今天我们来说一下我们的mysql,个人认为现在的mysql能做到很好的优化处理,不比收费的oracle差,而且mysql确实好用。
当我们查询慢的时候,我会做一系列的优化处理,例如分库分表,加索引。那么我们底层的索引到底长什么样子呢?为什么可以快速的查询出来数据呢,我们下面来解读一下mysql的索引。
在上面的博客里,我写过一篇基础的数据结构,基础的不能再基础了。https://www.cnblogs.com/cxiaocai/p/11235054.html 主要就是数组,链表,hash,队列,栈还有二叉树。
索引:
我们先来看一下简单的查找流程,现有一个mysql表table1,结构如下
我们要查找一下col1等于8的行数据,这时我们会逐行扫描我们的col1的数据,也就是说,我们需要扫描4次才能得到我们的结果,也就需要我们和磁盘进行4次IO操作。现在还好我们只有7条数据,如果现实中我们的表有700条数据呢??700万条数据呢?
最多可能经过700万次的IO才可以找到我们的数据。
我们来转换一下思路,我们将现有的行数据转化一下,变为我们的二叉树来试试。
我们知道二叉树右侧的节点一定比父节点要大,col1为1的现在为顶级节点,我们来简单画一下这个 二叉树。
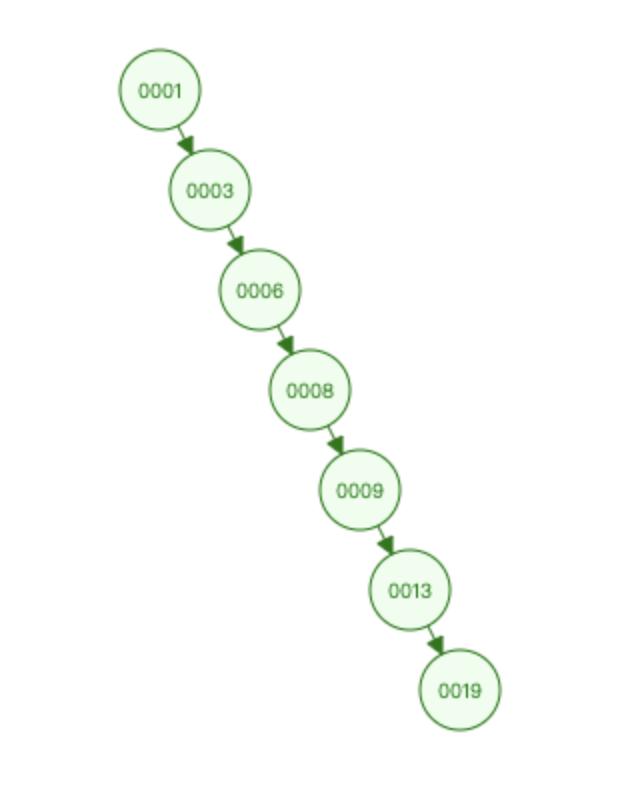 我们神奇的发现了,二叉树完全没有提高速度,看来二叉树是不可行的。
我们神奇的发现了,二叉树完全没有提高速度,看来二叉树是不可行的。
这时我们来尝试我们的红黑树(二叉平衡树)吧。上图,看图比较方便。
 这回貌似可以了,我们要得到col1为8的陈二这个数据,我们只需要两次IO就可以得到我们的数据了,但是,但是,我们的数据毕竟是模拟数据,我们要是700万的数据呢???这个红黑树的层级也会有很多吧,也会经过很多(2n)次的IO才可以得到我们的数据。看来优化了一点点,但还不是我们想要的结果。
这回貌似可以了,我们要得到col1为8的陈二这个数据,我们只需要两次IO就可以得到我们的数据了,但是,但是,我们的数据毕竟是模拟数据,我们要是700万的数据呢???这个红黑树的层级也会有很多吧,也会经过很多(2n)次的IO才可以得到我们的数据。看来优化了一点点,但还不是我们想要的结果。
我们来看看我们的Btree吧,我们先来百度一下什么是Btree,B-tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。按照翻译,B 通常认为是Balance的简称。这个数据结构一般用于数据库的索引,综合效率较高。
我们再来看一下我们的Btree树画出来的图。
 我们看到了Btree已经很棒了,但是mysql规定每个节点只能存储16K的元素,如果携带数据(回行问题后面说,别慌),数据很大,一个节点并存不了多少的数据。我们貌似还可以让他更快的。
我们看到了Btree已经很棒了,但是mysql规定每个节点只能存储16K的元素,如果携带数据(回行问题后面说,别慌),数据很大,一个节点并存不了多少的数据。我们貌似还可以让他更快的。
我们再来看看B+tree啥样的,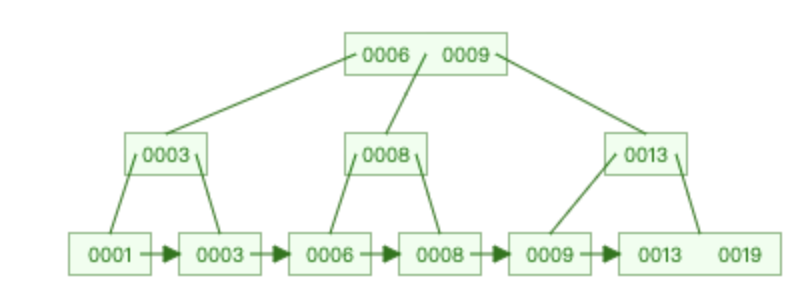
B+tree树的样子是这个样子的,我们可以看到,我们最终的叶子节点拥有所有的元素,也就是说B+tree,我们观察会发现,右侧叶子节点的元素都是>=我们的父元素,左侧的是小于我们的父元素。切记右侧是带等号,左侧不带啊~!这时我们看到,除叶子节点外,都不需要携带任何数据,也就充分应用了这个B+tree。
我们上述说的都是Btree索引,我们还知道有一个索引叫做Hash索引,也就是将我们索引进行hash操作,然后存在磁盘上。这时我们来查找的时候,我们会经过一次hash算法来快速的定位到我们的元素所在位置,然后取出来,这样看来我们hash的速度貌似比我们的Btree要效率很多啊,但在实际工作中,我们一般都是不用Hash索引的,Hash索引对于范围查找是没法处理的,所以我们采用Btree索引比较多的。
留下一个思考题啊,范围查询是怎么处理的。很多人会说,叶子节点带指针的,可以快速查找,那么,我们要查询小于3的和大于13的结果集呢?
很多人还会有疑问,说这个和红黑树比起来就是多了一个指针的嘛,其实不然,我们一个节点虽然只有16K,但是他存的数据是惊人的,每个元素占用8B,没个指针占用6B,那么我们可轻松得出每个几点可以存储1170个节点。假设我们每组元素占用1kb大小,也就是说,我们三层的树可以存2000多万的数据。
我们的B+tree还是很优秀的。我们的mysql真实的索引其实是对B+tree做了一定的优化处理,将我们上面看到的单向指针,优化成了双向的指针,也就是我们在查小于,向左也可以快速的定位到结果集。
查询引擎:
我们常见的查询引擎主要是MyISAM和InnoDB,我们来分别看一下这个两个查询引擎有什么区别。
MyISAM是一个非聚簇索引,也就是说 ,叶子节点上并没有携带数据,我们需要回行操作。磁盘上为三个文件,一个存储的是表的结构,一个存的是索引,一个是数据文件。MyISAM的主键索引和非主键索引几乎是没有区别的。
InnoDB索引是聚簇索引,不需要回行操作,直接在叶子节点上是所有数据的。磁盘上为两个文件 ,一个存储的是表的结构,一个存的是索引和数据文件。
InnoDB的主键索引带所有数据,非主键索引只携带主键元素的数据。是为了保持数据的一致性,非主键索引只保证主键维护完成既可以存储了。而且InnoDB必须有主键ID,而且建议使用数字自增的。原因就是我们数字方便比较大小,UUID不好比较大小,而且比较占用空间(16K,用多少,少多少)。
那么为什么要自增呢,一句话来说就是紧凑性,现在我们来假想一下,我们去医院看病,病室1,病室2,病室3...病室n,都已经安排满了m个病人,这时来了一个VIP病人,需要在病室7看病,我们首先会把病室7里,取出一个病人来,排列在其它病室,这时我们发现,其它病室也满了,我们就需要重新排列病室和病人的关系(不一定重排所有,但一定需要重排),这一系列的操作,一定会造成时间的浪费。还不如我们后来的人就按照顺序放在最后。也就是我们想要的自增,可以自己去写写B+tree尝试一下。
有时候我们并没有给予InnoDB表给予主键,其实在底层mysql会自动给予InnoDB一个主键的。
联合索引(索引最左前缀原则):
我们再来看一下联合索引,比如我们建立了一个索引A,B,C;我们会优先比较A,A相同,比较B以此类推,所以说,我们会优先比较最开始的那个一个索引,也就是我们的索引最左前缀原则。
多个单列索引在多条件查询时只会生效第一个索引!所以多条件联合查询时最好建联合索引!
最进弄了一个公众号,小菜技术,欢迎大家的加入
