0. PairRDD的意思
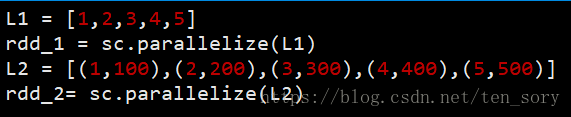
PairRDD就是元素为键值对的List转化过来的RDD对象,例如
rdd_1就是一般的非pairRDD,rdd_2为pairRDD对象,而有些SparkAPI操作是针对pairRDD对象的,例如后面将要介绍的mapValues()操作。
1. partitionBy()函数
rdd.partitionBy(int, function),可以对RDD对象分区,第一个参数是分区的个数,第二个对象是自定义分区函数,其作用暂时没弄清楚!
实验代码:
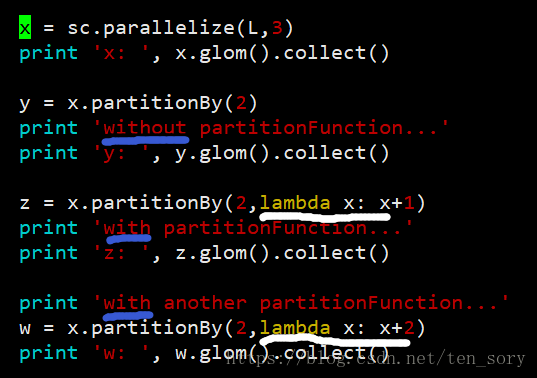
实验结果:
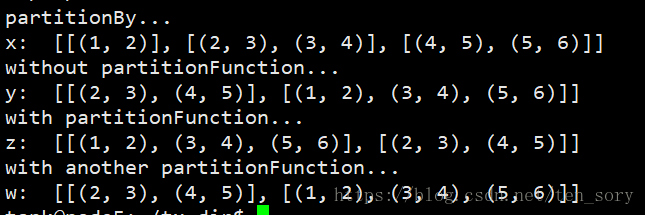
在创建RDD对象的时候,采用parallelize()分了3个区,之后用partitionBy()函数,分了2个区。
2. cache()函数
对于需要重复用到的且占用内存小的RDD对象,可以通过rdd.cache()存储起来,之后再次使用的时候,直接读取内存中的RDD对象,节省时间。
3. mapValues()函数
rdd.mapValues(func)对pairRDD的value进行map操作,不涉及key的操作,只会修改value。
实验代码:
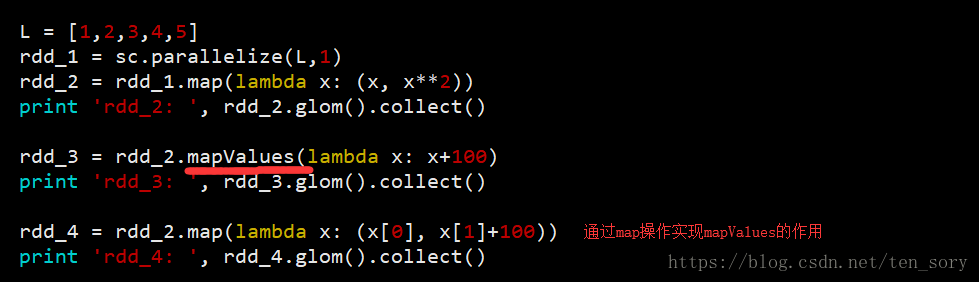
实验结果:

可以看出,通过map()函数可以实现mapValues()函数的功能。
4. sortBy()
用法为:rdd.sortBy(func, ascending, numPartitions)
该函数对RDD对象中的元素进行排序,第一个参数必选,其他参数可选,func指代根据什么标准进行排序,ascending为True的时候为True升序,反之为降序, 第三个参数numPartitions指定重新分区的个数。
实验代码:
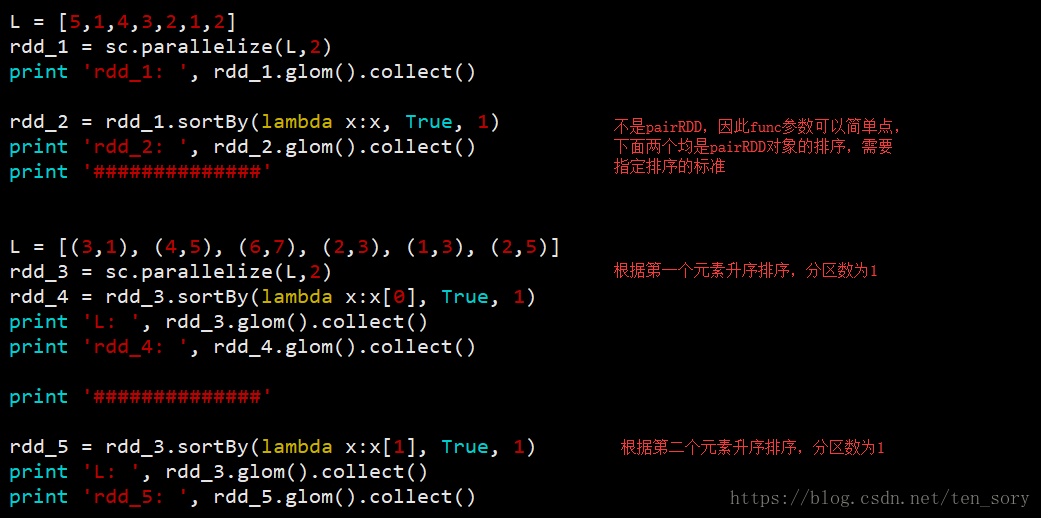
实验结果:
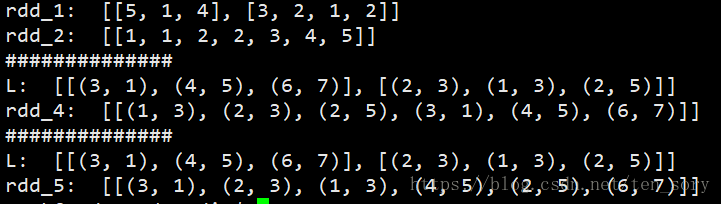
5. count(), countByValue()和countByKey()
count()用于计数RDD中元素个数。
countByValue()计数RDD中不同元素的相同value的个数,即根据value相同累加。
countByKey()根据key相同累加,这三个函数中,只有countByKey()只能用于pairRDD对象,其他二者无限制。
实验代码:
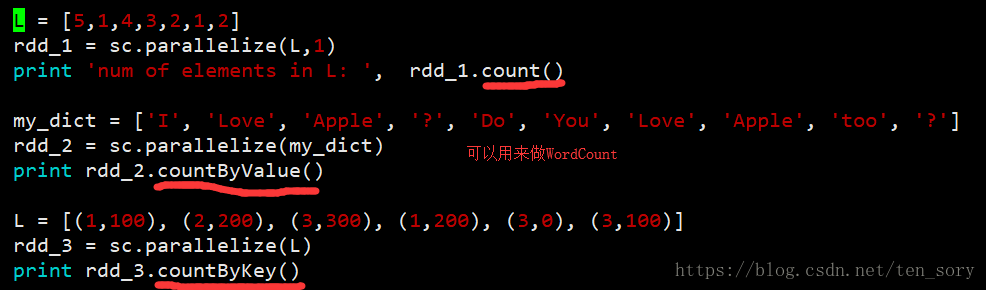
实验结果:

注意:countByValue()和countByKey()返回的都是map,不是List。
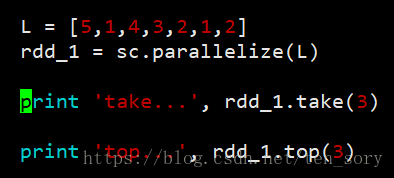
6. take()和top()
take()取RDD对象中的前几个元素,不排序
top()取RDD对象中的最大的几个元素,降序