概述
- Spark基于Scala开发
- 基于jdk
- 多范式编程语言
- 面向对象:和java一样
- 函数式:代码简洁;可读性差,尤其是隐式类 / 函数 / 参数
运行环境
- REPL:命令行
- IDE:Eclipse 或 IDEA
命令
- 变量+.+Tab:查看可用函数
数据类型
- 没有基本数据类型,任何数据都是对象
- 定义变量(var)和常量(val)时,可不指定数据类型,Scala会自动进行数据推导

- Byte:8位有符号数字
- Short:16位有符号数字
- Int:32位有符号数字
- Long:64位有符号数字
- Char:字符
- String:字符串
- Unit:相当于Java中的void
- Noting:执行过程中产生Exception
函数
- 内置函数

- 自定义函数
- 没有return语句,函数最后一句话就是函数的返回值

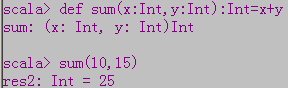

- 循环
- s <- list:提取list中的每个元素
- 求值策略
- call by value:定义 :,对函数实参求值,且只求一次,如下图中bar函数没用到x也求值
- call by name:定义:=>,在函数体内部,每次用到时求值,如下图中bar函数没用到y就不求值

参数
- 默认参数
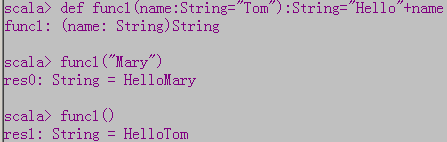
- 代名参数
- 多个默认参数,赋给哪个

- 可变参数

懒值
- 常量如果是lazy的,初始化会被推迟到第一次使用的时候
- Spark的核心是RDD(数据集合),操作数据集合中的数据需要使用算子(函数、方法)
- Transformation:延时加载,不触发计算
- Action:触发计算

例外
- try...catch...finally
数组
- 定长数组:Array
![]()
- 变长数组:ArrayBuffer


- 多维数组

映射
- <key,value>对,用Map表示

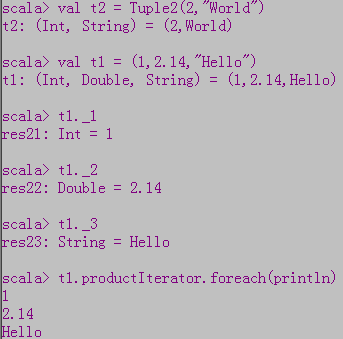
元组
- 不同数据类型数据的集合
参考
https://www.scala-lang.org/files/archive/api/2.11.8/#package
Scala中的"- >"和" -"以及"=>"