用数据,当源文件被编译成可执行文件后,这些标识符都不存在了,它们被替换成了数据的地址。编译器和链接器的一项重要任务就是将助记符替换成地址
- 汇编语言使用接近人类的各种符号和标记来帮助记忆,比如用
jmp表示跳转指令,用func表示一个子程序(C语言中的函数就是一个子程序)的起始地址,这种符号的方法使得人们从具体的机器指令和二进制地址中解放出来 - 符号(Symbol)这个概念随着汇编语言的普及被广泛接受,它用来表示一个地址,这个地址可能是一段子程序(后来发展为函数)的起始地址,也可以是一个变量的地址
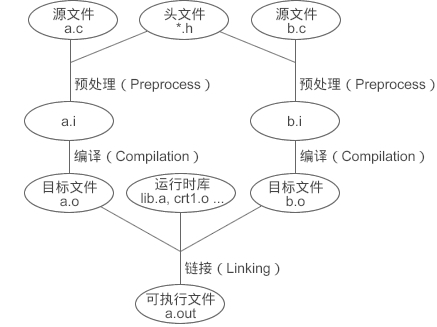
- 在C语言中,一个模块可以认为是一个源文件(.c 文件),在程序被分隔成多个模块后,需要解决的一个重要问题是如何将这些模块组合成一个单一的可执行程序。在C语言中,模块之间的依赖关系主要有两种:一种是模块间的函数调用,另外一种是模块间的变量访问
- 这种通过符号将多个模块拼接为一个独立的程序的过程就叫做链接(Linking)
- 链接的主要内容就是把各个模块之间的相互引用部分处理好,使得各个模块能够正确地衔接。链接器所做的主要工作跟前面提到的“人工调整地址”本质上没有什么两样
- 假设一个程序有两个模块 main.c 和 module.c,我们在 module.c 中定义了函数 func(),并在 main.c 中进行了多次调用,通过链接器,我们可以直接调用其他模块中的函数而无需知道它们的地址,因为在链接的时候,链接器会根据符号 func 自动去 module.c 模块查找 func 的地址,然后将 main.c 模块中所有使用到 func 的指令重新修正,让它们的目标地址成为真正的 func() 函数的地址
- 这种在程序运行之前确定符号地址的过程叫做静态链接(Static Linking);如果需要等到程序运行期间再确定符号地址,就叫做动态链接(Dynamic Linking)
- Windows 下的 .dll 或者 Linux 下的 .so 必须要嵌入到可执行程序、作为可执行程序的一部分运行,它们所包含的符号的地址就是在程序运行期间确定的,所以称为动态链接库(Dynamic Linking Library)
- 这种地址修正的过程就是前面提到的重定位,每个需要被修正的地方叫做一个重定位入口(Relocation Entry)。重定位所做的工作就是给程序中每个这样的绝对地址引用的位置“打补丁”,使它们指向正确的地址
- 函数和变量在本质上是一样的,都是地址的助记符,在链接过程中,它们被称为符号(Symbol)。链接器的一个重要任务就是找到符号的地址,并对每个重定位入口进行修正
- 我们可以将符号看做是链接中的粘合剂,整个链接过程正是基于符号才能正确完成
- 数据区在程序运行期间一直存在,全局变量的位置不会改变,地址也是固定的,所以在链接时就能够计算出全局变量的地址。而栈区内存会随着函数的调用不断被分配和释放,局部变量的地址不能预先计算,必须等到发生函数调用时才能确定,所以链接过程会忽略局部变量
- 总结起来,链接的一项重要任务就是确定函数和全局变量的地址,并对每一个重定位入口进行修正
- 我们在编写代码的过程中经常会遇到一种叫做符号重复定义(Multiple Definition)的错误,这是因为在多个源文件中定义了名字相同的全局变量,并且都将它们初始化了
- 在C语言中,编译器默认函数和初始化了的全局变量为强符号(Strong Symbol),未初始化的全局变量为弱符号(Weak Symbol)
- 链接器会按照如下的规则处理被多次定义的强符号和弱符号:
1) 不允许强符号被多次定义,也即不同的目标文件中不能有同名的强符号;如果有多个强符号,那么链接器会报符号重复定义错误
2) 如果一个符号在某个目标文件中是强符号,在其他文件中是弱符号,那么选择强符号
3) 如果一个符号在所有的目标文件中都是弱符号,那么选择其中占用空间最大的一个 - 在 GCC 中,可以通过
__attribute__((weak))来强制定义任何一个符号为弱符号 - 需要注意的是,
__attribute__((weak))只对链接器有效,对编译器不起作用,编译器不区分强符号和弱符号,只要在一个源文件中定义两个相同的符号,不管它们是强是弱,都会报“重复定义”错误 - 弱符号对于库来说十分有用,我们在开发库时,可以将某些符号定义为弱符号,这样就能够被用户定义的强符号覆盖,从而使得程序可以使用自定义版本的函数,增加了很大的灵活性
- 所谓引用(Reference),是指对符号的使用
- 目前我们所看到的符号引用,在所有目标文件被链接成可执行文件时,它们的地址都要被找到,如果没有符号定义,链接器就会报符号未定义错误,这种被称为强引用(Strong Reference)
- 与之相对应的还有一种弱引用(Weak Reference),如果符号有定义,就使用它对应的地址,如果没有定义,也不报错
- 弱引用和强引用非常利于程序的模块化开发,我们可以将程序的扩展模块定义为弱引用,当我们将扩展模块和程序链接在一起时,程序就可以正常使用;如果我们去掉了某些模块,那么程序也可以正常链接,只是缺少了某些功能,这使得程序的功能更加容易裁剪和组合
.c和.h文件都是源文件,除了后缀不一样便于区分外和管理外,其他的都是相同的,在.c中编写的代码同样也可以写在.h中,包括函数定义、变量定义、预处理等- 但是,.h 和 .c 在项目中承担的角色不一样:.c 文件主要负责实现,也就是定义函数和变量;.h 文件主要负责声明(包括变量声明和函数声明)、宏定义、类型定义等。这些不是C语法规定的内容,而是约定成俗的规范,或者说是长期形成的事实标准
- 根据这份规范,头文件可以包含如下的内容:
- 可以声明函数,但不可以定义函数
- 可以声明变量,但不可以定义变量
- 可以定义宏,包括带参的宏和不带参的宏
- 结构体的定义、自定义数据类型一般也放在头文件中
- 在项目开发中,我们可以将一组相关的变量和函数定义在一个 .c 文件中,并用一个同名的 .h 文件(头文件)进行声明,其他模块如果需要使用某个变量或函数,那么引入这个头文件就可以
- 这样做的另外一个好处是可以保护版权,我们在发布相关模块之前,可以将它们都编译成目标文件,或者打包成静态库,只要向用户提供头文件,用户就可以将这些模块链接到自己的程序中
- 源文件通过编译可以生成目标文件(例如 GCC 下的 .o 和 Visual Studio 下的 .obj),并提供一个头文件向外暴露接口,除了保护版权,还可以将散乱的文件打包,便于发布和使用
- 实际上我们一般不直接向用户提供目标文件,而是将多个相关的目标文件打包成一个静态链接库(Static Link Library),例如 Linux 下的 .a 和 Windows 下的 .lib
- 打包静态库的过程很容易理解,就是将多个目标文件捆绑在一起形成一个新的文件,然后再加上一些索引,方便链接器找到,这和压缩文件的过程非常类似
- C语言在发布的时候已经将标准库打包到了静态库,并提供了相应的头文件,例如 stdio.h、stdlib.h、string.h 等
- 在 Windows 下,标准库由 IDE 携带,如果你使用的是 Visual Studio,那么在安装目录下的
VCinclude文件夹中会看到很多头文件,包括我们常用的 stdio.h、stdlib.h 等;在VClib文件夹中有很多 .lib 文件,这就是链接器要用到的静态库 - ANSI C 标准共定义了 15 个头文件,称为“C标准库”,所有的编译器都必须支持,如何正确并熟练的使用这些标准库,可以反映出一个程序员的水平:
- 合格程序员:<stdio.h>、<ctype.h>、<stdlib.h>、<string.h>
- 熟练程序员:<assert.h>、<limits.h>、<stddef.h>、<time.h>
- 优秀程序员:<float.h>、<math.h>、<error.h>、<locale.h>、<setjmp.h>、<signal.h>、<stdarg.h>
- 除了C标准库,编译器一般也会附带自己的库,以增加功能,方便用户开发,争夺市场份额。这些库中的每一个函数都在对应的头文件中声明,可以通过 #include 预处理命令导入,编译时会被合并到当前文件
- 头文件包含命令 #include 的效果与直接复制粘贴头文件内容的效果是一样的,预处理器实际上也是这样做的,它会读取头文件的内容,然后输出到 #include 命令所在的位置
- 实际开发中,我们通常将不需要被其他模块调用的全局变量或函数用 static 关键字来修饰,static 能够将全局变量和函数的作用域限制在当前文件中,在其他文件中无效
- static 除了可以修饰全局变量,还可以修饰局部变量,被 static 修饰的变量统称为静态变量(Static Variable)
- 不管是全局变量还是局部变量,只要被 static 修饰,都会存储在全局数据区(全局变量本来就存储在全局数据区,即使不加 static)
- 全局数据区的数据在程序启动时就被初始化,一直到程序运行结束才会被操作系统回收内存;对于函数中的静态局部变量,即使函数调用结束,内存也不会销毁
- 全局数据区的变量只能被初始化(定义)一次,以后只能改变它的值,不能再被初始化,即使有这样的语句,也无效
- 相对路径(relative path)是从当前目录(文件夹)开始查找文件;当前目录是指需要引入头文件的源文件所在的目录,这也是本文开头提到的“当前路径”
- 在实际开发中,我们都是将头文件放在当前工程目录下,非常建议大家使用相对路径,这样即使后来改变了工程所在目录,也无需修改包含语句,因为源文件的相对位置没有改变
- 总起来说,相对路径要有“相对”的目标,这个目标可以是当前路径,也可以是系统路径,
< >和" "决定了到底相对哪个目标 - C语言代码由上到下依次执行,原则上函数定义要出现在函数调用之前,否则就会报错。但在实际开发中,经常会在函数定义之前使用它们,这个时候就需要提前声明
- 所谓声明(Declaration),就是告诉编译器我要使用这个函数,你现在没有找到它的定义不要紧,请不要报错,稍后我会把定义补上
- 有了函数声明,函数定义就可以出现在任何地方了,甚至是其他文件、静态链接库、动态链接库等
- 一般标准库编译的时候都在函数的最后,所以通常会先调用再定义,这是就需要声明,这也就是头文件的意义,同样,自己定义的函数,通过头文件的声明,就可以多次被其他文件中的函数调用,不必在每个文件的开头先声明一遍
- 区分声明、定义、赋值
参考:
https://blog.csdn.net/skk18739788475/article/details/79643978