前段时间做商品评价的语义分析,需要大量的电商数据,于是乎就自己动手爬取京东的数据。第一次接触爬虫是使用selenium爬取CNKI的摘要,基于惯性思维的我仍然想用selenium+Firefox的方法爬取京东上的数据。代码就这样以selenium为框架写好了,但是效果一如既往的差,主要是耗时真的是太久了,即使是选择不加载图片等内容仍然有时效性的问题,所以我选择了scrapy爬取京东的电商数据。由于京东在页面展示的数据是后端分页,所以页面的URL不变而页面的内容随着一次次的请求而不断加载。如何获得动态网页的URL是本博客的重点,下面是如何获取京东网页URL的具体方法。希望借着这个例子让更多的人知道怎么获取动态页面URL。
1、在Chrome中打开我们我们需要的电商页面,比如:
2、 选择“商品评论”
3、 按电脑的F12键,在电脑的右半栏框中选择Network按键

(PS:如果没有显示内容,按F5刷新)
4、 在输入框中输入json
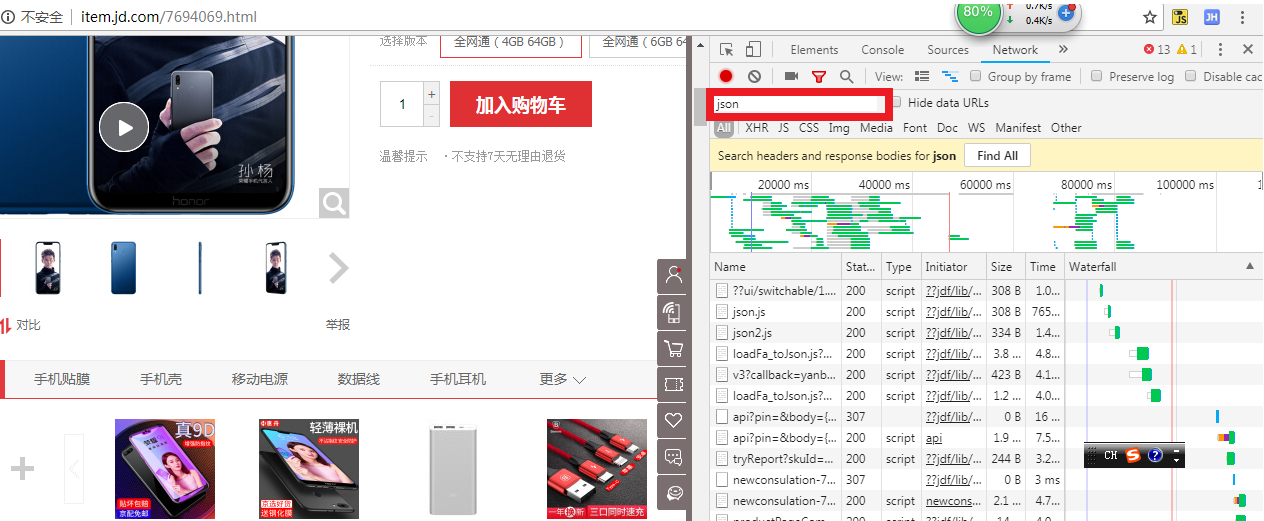
5、 在Network中出现的json文件里面会含有我们需要的评论数据
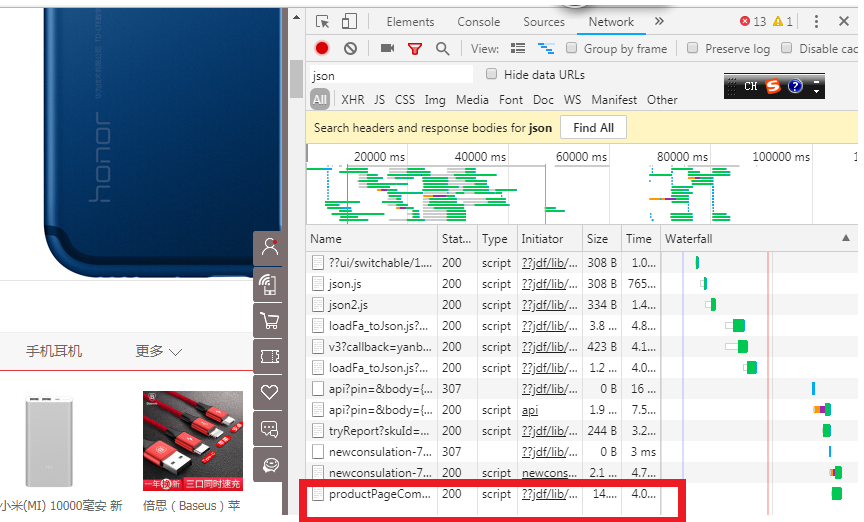
6、 对含有所需评论的文件单击右键,选择“Open in new tab”,则地址栏中的URL就是此时此刻真正的URL

(PS:为了更好在chrome中展示网页源码,建议下载插件JSON-handle)
7、 此处的URL是有规律的,多试几次就会找到!这样我们就可以很轻松的使用scrapy爬取京东商品评价数据了(亲测,有效)!