概述
- 流式计算,本质上是增量计算,需要不断查询过去的状态
概念
- Streams(流):分为有界流(固定大小,不随时间增加而增长)和无界流(随时间增加而增长),
- State(状态):在进行流式计算过程中的信息,用于容错恢复和持久化
- Time(时间):支持Event time、Ingestion time、Processing time等,用来判断业务状态是否滞后或延迟
- API:分为SQL/Table API、DataStream API、ProcessFunction三层
集群
- JobManager:集群管理者,负责调度任务,协调checkpoints、协调故障恢复,收集Job状态,管理TaskManager
- TaskManager:实际执行计算的Worker,在其上执行Flink Job 的一组Task,将所在节点的服务器信息如内存、磁盘、任务运行情况等向JobManager汇报
- Clinent:将任务提交到集群,根据用户参数选择提交模式(yarn per job,stand-alone,yarn-session)
模型
- DataStream 的编程模型包括四个部分:Environment、DataSource、Transformation、Sink
- DataSource(数据源):文件、Collection、Socket、自定义
- Sink(数据目标):Kafka、Elasticsearch、RabbitMQ、Cassandra、Redis
- 每个数据流起始于一个或多个Source,并终止于一个或多个Sink
资源
- 一个TaskManager就是一个JVM进程,会用独立的线程来执行Task
- 每个TaskManager为集群提供Slot,每个task slot代表了TaskManager的一个固定大小的资源子集,slot数一般为每个节点的cpu核数
- 一个Flink程序由多个任务组成(source、transformation和 sink)
- 一个任务由多个并行的实例(线程)来执行,一个任务的并行实例 (线程) 数目就被称为该任务的并行度
优点
- 架构:主从模式
- 容错:基于两阶段提交,实现了精确的一次处理语义
- 反压:当消费者速度低于生产者时,需要消费者将信息反馈给生产者,使二者速度匹配,Flink使用分布式阻塞队列实现
连接器
- Kafka
- Redis
- ElasticSearch
算子
- Map:接受一个元素作为输入,根据开发者自定义的逻辑处理后输出


1 class StreamingDemo { 2 public static void main(String[] args) throws Exception { 3 4 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); 5 //获取数据源 6 DataStreamSource<MyStreamingSource.Item> items = env.addSource(new MyStreamingSource()).setParallelism(1); 7 //Map 8 SingleOutputStreamOperator<Object> mapItems = items.map(new MapFunction<MyStreamingSource.Item, Object>() { 9 @Override 10 public Object map(MyStreamingSource.Item item) throws Exception { 11 return item.getName(); 12 } 13 }); 14 //打印结果 15 mapItems.print().setParallelism(1); 16 String jobName = "user defined streaming source"; 17 env.execute(jobName); 18 } 19 }
- FlatMap:接受一个元素,返回0到多个元素,和Map的区别是,当返回值是列表时,FlatMap会将列表平铺,以单个元素的形式输出
1 SingleOutputStreamOperator<Object> flatMapItems = items.flatMap(new FlatMapFunction<MyStreamingSource.Item, Object>() { 2 @Override 3 public void flatMap(MyStreamingSource.Item item, Collector<Object> collector) throws Exception { 4 String name = item.getName(); 5 collector.collect(name); 6 } 7 });
- Filter:过滤掉不需要的数据,每个元素都会被Filter处理,如果Filter函数返回true则保留,否则丢弃
1 SingleOutputStreamOperator<MyStreamingSource.Item> filterItems = items.filter(new FilterFunction<MyStreamingSource.Item>() { 2 @Override 3 public boolean filter(MyStreamingSource.Item item) throws Exception { 4 5 return item.getId() % 2 == 0; 6 } 7 });
- KeyBy:根据数据的某种属性分组,然后对不同的组采取不同的处理方式
- Aggregations:聚合函数,常见的有sum、max、min等,需要指定一个key进行聚合
- Reduce:按照用户自定义逻辑进行分组聚合
状态
- Flink框架的计算是有状态的
- 状态即中间计算结果,是在流处理过程中需要记住的数据,包括业务数据和元数据
- 状态存储在JVM中
- Flink支持不同类型的状态,对状态的持久化提供专门机制和状态管理器
- 对于任何一个状态数据,可以设置过期时间(TTL)
- 基本类型:是否按照某个key进行分区
- Keyed State:每个key都有自己的状态
- Operator State(Keyed State):每个算子实例共享一个状态
容错
- Checkpoint
窗口
- 滚动窗口
- 滑动窗口
- 会话窗口
时间
- 生成时间
- 接入时间
- 处理时间
水位
- 由于网络延迟等因素,事件数据往往不能即使传递至Flink系统中,导致系统的不稳定或数据乱序
- 衡量数据处理进度,确保事件数据全部到达Flink系统,即使乱序或迟到,也能像预期一样计算出正确和连续的结果
- 任何Event进入Flink系统,都会根据当前最大事件时间产生Watermarks时间戳
广播变量
- 允许在每台机器上保持一个只读的缓存变量,即一个公共的共享变量
- 可以把一个dataset数据集广播出去,然后不同的task在节点上都能获取到
案例
- 安装flink
- tar -zxvf flink-1.9.2-bin-scala_2.11.tgz -C ~/training/
- 修改flink配置文件
- vim flink-conf.yaml
- 启动hadoop,zookeeper,flink
- bin/start-cluster.sh
- socket数据源
- nc -lk 9999
- 在idea中创建maven工程,开发计数程序
FlinkStreaming.scala
1 package com.kaikeba.demo1 2 3 import org.apache.flink.runtime.state.filesystem.FsStateBackend 4 import org.apache.flink.streaming.api.CheckpointingMode 5 import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup 6 import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} 7 import org.apache.log4j.{Level, Logger} 8 9 //导入隐式转换的包 10 import org.apache.flink.api.scala._ 11 12 /** 13 * flink接受socket数据,进行单词计数 14 */ 15 object FlinkStream { 16 Logger.getLogger("org").setLevel(Level.ERROR) 17 18 def main(args: Array[String]): Unit = { 19 //todo:1、构建流处理的环境 20 val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment 21 22 //todo:2、从socket获取数据 23 val sourceStream: DataStream[String] = environment.socketTextStream("bigdata111",9999) 24 25 //todo:3、对数据进行处理 hadoop spark 26 val result: DataStream[(String, Int)] = sourceStream 27 .flatMap(x => x.split(" ")) //按照空格切分 28 .map(x => (x, 1)) //每个单词计为1 29 .keyBy(0) //按照下标为0的单词进行分组 30 .sum(1) //按照下标为1累加相同单词出现的1 31 32 33 //todo: 4、对数据进行打印 sink 34 result.print() 35 36 37 //todo: 5、开启任务 38 environment.execute("FlinkStream") 39 } 40 41 }
FlinkWordCount.scala
1 package com.kaikeba.demo1 2 3 import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} 4 import org.apache.flink.streaming.api.windowing.time.Time 5 6 /** 7 * 使用滑动窗口 8 * 每隔1秒钟统计最近2秒钟的每个单词出现的次数 9 */ 10 object FlinkStream { 11 12 def main(args: Array[String]): Unit = { 13 //构建流处理的环境 14 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment 15 16 //从socket获取数据 17 val sourceStream: DataStream[String] = env.socketTextStream("node01",9999) 18 19 //导入隐式转换的包 20 import org.apache.flink.api.scala._ 21 22 //对数据进行处理 23 val result: DataStream[(String, Int)] = sourceStream 24 .flatMap(x => x.split(" ")) //按照空格切分 25 .map(x => (x, 1)) //每个单词计为1 26 .keyBy(0) //按照下标为0的单词进行分组 27 .timeWindow(Time.seconds(2),Time.seconds(1)) //每隔1s处理2s的数据 28 .sum(1) //按照下标为1累加相同单词出现的次数 29 30 //对数据进行打印 31 result.print() 32 33 //开启任务 34 env.execute("FlinkStream") 35 } 36 37 }
- 打包jar文件,提交到yarn
- ~/training/flink-1.9.2/bin/flink run -m yarn-cluster -yjm 1024 -c com.kaikeba.demo1.FlinkStream original-flask_demo-1.0-SNAPSHOT.jar
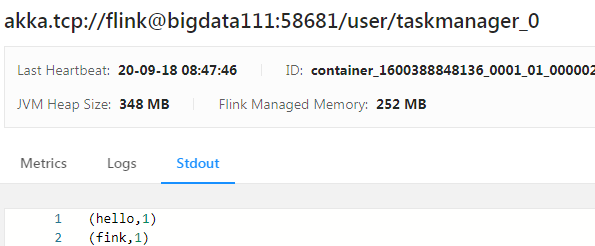
- 查看结果
- http://bigdata111:8088


参考
Spark Streaming 和 Flink
https://blog.csdn.net/csdnnews/article/details/81518143
读写MySQL
https://blog.csdn.net/hyy1568786/article/details/105886518/
Flink 和 kafka
https://blog.csdn.net/SqrsCbrOnly1/article/details/100011933
State
https://blog.csdn.net/mhaiy24/article/details/102707958
Flink 广播
https://blog.csdn.net/nazeniwaresakini/article/details/107404951
https://www.jianshu.com/p/520376ae837e
Flink 状态
https://blog.csdn.net/mhaiy24/article/details/102707958
Flink入门到项目
https://blog.csdn.net/lp284558195/article/details/92798595
Flink 使用 broadcast 实现维表或配置的实时更新
https://blog.csdn.net/tzs_1041218129/article/details/105283325
flink+kafka实现wordcount实时计算+错误解决方案
https://blog.csdn.net/xiaoyutongxue6/article/details/88861087
flink流处理访问mysql