技术选型
- 数据采集
- 大数据平台和关系型数据库的导入导出:Sqoop、datax
- 日志数据的采集和解析:flume、logstash
- 实时解析mysql的binlog数据:maxwell、canal、waterDrop
- 消息中间件
- RabiitMQ
- Kafka
- Redis
- 实时流处理技术
- Storm:现在基本不用
- SparkStreaming:非结构化数据
- StructStreaming:结构化数据
- Flink:使用较多
- 永久存储
- HFDS:分布式文件存储系统
- Hbase:K-V对的nosql数据库
- Kudu:类似Hbase
- 离线计算框架(OLAP)
- MapReduce:分布式文件计算系统
- Hive:基于MR数仓
- Impala:速度快,内存消耗大
- SparkSQL
- FinkSQL
- clickHouse
数据格式
项目构建
数据生成
- 数据回放
- java -jar bin/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar /root/kkb/datas/sourcefile/chengdu /root/kkb/datas/destfile/chengdu 3000
- ps -ef | grep FileOperate-1.0-SNAPSHOT-jar | grep -v grep
- flume
- bin/flume-ng agent -n a1 -f conf/flume-client.conf -c conf -Dflume.root.logger=INFO,console
- kafka
- bin/kafka-server-start.sh config/server.properties &
- bin/kafka-topics.sh --create --zookeeper bigdata111:2181 --replication-factor 1 --partitions 3 --topic cheng_du_gps_topic
- bin/kafka-console-consumer.sh --bootstrap-server bigdata111:9092 --topic cheng_du_gps_topic
- 启动顺序:数据生成--flume--kafka消费

将数据保存到HBase
- HBse建表
- create 'hbase_offset_store','f1','f2'
- create 'HTAB_GPS','f1','f2'
- 运行SparkStreaming程序

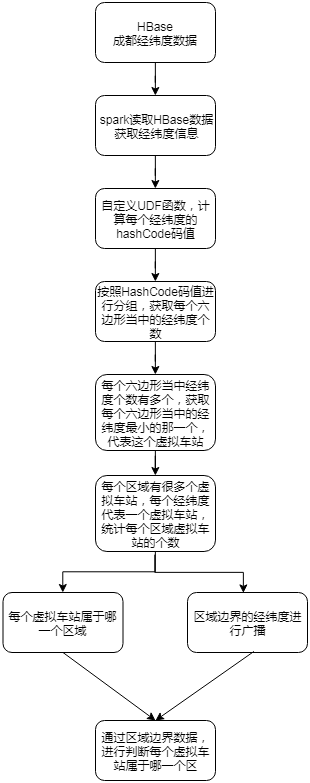
虚拟车站
- uber h3 算法
- 统计虚拟车站数据,保存在HBase中,通过phoenix映射,用javaWeb查询
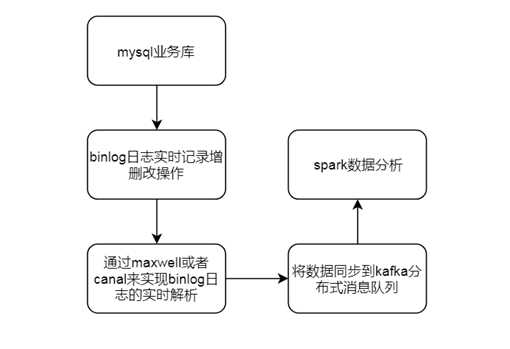
业务库功能开发
- 通过maxwell,解析业务库mysql的binlog,将业务数据实时同步到kafka
- SparkStreaming解析kafka数据,存入Hbase
- sparkSQL自定义数据源,获取Hbase中数据,并将查询结果保存到Hbase中
- 监控页面大屏开发,写sql
问题
- 面试怎么说项目
- 细节:业务逻辑、功能模块、负责的功能职责、遇到了哪些问题、日常工作、服务器配置、数据量大小
- 为什么要把kafka的offset保存到hbase
- kafka保存offset会过期
- kafka 中 topic consum_offset 默认50个分区,一个副本,存在数据丢失问题
- 方便控制hbase的offset值,实现数据重复消费功能
- maven dependency 飘红
- 用课程的maven仓库覆盖本地的
- 删除maven仓库中lastupdate
- 打开idea
- 查询Hbase三种方式
- get
- scan 或 scan startRow stopRow
- phoenix:作为Hbase二级索引,通过sql语句查询
- phoenix全局索引及局部索引适用情况
- 大数据两种架构模型
- lambda:离线和实时分开,数据不一致,结果可能不一样
- kappa:通过消息中间件收集数据,实时和离线用同一套代码