安装
- root用户解压,修改配置文件
- 创建新用户es
- 修改文件权限:chown -R es:es /kkb/install/elasticsearch-6.7.0/
- 用es用户启动ElasticSearch和kibana
- kibana启动:nohup bin/kibana >/dev/null 2>&1 &
概念
- Relational DB:Databases -> Tables -> Rows -> Columns
- Elasticsearch:Indices -> Types -> Documents -> Fields
- 索引(Indices):对应MySQL中的库
- 类型(Types):对应MySQL中的表
- 文档(Documents):对应MySQL中的行
- 字段(Fields):对应MySQL中的列
- 映射(mapping):定义数据类型
- 分片(shards):将索引划分为多份,可以存放在任何节点上(每个索引默认5个)
- 复制(replicas):分片的拷贝,防止数据丢失(每个索引默认1个)
与DB差异
- ES不是关系数据库,不具备ACID特性,乐观锁VS乐观锁
- ES是近似实时数据库,不是实时数据库,内部基于refresh机制更新
- SQL VS Nosql
- 任何两个异构数据库同步都会有问题,一致性,实时性
与DB混搭
- DB全能(ACID),ES专长(海量查询)
- 技术需求
- 大数据量查询/关联查询,两个表作join,难以优化
- 弹性扩展能力,大宽表
- 业务需求
- 业务领域复杂度,水平分库分表
- 业务查询要求,多业务线联合查询
单数据表,单索引
- ES作为DB的映射
- DB作为数据源
- ES为查询引擎
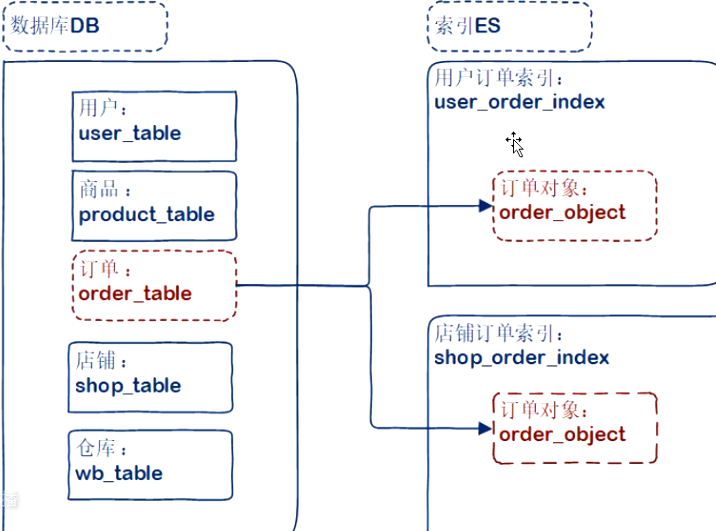
单数据表,多索引
- 同一DB表成为多个索引的数据

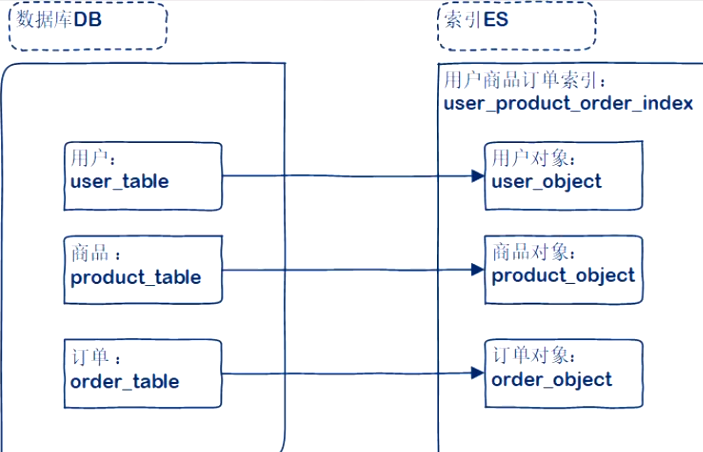
多数据表,单索引
- 多个DB表
- 一个索引
- 大宽表
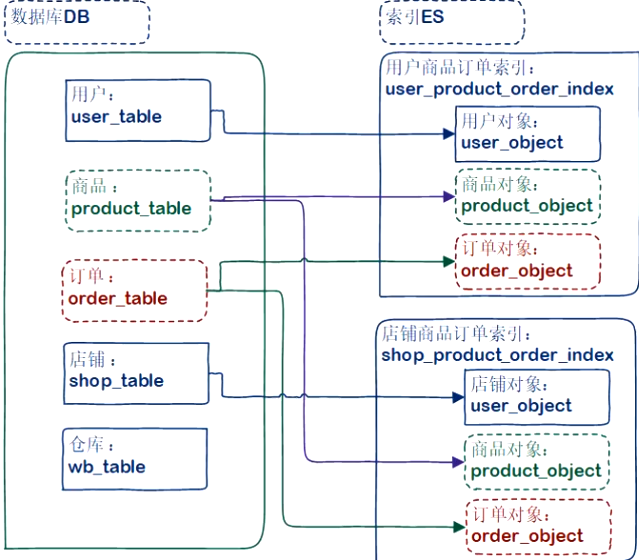
多数据表,多索引
- 多DB表映射多索引
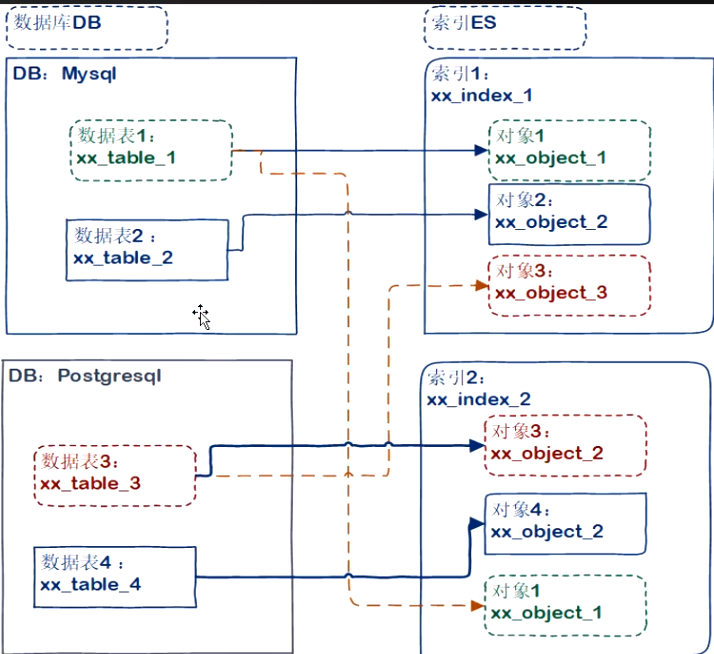
多数据源表,多索引
- 多种数据源
- 多种索引
- Sql/Nosql
同步模式
- 推Push:数据源主动推送
- 拉Pull:数据目标主动拉取
- 推拉结合Push+Pull

应用双写
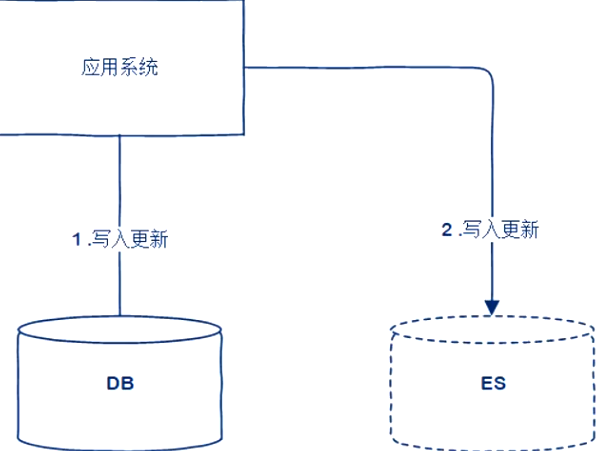
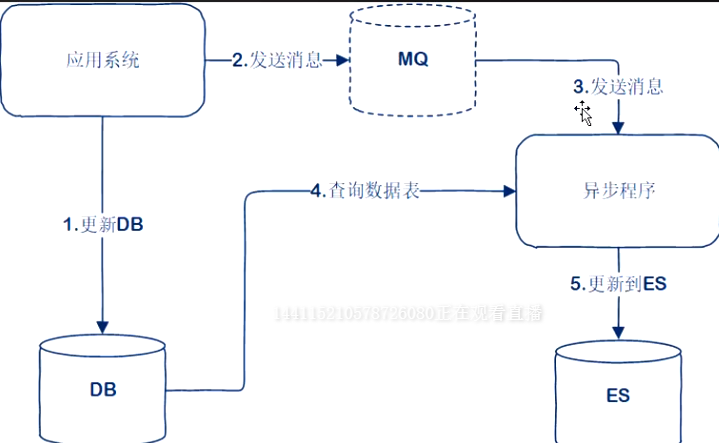
应用异步双写MQ
- 推拉结合
- 早期基于Lucene搜索
- 自主灵活
- 耦合高
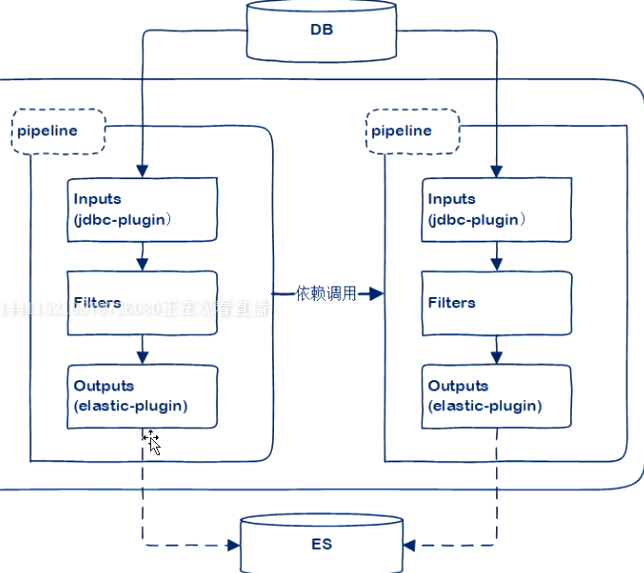
工具
- Logstash
- 拉Pull
- JDBC+CRON
- 单进程
Apache NiFi
- 上百节点,一天200TB
- 将Logstash平台化
SDC
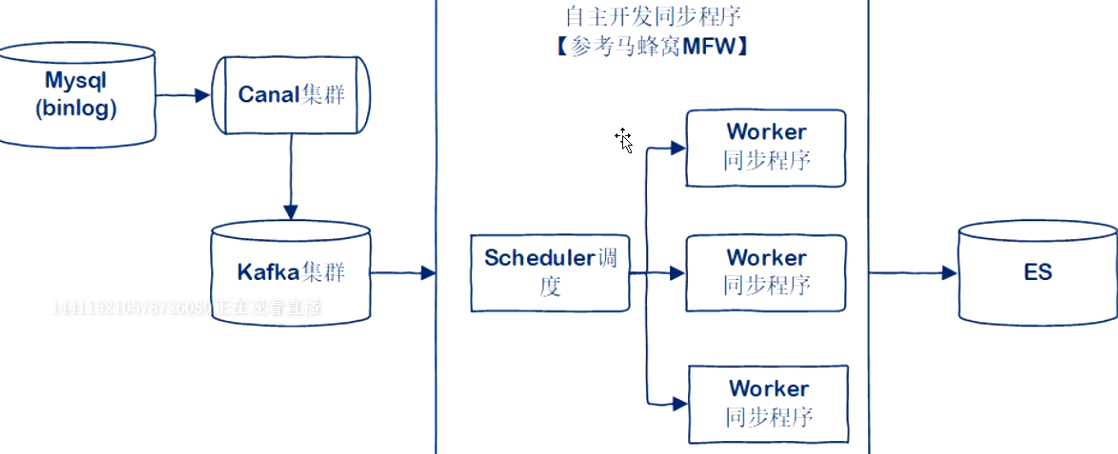
CDC(Change Data Capture)
- 推Push
- 基于数据库底层同步机制
- Mysql-binlog

自主开发同步程序
多数据源
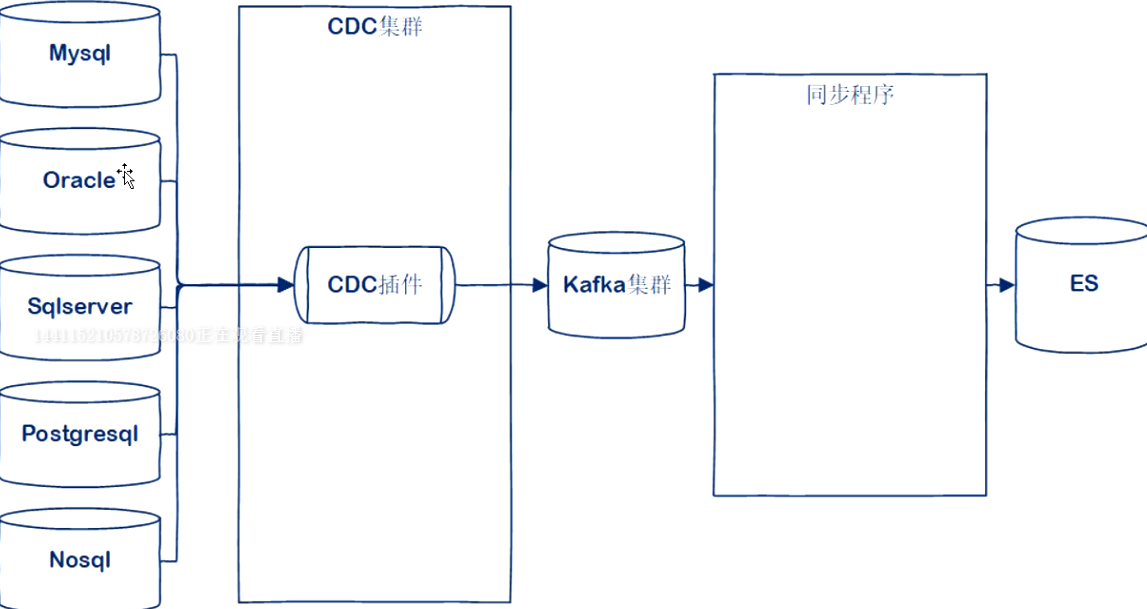
多数据源数据交换
- 没有统一解决方案

常用数据库
- 关系数据库(MySQL)
- 缓存(Redis)
- ES
操作
- curl :在命令行下面访问url的工具,可以简单实现常见的get/post请求。centos默认库里面是有curl工具,如果没有可通过yum安装
- -X 指定http的请求方法 有HEAD GET POST PUT DELETE
- -d 指定要传输的数据
- -H 指定http请求头信息
- restful:在kibana中操作
- java api
命令
- curl
curl -XPUT http://node01:9200/blog01/?pretty
curl -XPUT http://node01:9200/blog01/article/1?pretty -d '{"id": "1", "title": "What is lucene"}'
curl -XGET http://node01:9200/blog01/article/1?prettycurl -XPUT http://node01:9200/blog01/article/1?pretty -d '{"id": "1", "title": " What is elasticsearch"}'
curl -XGET "http://node01:9200/blog01/article/_search?q=title:elasticsearch"
curl -XDELETE "http://node01:9200/blog01/article/1?pretty"
curl -XDELETE http://node01:9200/blog01?pretty
- 增加数据(批量)
POST /school/student/_bulk
{ "index": { "_id": 1 }}
{ "name" : "liubei", "age" : 20 , "sex": "boy", "birth": "1996-01-02" , "about": "i like diaocan he girl" }
{ "index": { "_id": 2 }}
{ "name" : "guanyu", "age" : 21 , "sex": "boy", "birth": "1995-01-02" , "about": "i like diaocan" }
- 查询(全部)
GET /school/student/_search?pretty
{
"query": {
"match_all": {}
}
}
- 查询(关键字)
GET /school/student/_search?pretty
{
"query": {
"match": {"about": "travel"}
}
}
- mapping定义字段类型
DELETE school
PUT school
{
"mappings": {
"logs" : {
"properties": {"messages" : {"type": "text"}}
}
}
}
POST /school/_mapping/logs
{
"properties": {"number" : {"type": "text"}}
}
GET /school/_mapping/logs
- 管理分片和副本数
DELETE document
PUT document
{
"mappings": {
"article" : {
"properties":
{
"title" : {"type": "text"} ,
"author" : {"type": "text"} ,
"titleScore" : {"type": "double"}
}
}
}
}
GET /document/_settings
PUT /document/_settings
{
"number_of_replicas": 2
}
分片数初始定义后无法修改
参考
安装
https://cloud.tencent.com/developer/article/1595027
root用户无法启动
https://www.cnblogs.com/tree1123/p/13152267.html
hive数据存入ES
http://www.bubuko.com/infodetail-3047662.html
elasticsearch-head安装
https://www.chajianmi.com/topic/ffmkiejjmecolpfloofpjologoblkegm#download
https://blog.csdn.net/boss_way/article/details/105826584
基本操作
https://www.cnblogs.com/leohahah/p/10310214.html
分片异常
https://www.cnblogs.com/carryLess/p/9452000.html
kibana
https://blog.csdn.net/baidu_24545901/article/details/79031291
ES与Hive集成
https://blog.csdn.net/tototuzuoquan/article/details/102601040
Spark将Hive数据写入ES(将hive离线计算的结果通过spark任务导入es中以便业务功能快速查询)
https://blog.csdn.net/LXWalaz1s1s/article/details/109264520
SparkStreaming--Kafka--Hive--ES
https://blog.csdn.net/m0_37592814/article/details/105027815?